 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Translation of Probabilistic Event Calculus into Markov Decision Processes
Jul 17, 2025
Probabilistic Event Calculus (PEC) is a logical framework for reasoning about actions and their effects in uncertain environments, which enables the representation of probabilistic narratives and computation of temporal projections. The PEC formalism offers significant advantages in interpretability and expressiveness for narrative reasoning. However, it lacks mechanisms for goal-directed reasoning. This paper bridges this gap by developing a formal translation of PEC domains into Markov Decision Processes (MDPs), introducing the concept of "action-taking situations" to preserve PEC's flexible action semantics. The resulting PEC-MDP formalism enables the extensive collection of algorithms and theoretical tools developed for MDPs to be applied to PEC's interpretable narrative domains. We demonstrate how the translation supports both temporal reasoning tasks and objective-driven planning, with methods for mapping learned policies back into human-readable PEC representations, maintaining interpretability while extending PEC's capabilities.
RESPONSE: Benchmarking the Ability of Language Models to Undertake Commonsense Reasoning in Crisis Situation
Mar 14, 2025



An interesting class of commonsense reasoning problems arises when people are faced with natural disasters. To investigate this topic, we present \textsf{RESPONSE}, a human-curated dataset containing 1789 annotated instances featuring 6037 sets of questions designed to assess LLMs' commonsense reasoning in disaster situations across different time frames. The dataset includes problem descriptions, missing resources, time-sensitive solutions, and their justifications, with a subset validated by environmental engineers. Through both automatic metrics and human evaluation, we compare LLM-generated recommendations against human responses. Our findings show that even state-of-the-art models like GPT-4 achieve only 37\% human-evaluated correctness for immediate response actions, highlighting significant room for improvement in LLMs' ability for commonsense reasoning in crises.
Rule-Guided Feedback: Enhancing Reasoning by Enforcing Rule Adherence in Large Language Models
Mar 14, 2025



In this paper, we introduce Rule-Guided Feedback (RGF), a framework designed to enhance Large Language Model (LLM) performance through structured rule adherence and strategic information seeking. RGF implements a teacher-student paradigm where rule-following is forced through established guidelines. Our framework employs a Teacher model that rigorously evaluates each student output against task-specific rules, providing constructive guidance rather than direct answers when detecting deviations. This iterative feedback loop serves two crucial purposes: maintaining solutions within defined constraints and encouraging proactive information seeking to resolve uncertainties. We evaluate RGF on diverse tasks including Checkmate-in-One puzzles, Sonnet Writing, Penguins-In-a-Table classification, GSM8k, and StrategyQA. Our findings suggest that structured feedback mechanisms can significantly enhance LLMs' performance across various domains.
IAO Prompting: Making Knowledge Flow Explicit in LLMs through Structured Reasoning Templates
Feb 05, 2025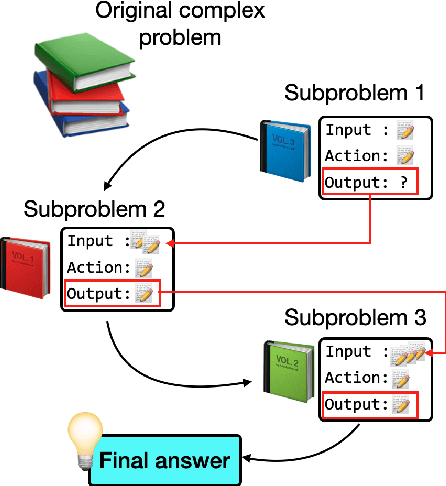



