 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Explanation-Related Interactions in Collaborative Perception-Cognition-Communication-Action
Nov 19, 2024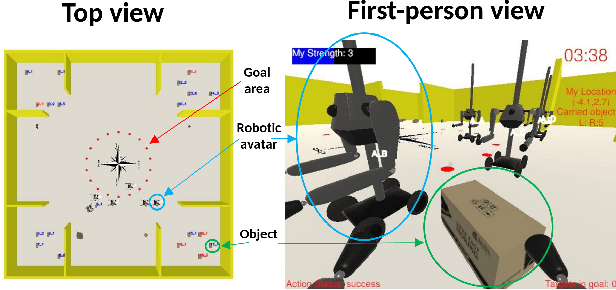
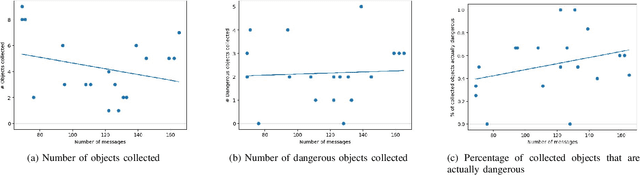
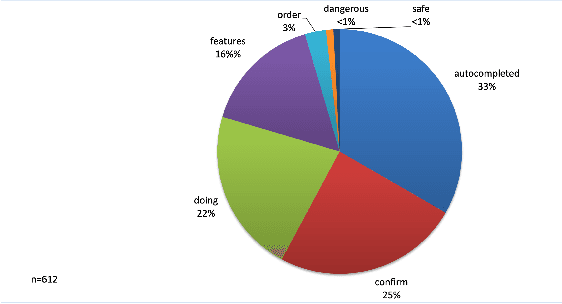

Effective communication is essential in collaborative tasks, so AI-equipped robots working alongside humans need to be able to explain their behaviour in order to cooperate effectively and earn trust. We analyse and classify communications among human participants collaborating to complete a simulated emergency response task. The analysis identifies messages that relate to various kinds of interactive explanations identified in the explainable AI literature. This allows us to understand what type of explanations humans expect from their teammates in such settings, and thus where AI-equipped robots most need explanation capabilities. We find that most explanation-related messages seek clarification in the decisions or actions taken. We also confirm that messages have an impact on the performance of our simulated task.
* 4 pages, 3 figures, published as a Late Breaking Report in RO-MAN 2024
Vector Symbolic Open Source Information Discovery
Aug 20, 2024Combined, joint, intra-governmental, inter-agency and multinational (CJIIM) operations require rapid data sharing without the bottlenecks of metadata curation and alignment. Curation and alignment is particularly infeasible for external open source information (OSINF), e.g., social media, which has become increasingly valuable in understanding unfolding situations. Large language models (transformers) facilitate semantic data and metadata alignment but are inefficient in CJIIM settings characterised as denied, degraded, intermittent and low bandwidth (DDIL). Vector symbolic architectures (VSA) support semantic information processing using highly compact binary vectors, typically 1-10k bits, suitable in a DDIL setting. We demonstrate a novel integration of transformer models with VSA, combining the power of the former for semantic matching with the compactness and representational structure of the latter. The approach is illustrated via a proof-of-concept OSINF data discovery portal that allows partners in a CJIIM operation to share data sources with minimal metadata curation and low communications bandwidth. This work was carried out as a bridge between previous low technology readiness level (TRL) research and future higher-TRL technology demonstration and deployment.
Can we Constrain Concept Bottleneck Models to Learn Semantically Meaningful Input Features?
