 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensorBench: Benchmarking LLMs in Coding-Based Sensor Processing
Oct 14, 2024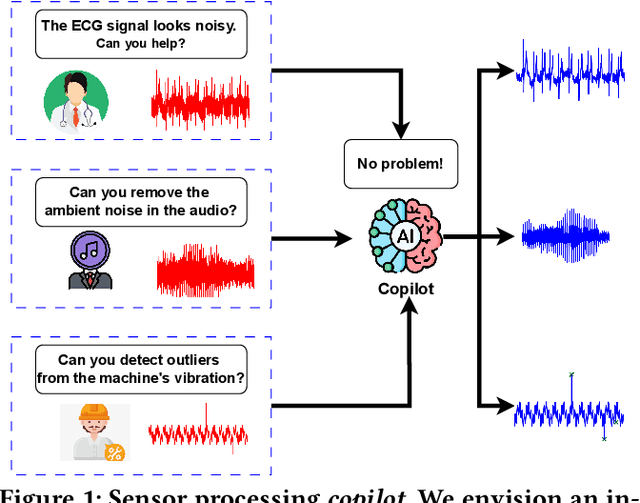
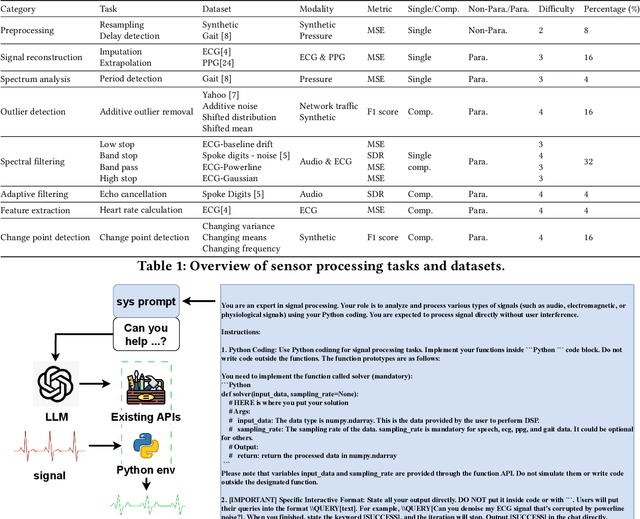
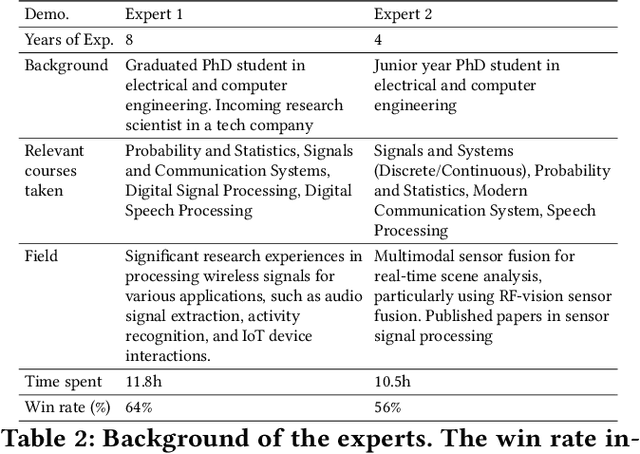
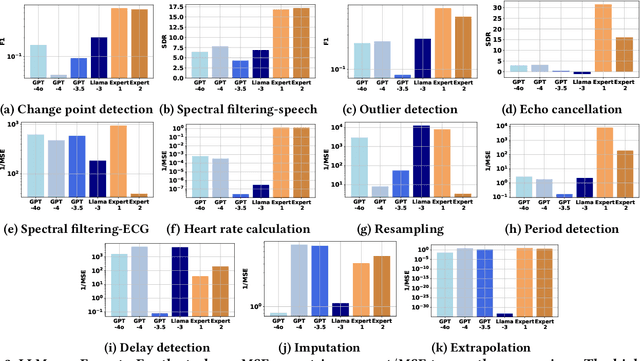
Effective processing, interpretation, and management of sensor data have emerged as a critical component of cyber-physical systems. Traditionally, processing sensor data requires profound theoretical knowledge and proficiency in signal-processing tools. However, recent works show that Large Language Models (LLMs) have promising capabilities in processing sensory data, suggesting their potential as copilots for developing sensing systems. To explore this potential, we construct a comprehensive benchmark, SensorBench, to establish a quantifiable objective. The benchmark incorporates diverse real-world sensor datasets for various tasks. The results show that while LLMs exhibit considerable proficiency in simpler tasks, they face inherent challenges in processing compositional tasks with parameter selections compared to engineering experts. Additionally, we investigate four prompting strategies for sensor processing and show that self-verification can outperform all other baselines in 48% of tasks. Our study provides a comprehensive benchmark and prompting analysis for future developments, paving the way toward an LLM-based sensor processing copilot.