While Large Language Models (LLMs) demonstrate impressive reasoning capabilities, understanding and validating their knowledge utilization remains challenging. Chain-of-thought (CoT) prompting partially addresses this by revealing intermediate reasoning steps, but the knowledge flow and application remain implicit. We introduce IAO (Input-Action-Output) prompting, a structured template-based method that explicitly models how LLMs access and apply their knowledge during complex reasoning tasks. IAO decomposes problems into sequential steps, each clearly identifying the input knowledge being used, the action being performed, and the resulting output. This structured decomposition enables us to trace knowledge flow, verify factual consistency, and identify potential knowledge gaps or misapplications. Through experiments across diverse reasoning tasks, we demonstrate that IAO not only improves zero-shot performance but also provides transparency in how LLMs leverage their stored knowledge. Human evaluation confirms that this structured approach enhances our ability to verify knowledge utilization and detect potential hallucinations or reasoning errors. Our findings provide insights into both knowledge representation within LLMs and methods for more reliable knowledge application.
Neural DNF-MT: A Neuro-symbolic Approach for Learning Interpretable and Editable Policies
Jan 07, 2025Although deep reinforcement learning has been shown to be effective, the model's black-box nature presents barriers to direct policy interpretation. To address this problem, we propose a neuro-symbolic approach called neural DNF-MT for end-to-end policy learning. The differentiable nature of the neural DNF-MT model enables the use of deep actor-critic algorithms for training. At the same time, its architecture is designed so that trained models can be directly translated into interpretable policies expressed as standard (bivalent or probabilistic) logic programs. Moreover, additional layers can be included to extract abstract features from complex observations, acting as a form of predicate invention. The logic representations are highly interpretable, and we show how the bivalent representations of deterministic policies can be edited and incorporated back into a neural model, facilitating manual intervention and adaptation of learned policies. We evaluate our approach on a range of tasks requiring learning deterministic or stochastic behaviours from various forms of observations. Our empirical results show that our neural DNF-MT model performs at the level of competing black-box methods whilst providing interpretable policies.
Measuring Error Alignment for Decision-Making Systems
Sep 20, 2024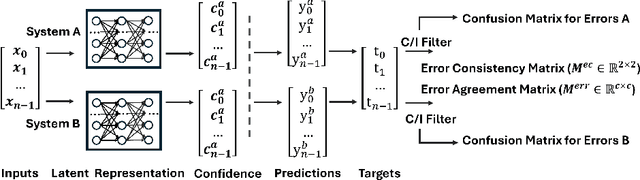



Given that AI systems are set to play a pivotal role in future decision-making processes, their trustworthiness and reliability are of critical concern. Due to their scale and complexity, modern AI systems resist direct interpretation, and alternative ways are needed to establish trust in those systems, and determine how well they align with human values. We argue that good measures of the information processing similarities between AI and humans, may be able to achieve these same ends. While Representational alignment (RA) approaches measure similarity between the internal states of two systems, the associated data can be expensive and difficult to collect for human systems. In contrast, Behavioural alignment (BA) comparisons are cheaper and easier, but questions remain as to their sensitivity and reliability. We propose two new behavioural alignment metrics misclassification agreement which measures the similarity between the errors of two systems on the same instances, and class-level error similarity which measures the similarity between the error distributions of two systems. We show that our metrics correlate well with RA metrics, and provide complementary information to another BA metric, within a range of domains, and set the scene for a new approach to value alignment.
Unsupervised Learning of Graph from Recipes
Jan 22, 2024Cooking recipes are one of the most readily available kinds of procedural text. They consist of natural language instructions that can be challenging to interpret. In this paper, we propose a model to identify relevant information from recipes and generate a graph to represent the sequence of actions in the recipe. In contrast with other approaches, we use an unsupervised approach. We iteratively learn the graph structure and the parameters of a $\mathsf{GNN}$ encoding the texts (text-to-graph) one sequence at a time while providing the supervision by decoding the graph into text (graph-to-text) and comparing the generated text to the input. We evaluate the approach by comparing the identified entities with annotated datasets, comparing the difference between the input and output texts, and comparing our generated graphs with those generated by state of the art methods.
PizzaCommonSense: Learning to Model Commonsense Reasoning about Intermediate Steps in Cooking Recipes
Jan 12, 2024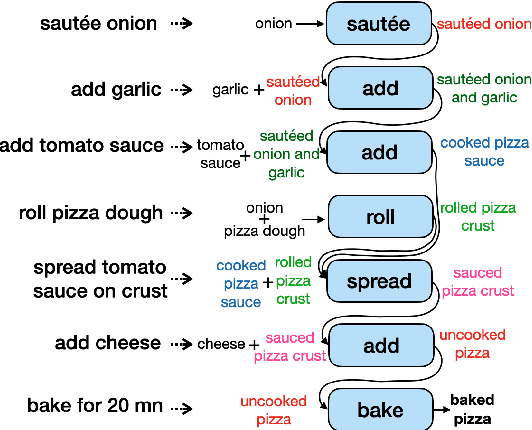
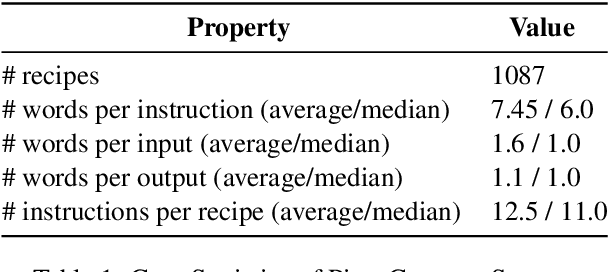
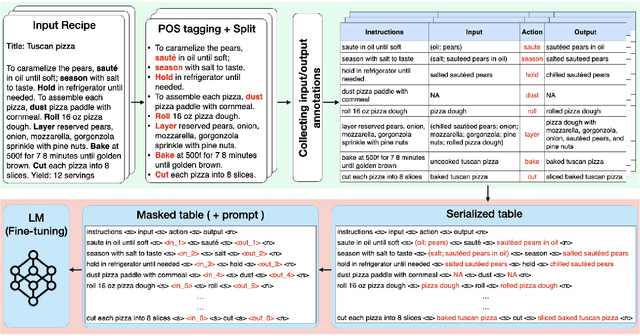