Feb 01, 2024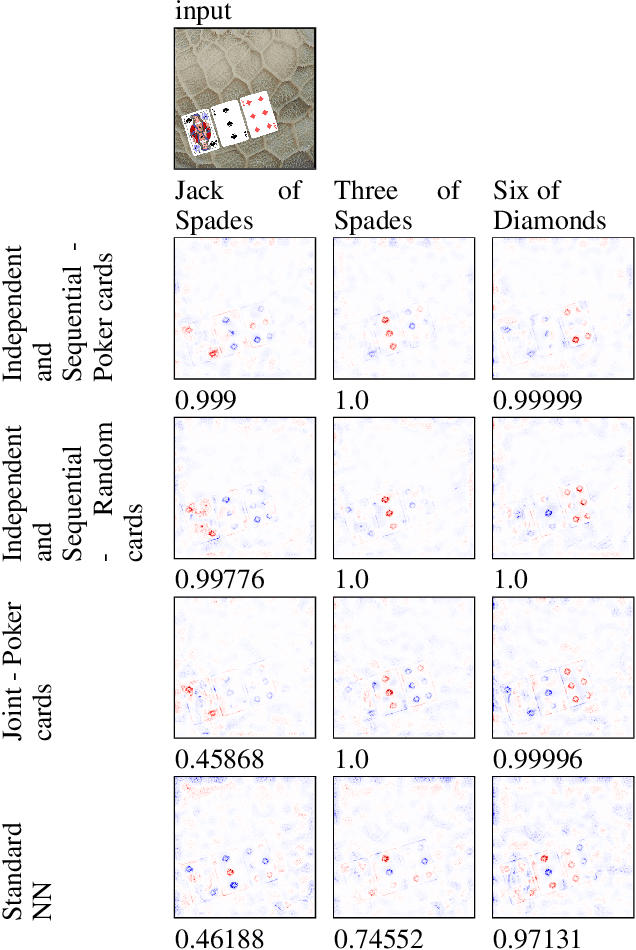

Concept Bottleneck Models (CBMs) are considered inherently interpretable because they first predict a set of human-defined concepts before using these concepts to predict the output of a downstream task. For inherent interpretability to be fully realised, and ensure trust in a model's output, we need to guarantee concepts are predicted based on semantically mapped input features. For example, one might expect the pixels representing a broken bone in an image to be used for the prediction of a fracture. However, current literature indicates this is not the case, as concept predictions are often mapped to irrelevant input features. We hypothesise that this occurs when concept annotations are inaccurate or how input features should relate to concepts is unclear. In general, the effect of dataset labelling on concept representations in CBMs remains an understudied area. Therefore, in this paper, we examine how CBMs learn concepts from datasets with fine-grained concept annotations. We demonstrate that CBMs can learn concept representations with semantic mapping to input features by removing problematic concept correlations, such as two concepts always appearing together. To support our evaluation, we introduce a new synthetic image dataset based on a playing cards domain, which we hope will serve as a benchmark for future CBM research. For validation, we provide empirical evidence on a real-world dataset of chest X-rays, to demonstrate semantically meaningful concepts can be learned in real-world applications.
Towards a Deeper Understanding of Concept Bottleneck Models Through End-to-End Explanation
Feb 07, 2023Concept Bottleneck Models (CBMs) first map raw input(s) to a vector of human-defined concepts, before using this vector to predict a final classification. We might therefore expect CBMs capable of predicting concepts based on distinct regions of an input. In doing so, this would support human interpretation when generating explanations of the model's outputs to visualise input features corresponding to concepts. The contribution of this paper is threefold: Firstly, we expand on existing literature by looking at relevance both from the input to the concept vector, confirming that relevance is distributed among the input features, and from the concept vector to the final classification where, for the most part, the final classification is made using concepts predicted as present. Secondly, we report a quantitative evaluation to measure the distance between the maximum input feature relevance and the ground truth location; we perform this with the techniques, Layer-wise Relevance Propagation (LRP), Integrated Gradients (IG) and a baseline gradient approach, finding LRP has a lower average distance than IG. Thirdly, we propose using the proportion of relevance as a measurement for explaining concept importance.
