 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Foundation Models for Online Complex Event Detection in CPS-IoT: A Case Study
Mar 15, 2025



Complex events (CEs) play a crucial role in CPS-IoT applications, enabling high-level decision-making in domains such as smart monitoring and autonomous systems. However, most existing models focus on short-span perception tasks, lacking the long-term reasoning required for CE detection. CEs consist of sequences of short-time atomic events (AEs) governed by spatiotemporal dependencies. Detecting them is difficult due to long, noisy sensor data and the challenge of filtering out irrelevant AEs while capturing meaningful patterns. This work explores CE detection as a case study for CPS-IoT foundation models capable of long-term reasoning. We evaluate three approaches: (1) leveraging large language models (LLMs), (2) employing various neural architectures that learn CE rules from data, and (3) adopting a neurosymbolic approach that integrates neural models with symbolic engines embedding human knowledge. Our results show that the state-space model, Mamba, which belongs to the second category, outperforms all methods in accuracy and generalization to longer, unseen sensor traces. These findings suggest that state-space models could be a strong backbone for CPS-IoT foundation models for long-span reasoning tasks.
NARCE: A Mamba-Based Neural Algorithmic Reasoner Framework for Online Complex Event Detection
Feb 11, 2025Current machine learning models excel in short-span perception tasks but struggle to derive high-level insights from long-term observation, a capability central to understanding complex events (CEs). CEs, defined as sequences of short-term atomic events (AEs) governed by spatiotemporal rules, are challenging to detect online due to the need to extract meaningful patterns from long and noisy sensor data while ignoring irrelevant events. We hypothesize that state-based methods are well-suited for CE detection, as they capture event progression through state transitions without requiring long-term memory. Baseline experiments validate this, demonstrating that the state-space model Mamba outperforms existing architectures. However, Mamba's reliance on extensive labeled data, which are difficult to obtain, motivates our second hypothesis: decoupling CE rule learning from noisy sensor data can reduce data requirements. To address this, we propose NARCE, a framework that combines Neural Algorithmic Reasoning (NAR) to split the task into two components: (i) learning CE rules independently of sensor data using synthetic concept traces generated by LLMs and (ii) mapping sensor inputs to these rules via an adapter. Our results show that NARCE outperforms baselines in accuracy, generalization to unseen and longer sensor data, and data efficiency, significantly reducing annotation costs while advancing robust CE detection.
ADMN: A Layer-Wise Adaptive Multimodal Network for Dynamic Input Noise and Compute Resources
Feb 11, 2025Multimodal deep learning systems are deployed in dynamic scenarios due to the robustness afforded by multiple sensing modalities. Nevertheless, they struggle with varying compute resource availability (due to multi-tenancy, device heterogeneity, etc.) and fluctuating quality of inputs (from sensor feed corruption, environmental noise, etc.). Current multimodal systems employ static resource provisioning and cannot easily adapt when compute resources change over time. Additionally, their reliance on processing sensor data with fixed feature extractors is ill-equipped to handle variations in modality quality. Consequently, uninformative modalities, such as those with high noise, needlessly consume resources better allocated towards other modalities. We propose ADMN, a layer-wise Adaptive Depth Multimodal Network capable of tackling both challenges - it adjusts the total number of active layers across all modalities to meet compute resource constraints, and continually reallocates layers across input modalities according to their modality quality. Our evaluations showcase ADMN can match the accuracy of state-of-the-art networks while reducing up to 75% of their floating-point operations.
FlexLoc: Conditional Neural Networks for Zero-Shot Sensor Perspective Invariance in Object Localization with Distributed Multimodal Sensors
Jun 10, 2024



Localization is a critical technology for various applications ranging from navigation and surveillance to assisted living. Localization systems typically fuse information from sensors viewing the scene from different perspectives to estimate the target location while also employing multiple modalities for enhanced robustness and accuracy. Recently, such systems have employed end-to-end deep neural models trained on large datasets due to their superior performance and ability to handle data from diverse sensor modalities. However, such neural models are often trained on data collected from a particular set of sensor poses (i.e., locations and orientations). During real-world deployments, slight deviations from these sensor poses can result in extreme inaccuracies. To address this challenge, we introduce FlexLoc, which employs conditional neural networks to inject node perspective information to adapt the localization pipeline. Specifically, a small subset of model weights are derived from node poses at run time, enabling accurate generalization to unseen perspectives with minimal additional overhead. Our evaluations on a multimodal, multiview indoor tracking dataset showcase that FlexLoc improves the localization accuracy by almost 50% in the zero-shot case (no calibration data available) compared to the baselines. The source code of FlexLoc is available at https://github.com/nesl/FlexLoc.