Decoding the core of procedural texts, exemplified by cooking recipes, is crucial for intelligent reasoning and instruction automation. Procedural texts can be comprehensively defined as a sequential chain of steps to accomplish a task employing resources. From a cooking perspective, these instructions can be interpreted as a series of modifications to a food preparation, which initially comprises a set of ingredients. These changes involve transformations of comestible resources. For a model to effectively reason about cooking recipes, it must accurately discern and understand the inputs and outputs of intermediate steps within the recipe. Aiming to address this, we present a new corpus of cooking recipes enriched with descriptions of intermediate steps of the recipes that explicate the input and output for each step. We discuss the data collection process, investigate and provide baseline models based on T5 and GPT-3.5. This work presents a challenging task and insight into commonsense reasoning and procedural text generation.
A Graphical Formalism for Commonsense Reasoning with Recipes
Jun 15, 2023



Whilst cooking is a very important human activity, there has been little consideration given to how we can formalize recipes for use in a reasoning framework. We address this need by proposing a graphical formalization that captures the comestibles (ingredients, intermediate food items, and final products), and the actions on comestibles in the form of a labelled bipartite graph. We then propose formal definitions for comparing recipes, for composing recipes from subrecipes, and for deconstructing recipes into subrecipes. We also introduce and compare two formal definitions for substitution into recipes which are required when there are missing ingredients, or some actions are not possible, or because there is a need to change the final product somehow.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
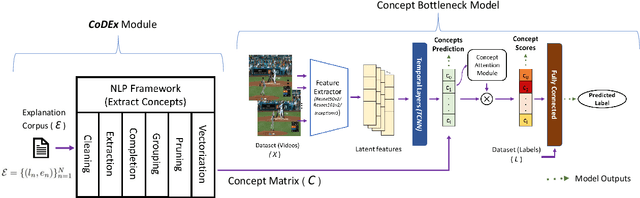
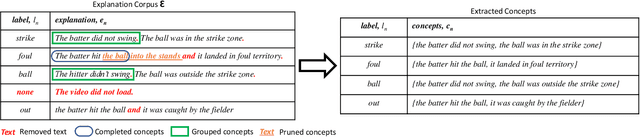

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.