Politics and Virality in the Time of Twitter: A Large-Scale Cross-Party Sentiment Analysis in Greece, Spain and United Kingdom
Feb 01, 2022

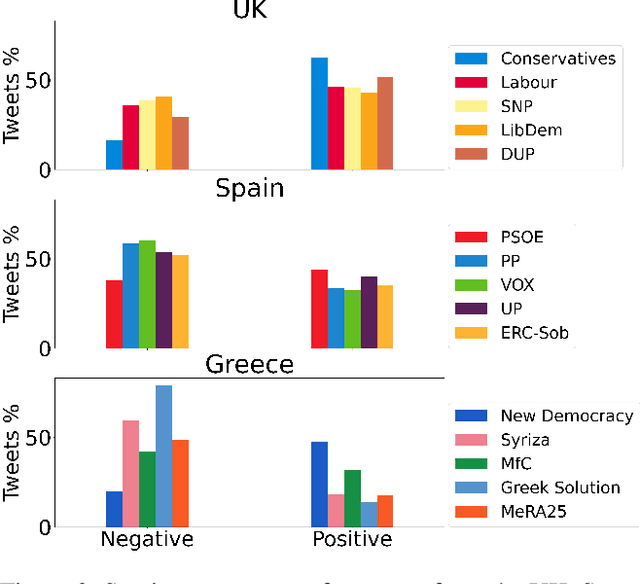
Social media has become extremely influential when it comes to policy making in modern societies especially in the western world (e.g., 48% of Europeans use social media every day or almost every day). Platforms such as Twitter allow users to follow politicians, thus making citizens more involved in political discussion. In the same vein, politicians use Twitter to express their opinions, debate among others on current topics and promote their political agenda aiming to influence voter behaviour. Previous studies have shown that tweets conveying negative sentiment are likely to be retweeted more frequently. In this paper, we attempt to analyse tweets from politicians from different countries and explore if their tweets follow the same trend. Utilising state-of-the-art pre-trained language models we performed sentiment analysis on multilingual tweets collected from members of parliament of Greece, Spain and United Kingdom, including devolved administrations. We achieved this by systematically exploring and analysing the differences between influential and less popular tweets. Our analysis indicates that politicians' negatively charged tweets spread more widely, especially in more recent times, and highlights interesting trends in the intersection of sentiment and popularity.
AAAI FSS-21: Artificial Intelligence in Government and Public Sector Proceedings
Dec 10, 2021Proceedings of the AAAI Fall Symposium on Artificial Intelligence in Government and Public Sector, Washington, DC, USA, November 4-6, 2021
Guiding Generative Language Models for Data Augmentation in Few-Shot Text Classification
Nov 17, 2021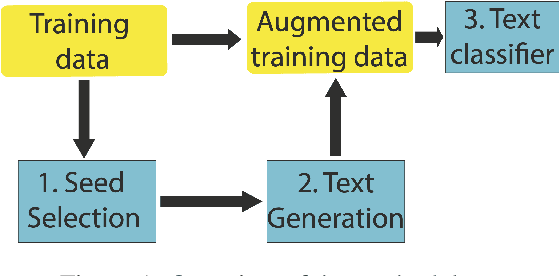
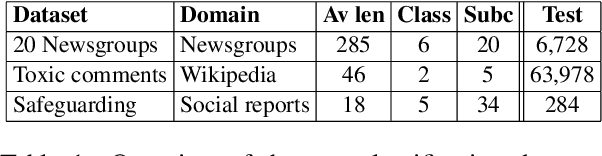
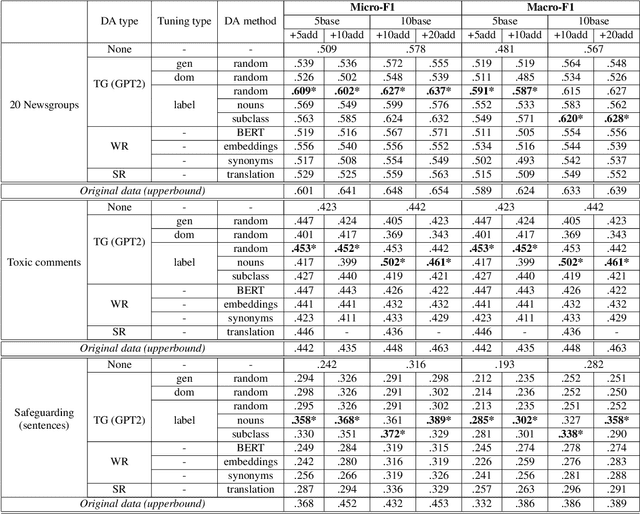
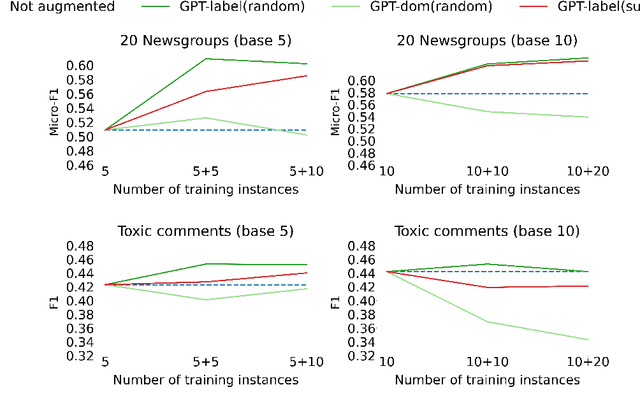