Realistic Scatterer Based Adversarial Attacks on SAR Image Classifiers
Dec 05, 2023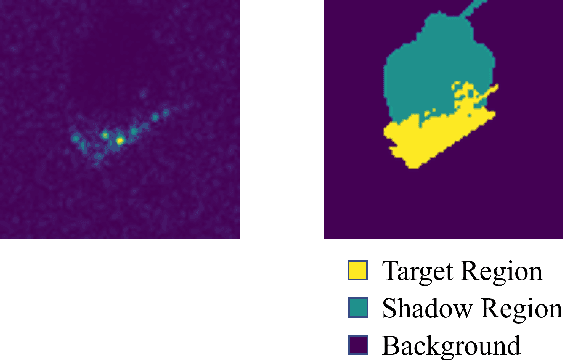

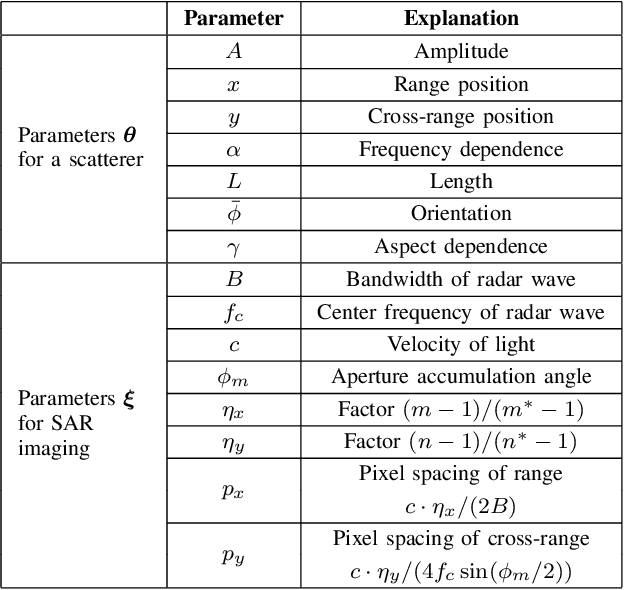
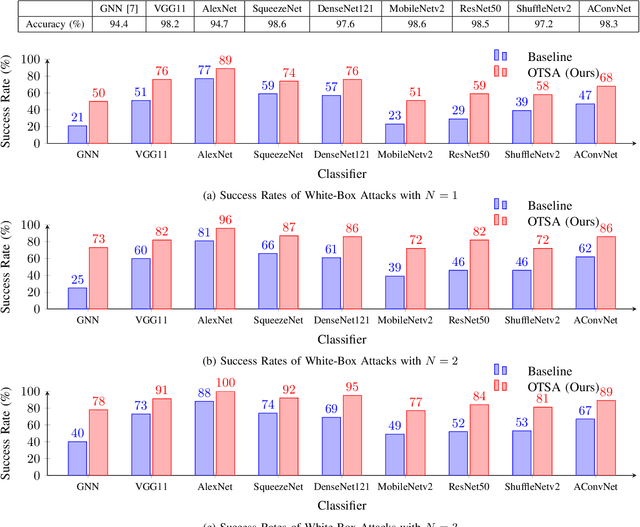
Adversarial attacks have highlighted the vulnerability of classifiers based on machine learning for Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR) tasks. An adversarial attack perturbs SAR images of on-ground targets such that the classifiers are misled into making incorrect predictions. However, many existing attacking techniques rely on arbitrary manipulation of SAR images while overlooking the feasibility of executing the attacks on real-world SAR imagery. Instead, adversarial attacks should be able to be implemented by physical actions, for example, placing additional false objects as scatterers around the on-ground target to perturb the SAR image and fool the SAR ATR. In this paper, we propose the On-Target Scatterer Attack (OTSA), a scatterer-based physical adversarial attack. To ensure the feasibility of its physical execution, we enforce a constraint on the positioning of the scatterers. Specifically, we restrict the scatterers to be placed only on the target instead of in the shadow regions or the background. To achieve this, we introduce a positioning score based on Gaussian kernels and formulate an optimization problem for our OTSA attack. Using a gradient ascent method to solve the optimization problem, the OTSA can generate a vector of parameters describing the positions, shapes, sizes and amplitudes of the scatterers to guide the physical execution of the attack that will mislead SAR image classifiers. The experimental results show that our attack obtains significantly higher success rates under the positioning constraint compared with the existing method.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
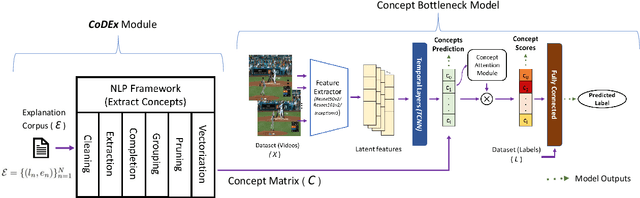
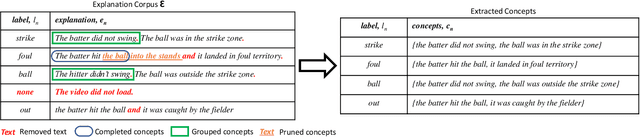

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.
