 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Error Alignment for Decision-Making Systems
Sep 20, 2024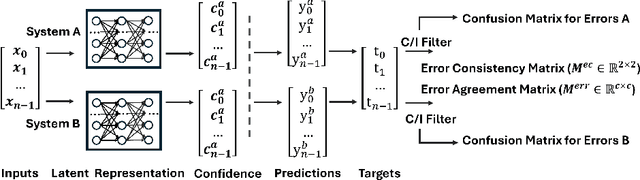



Given that AI systems are set to play a pivotal role in future decision-making processes, their trustworthiness and reliability are of critical concern. Due to their scale and complexity, modern AI systems resist direct interpretation, and alternative ways are needed to establish trust in those systems, and determine how well they align with human values. We argue that good measures of the information processing similarities between AI and humans, may be able to achieve these same ends. While Representational alignment (RA) approaches measure similarity between the internal states of two systems, the associated data can be expensive and difficult to collect for human systems. In contrast, Behavioural alignment (BA) comparisons are cheaper and easier, but questions remain as to their sensitivity and reliability. We propose two new behavioural alignment metrics misclassification agreement which measures the similarity between the errors of two systems on the same instances, and class-level error similarity which measures the similarity between the error distributions of two systems. We show that our metrics correlate well with RA metrics, and provide complementary information to another BA metric, within a range of domains, and set the scene for a new approach to value alignment.
On the Effects of Knowledge-Augmented Data in Word Embeddings
Oct 05, 2020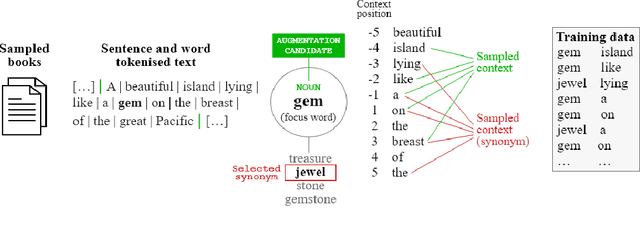

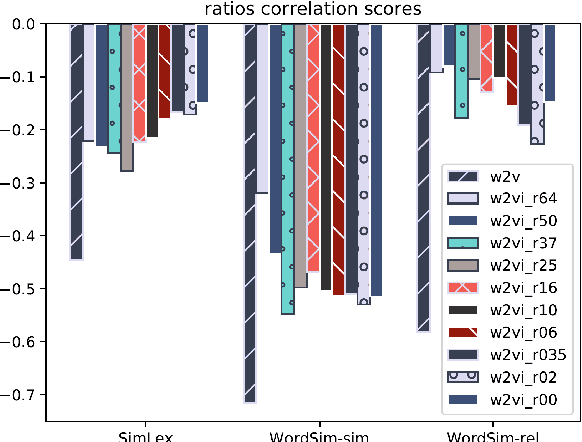
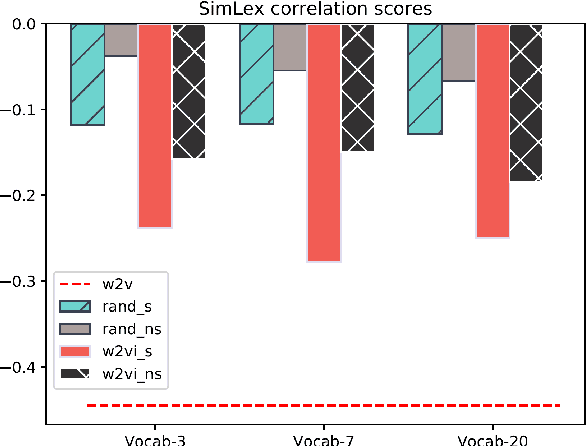
This paper investigates techniques for knowledge injection into word embeddings learned from large corpora of unannotated data. These representations are trained with word cooccurrence statistics and do not commonly exploit syntactic and semantic information from linguistic knowledge bases, which potentially limits their transferability to domains with differing language distributions or usages. We propose a novel approach for linguistic knowledge injection through data augmentation to learn word embeddings that enforce semantic relationships from the data, and systematically evaluate the impact it has on the resulting representations. We show our knowledge augmentation approach improves the intrinsic characteristics of the learned embeddings while not significantly altering their results on a downstream text classification task.