Data augmentation techniques are widely used for enhancing the performance of machine learning models by tackling class imbalance issues and data sparsity. State-of-the-art generative language models have been shown to provide significant gains across different NLP tasks. However, their applicability to data augmentation for text classification tasks in few-shot settings have not been fully explored, especially for specialised domains. In this paper, we leverage GPT-2 (Radford A et al, 2019) for generating artificial training instances in order to improve classification performance. Our aim is to analyse the impact the selection process of seed training examples have over the quality of GPT-generated samples and consequently the classifier performance. We perform experiments with several seed selection strategies that, among others, exploit class hierarchical structures and domain expert selection. Our results show that fine-tuning GPT-2 in a handful of label instances leads to consistent classification improvements and outperform competitive baselines. Finally, we show that guiding this process through domain expert selection can lead to further improvements, which opens up interesting research avenues for combining generative models and active learning.
Using DeepProbLog to perform Complex Event Processing on an Audio Stream
Oct 15, 2021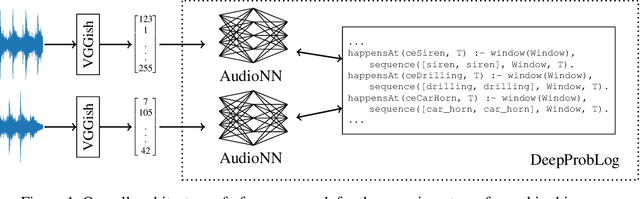
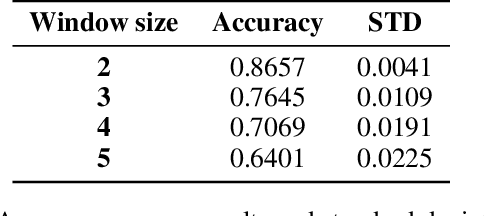
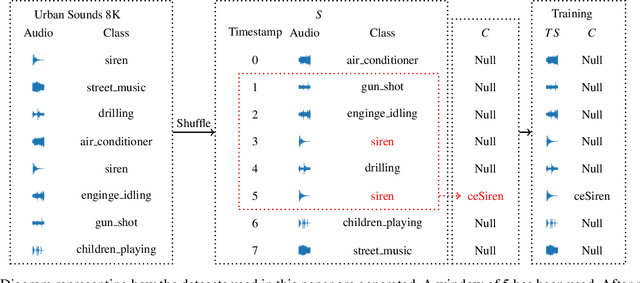
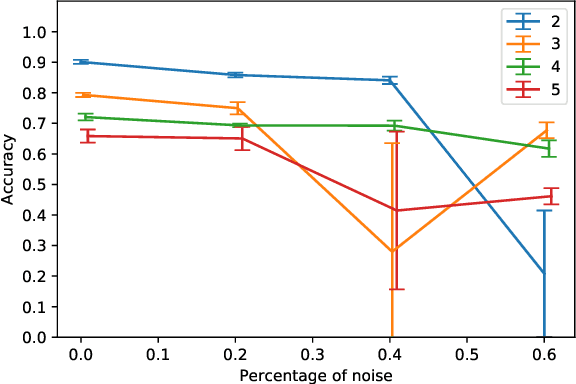
In this paper, we present an approach to Complex Event Processing (CEP) that is based on DeepProbLog. This approach has the following objectives: (i) allowing the use of subsymbolic data as an input, (ii) retaining the flexibility and modularity on the definitions of complex event rules, (iii) allowing the system to be trained in an end-to-end manner and (iv) being robust against noisily labelled data. Our approach makes use of DeepProbLog to create a neuro-symbolic architecture that combines a neural network to process the subsymbolic data with a probabilistic logic layer to allow the user to define the rules for the complex events. We demonstrate that our approach is capable of detecting complex events from an audio stream. We also demonstrate that our approach is capable of training even with a dataset that has a moderate proportion of noisy data.