Using DeepProbLog to perform Complex Event Processing on an Audio Stream
Oct 15, 2021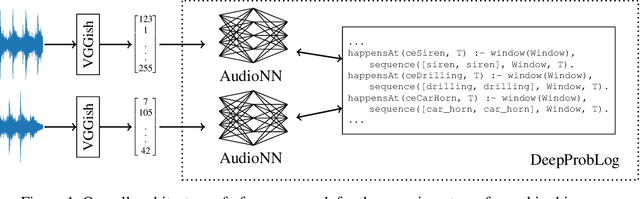
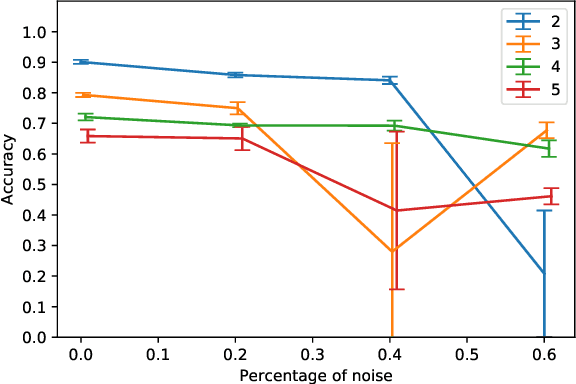
In this paper, we present an approach to Complex Event Processing (CEP) that is based on DeepProbLog. This approach has the following objectives: (i) allowing the use of subsymbolic data as an input, (ii) retaining the flexibility and modularity on the definitions of complex event rules, (iii) allowing the system to be trained in an end-to-end manner and (iv) being robust against noisily labelled data. Our approach makes use of DeepProbLog to create a neuro-symbolic architecture that combines a neural network to process the subsymbolic data with a probabilistic logic layer to allow the user to define the rules for the complex events. We demonstrate that our approach is capable of detecting complex events from an audio stream. We also demonstrate that our approach is capable of training even with a dataset that has a moderate proportion of noisy data.
NSL: Hybrid Interpretable Learning From Noisy Raw Data
Dec 09, 2020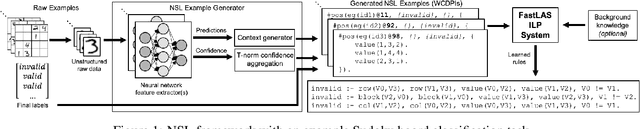
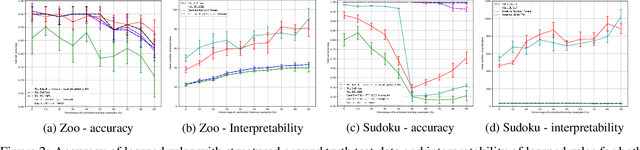
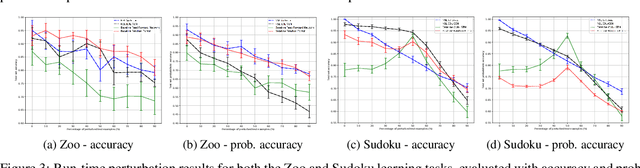
Inductive Logic Programming (ILP) systems learn generalised, interpretable rules in a data-efficient manner utilising existing background knowledge. However, current ILP systems require training examples to be specified in a structured logical format. Neural networks learn from unstructured data, although their learned models may be difficult to interpret and are vulnerable to data perturbations at run-time. This paper introduces a hybrid neural-symbolic learning framework, called NSL, that learns interpretable rules from labelled unstructured data. NSL combines pre-trained neural networks for feature extraction with FastLAS, a state-of-the-art ILP system for rule learning under the answer set semantics. Features extracted by the neural components define the structured context of labelled examples and the confidence of the neural predictions determines the level of noise of the examples. Using the scoring function of FastLAS, NSL searches for short, interpretable rules that generalise over such noisy examples. We evaluate our framework on propositional and first-order classification tasks using the MNIST dataset as raw data. Specifically, we demonstrate that NSL is able to learn robust rules from perturbed MNIST data and achieve comparable or superior accuracy when compared to neural network and random forest baselines whilst being more general and interpretable.