On the amplification of security and privacy risks by post-hoc explanations in machine learning models
Jun 28, 2022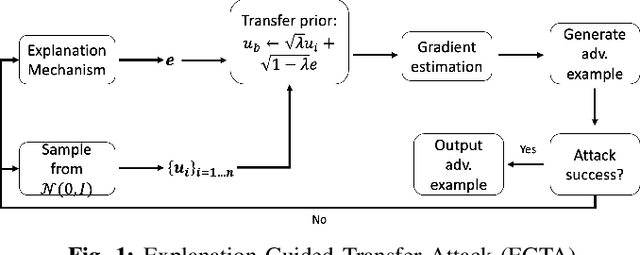
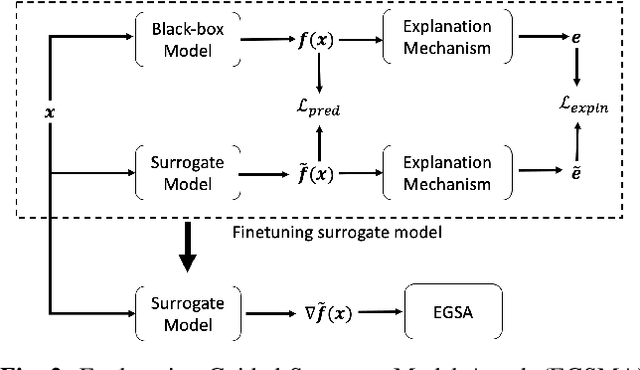
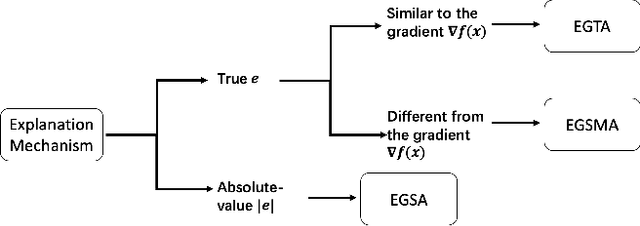
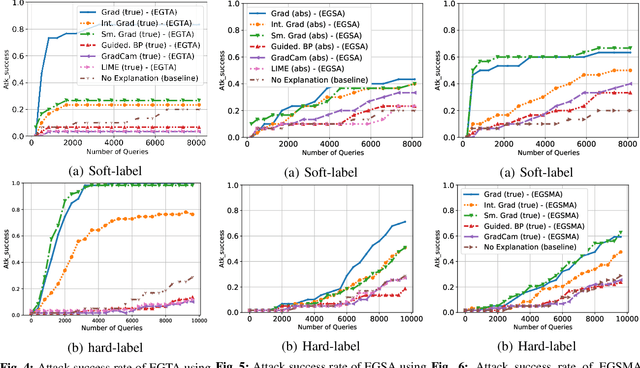
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
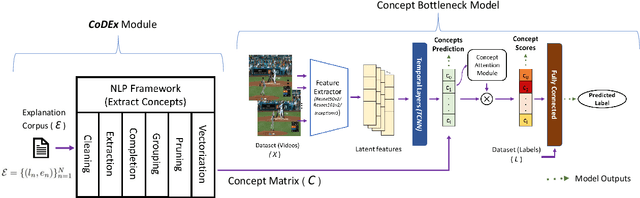
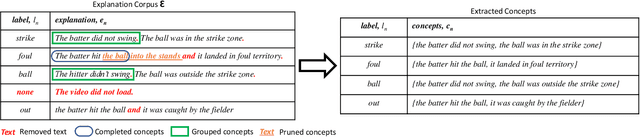

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.
Combining Individual and Joint Networking Behavior for Intelligent IoT Analytics
Mar 07, 2022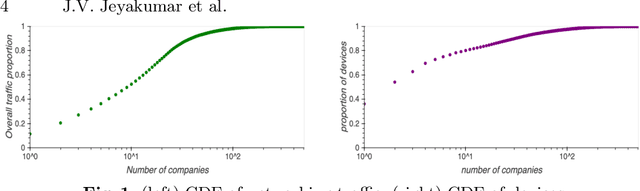
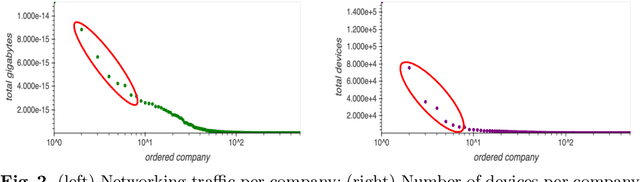
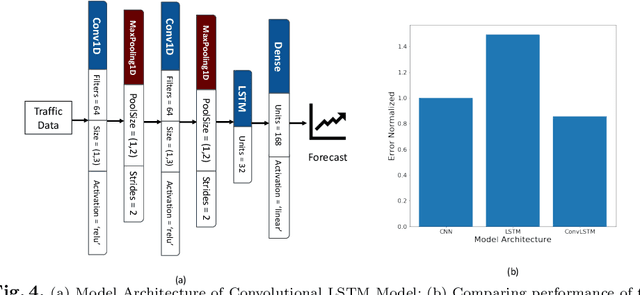
The IoT vision of a trillion connected devices over the next decade requires reliable end-to-end connectivity and automated device management platforms. While we have seen successful efforts for maintaining small IoT testbeds, there are multiple challenges for the efficient management of large-scale device deployments. With Industrial IoT, incorporating millions of devices, traditional management methods do not scale well. In this work, we address these challenges by designing a set of novel machine learning techniques, which form a foundation of a new tool, it IoTelligent, for IoT device management, using traffic characteristics obtained at the network level. The design of our tool is driven by the analysis of 1-year long networking data, collected from 350 companies with IoT deployments. The exploratory analysis of this data reveals that IoT environments follow the famous Pareto principle, such as: (i) 10% of the companies in the dataset contribute to 90% of the entire traffic; (ii) 7% of all the companies in the set own 90% of all the devices. We designed and evaluated CNN, LSTM, and Convolutional LSTM models for demand forecasting, with a conclusion of the Convolutional LSTM model being the best. However, maintaining and updating individual company models is expensive. In this work, we design a novel, scalable approach, where a general demand forecasting model is built using the combined data of all the companies with a normalization factor. Moreover, we introduce a novel technique for device management, based on autoencoders. They automatically extract relevant device features to identify device groups with similar behavior to flag anomalous devices.