Deriving Disinformation Insights from Geolocalized Twitter Callouts
Aug 06, 2021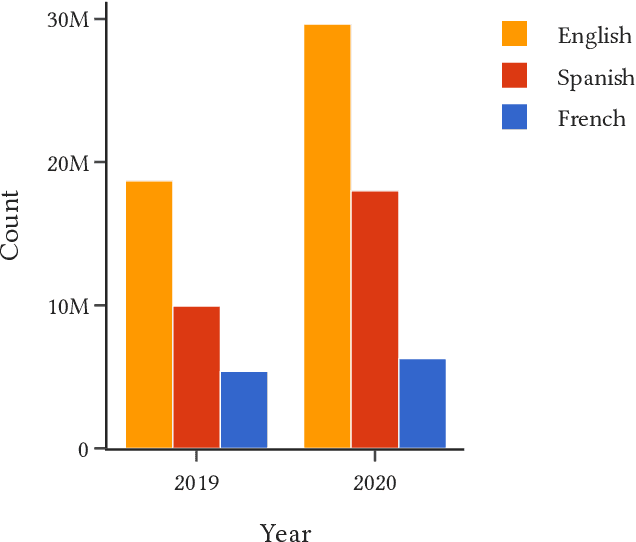

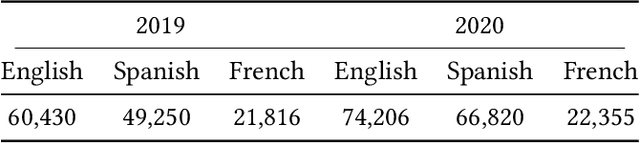
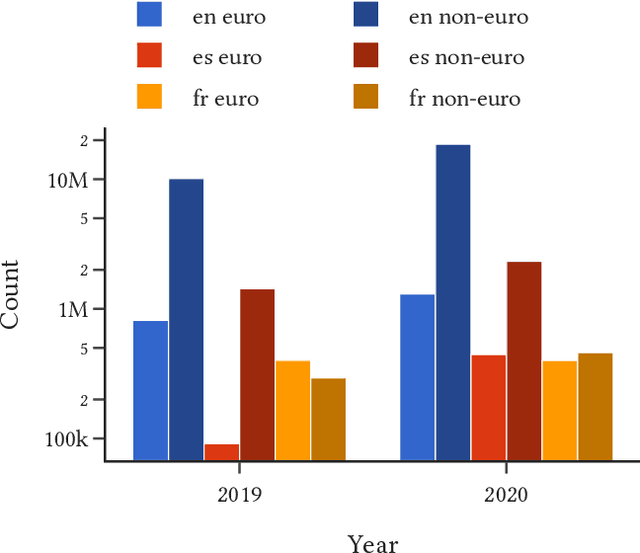
This paper demonstrates a two-stage method for deriving insights from social media data relating to disinformation by applying a combination of geospatial classification and embedding-based language modelling across multiple languages. In particular, the analysis in centered on Twitter and disinformation for three European languages: English, French and Spanish. Firstly, Twitter data is classified into European and non-European sets using BERT. Secondly, Word2vec is applied to the classified texts resulting in Eurocentric, non-Eurocentric and global representations of the data for the three target languages. This comparative analysis demonstrates not only the efficacy of the classification method but also highlights geographic, temporal and linguistic differences in the disinformation-related media. Thus, the contributions of the work are threefold: (i) a novel language-independent transformer-based geolocation method; (ii) an analytical approach that exploits lexical specificity and word embeddings to interrogate user-generated content; and (iii) a dataset of 36 million disinformation related tweets in English, French and Spanish.
