 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Knowledge-Augmented Data in Word Embeddings
Paper and Code
Oct 05, 2020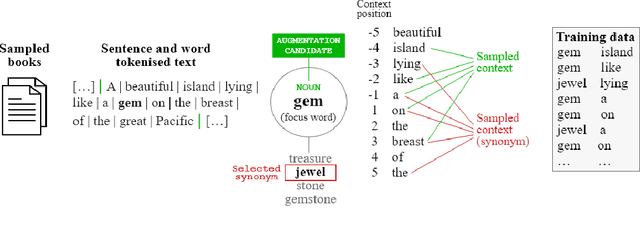

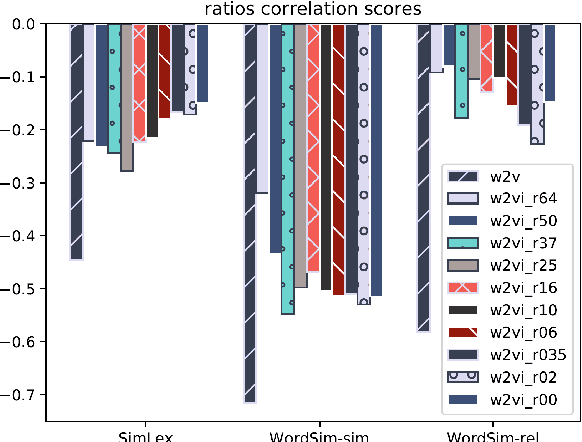
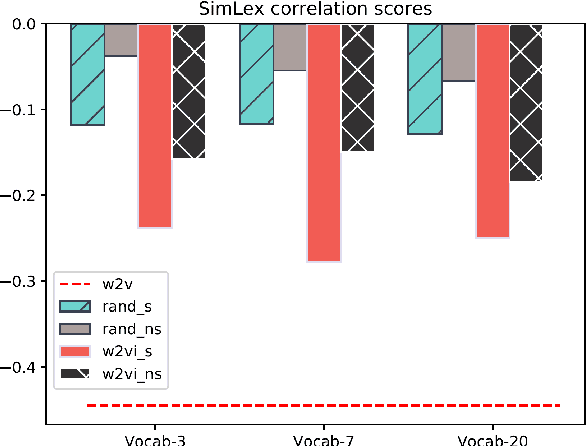
This paper investigates techniques for knowledge injection into word embeddings learned from large corpora of unannotated data. These representations are trained with word cooccurrence statistics and do not commonly exploit syntactic and semantic information from linguistic knowledge bases, which potentially limits their transferability to domains with differing language distributions or usages. We propose a novel approach for linguistic knowledge injection through data augmentation to learn word embeddings that enforce semantic relationships from the data, and systematically evaluate the impact it has on the resulting representations. We show our knowledge augmentation approach improves the intrinsic characteristics of the learned embeddings while not significantly altering their results on a downstream text classification task.