A General Framework for Distributed Inference with Uncertain Models
Nov 20, 2020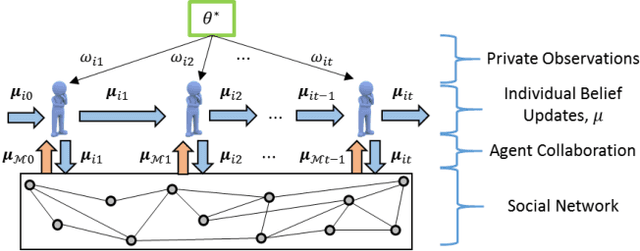
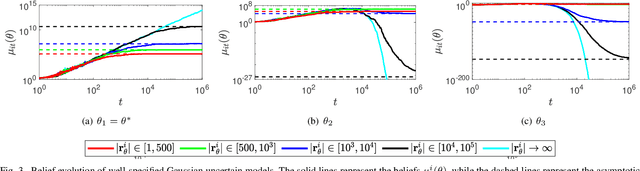
This paper studies the problem of distributed classification with a network of heterogeneous agents. The agents seek to jointly identify the underlying target class that best describes a sequence of observations. The problem is first abstracted to a hypothesis-testing framework, where we assume that the agents seek to agree on the hypothesis (target class) that best matches the distribution of observations. Non-Bayesian social learning theory provides a framework that solves this problem in an efficient manner by allowing the agents to sequentially communicate and update their beliefs for each hypothesis over the network. Most existing approaches assume that agents have access to exact statistical models for each hypothesis. However, in many practical applications, agents learn the likelihood models based on limited data, which induces uncertainty in the likelihood function parameters. In this work, we build upon the concept of uncertain models to incorporate the agents' uncertainty in the likelihoods by identifying a broad set of parametric distribution that allows the agents' beliefs to converge to the same result as a centralized approach. Furthermore, we empirically explore extensions to non-parametric models to provide a generalized framework of uncertain models in non-Bayesian social learning.
A Hybrid Neuro-Symbolic Approach for Complex Event Processing
Sep 18, 2020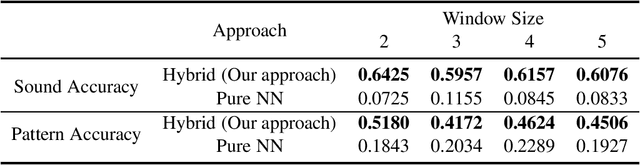
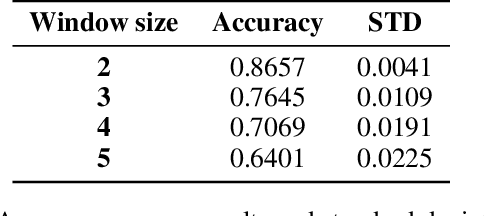
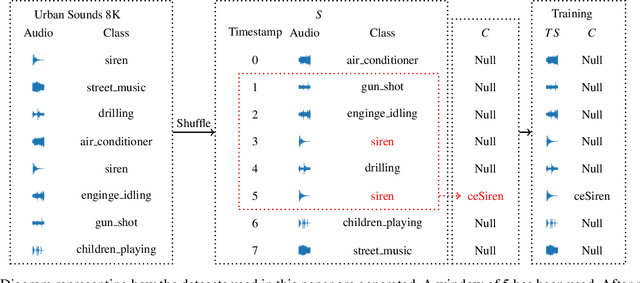
Training a model to detect patterns of interrelated events that form situations of interest can be a complex problem: such situations tend to be uncommon, and only sparse data is available. We propose a hybrid neuro-symbolic architecture based on Event Calculus that can perform Complex Event Processing (CEP). It leverages both a neural network to interpret inputs and logical rules that express the pattern of the complex event. Our approach is capable of training with much fewer labelled data than a pure neural network approach, and to learn to classify individual events even when training in an end-to-end manner. We demonstrate this comparing our approach against a pure neural network approach on a dataset based on Urban Sounds 8K.