Providing Assurance and Scrutability on Shared Data and Machine Learning Models with Verifiable Credentials
May 13, 2021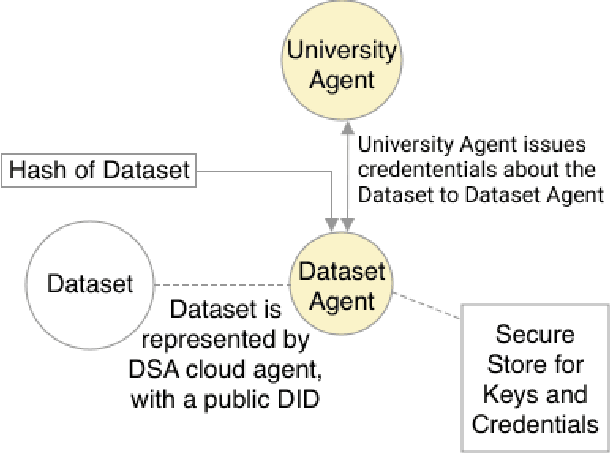
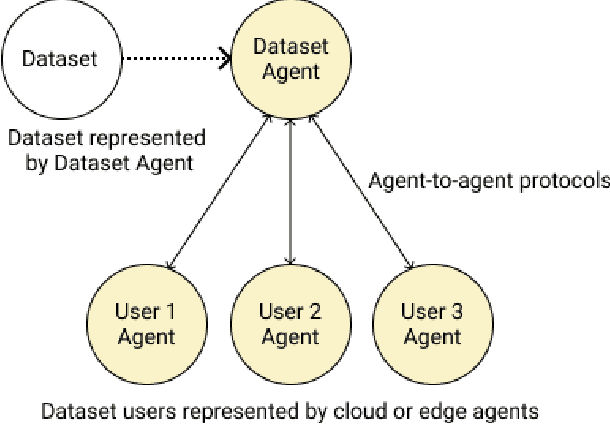
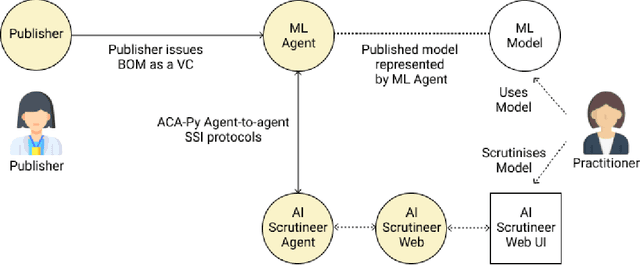
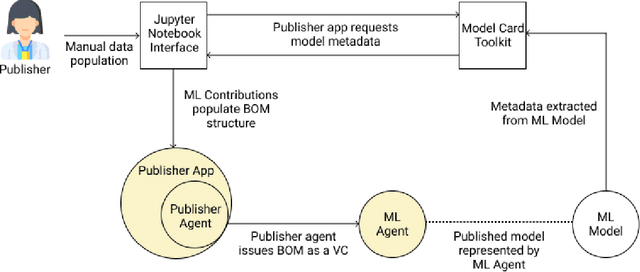
Adopting shared data resources requires scientists to place trust in the originators of the data. When shared data is later used in the development of artificial intelligence (AI) systems or machine learning (ML) models, the trust lineage extends to the users of the system, typically practitioners in fields such as healthcare and finance. Practitioners rely on AI developers to have used relevant, trustworthy data, but may have limited insight and recourse. This paper introduces a software architecture and implementation of a system based on design patterns from the field of self-sovereign identity. Scientists can issue signed credentials attesting to qualities of their data resources. Data contributions to ML models are recorded in a bill of materials (BOM), which is stored with the model as a verifiable credential. The BOM provides a traceable record of the supply chain for an AI system, which facilitates on-going scrutiny of the qualities of the contributing components. The verified BOM, and its linkage to certified data qualities, is used in the AI Scrutineer, a web-based tool designed to offer practitioners insight into ML model constituents and highlight any problems with adopted datasets, should they be found to have biased data or be otherwise discredited.