 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models for Text Classification: Is In-Context Learning Enough?
Mar 26, 2024



Recent foundational language models have shown state-of-the-art performance in many NLP tasks in zero- and few-shot settings. An advantage of these models over more standard approaches based on fine-tuning is the ability to understand instructions written in natural language (prompts), which helps them generalise better to different tasks and domains without the need for specific training data. This makes them suitable for addressing text classification problems for domains with limited amounts of annotated instances. However, existing research is limited in scale and lacks understanding of how text generation models combined with prompting techniques compare to more established methods for text classification such as fine-tuning masked language models. In this paper, we address this research gap by performing a large-scale evaluation study for 16 text classification datasets covering binary, multiclass, and multilabel problems. In particular, we compare zero- and few-shot approaches of large language models to fine-tuning smaller language models. We also analyse the results by prompt, classification type, domain, and number of labels. In general, the results show how fine-tuning smaller and more efficient language models can still outperform few-shot approaches of larger language models, which have room for improvement when it comes to text classification.
Guiding Generative Language Models for Data Augmentation in Few-Shot Text Classification
Nov 17, 2021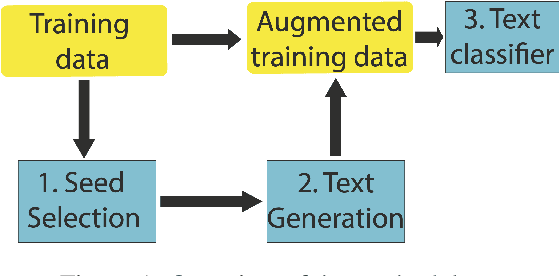
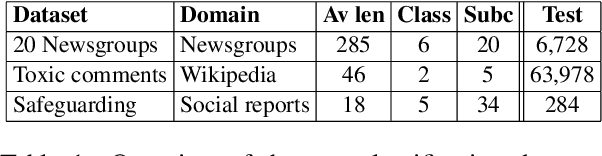
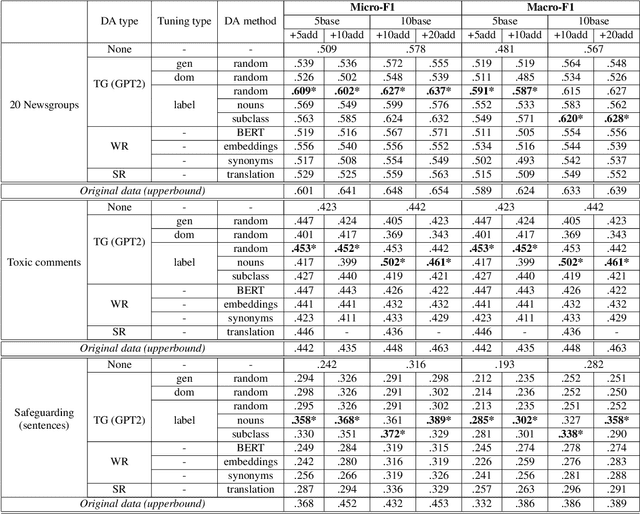
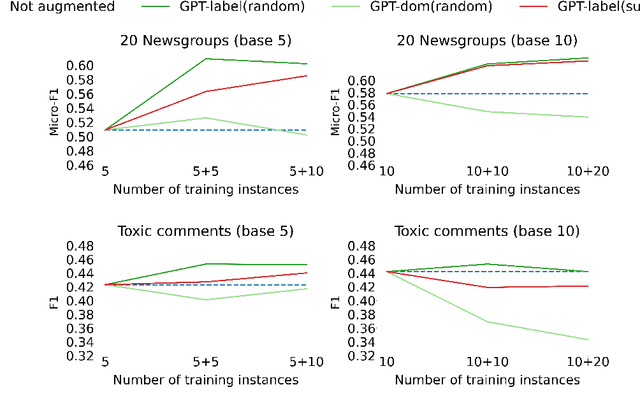
Data augmentation techniques are widely used for enhancing the performance of machine learning models by tackling class imbalance issues and data sparsity. State-of-the-art generative language models have been shown to provide significant gains across different NLP tasks. However, their applicability to data augmentation for text classification tasks in few-shot settings have not been fully explored, especially for specialised domains. In this paper, we leverage GPT-2 (Radford A et al, 2019) for generating artificial training instances in order to improve classification performance. Our aim is to analyse the impact the selection process of seed training examples have over the quality of GPT-generated samples and consequently the classifier performance. We perform experiments with several seed selection strategies that, among others, exploit class hierarchical structures and domain expert selection. Our results show that fine-tuning GPT-2 in a handful of label instances leads to consistent classification improvements and outperform competitive baselines. Finally, we show that guiding this process through domain expert selection can lead to further improvements, which opens up interesting research avenues for combining generative models and active learning.
Predicting Themes within Complex Unstructured Texts: A Case Study on Safeguarding Reports
Oct 29, 2020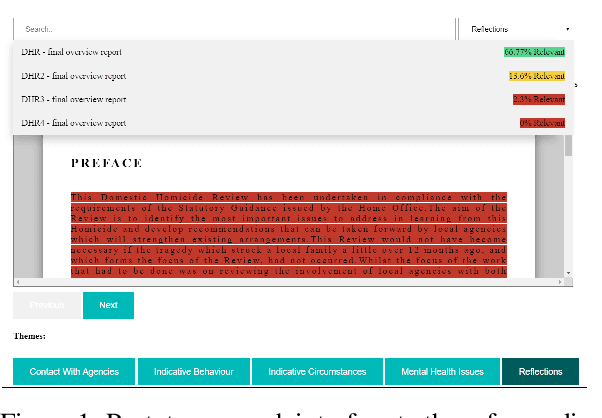
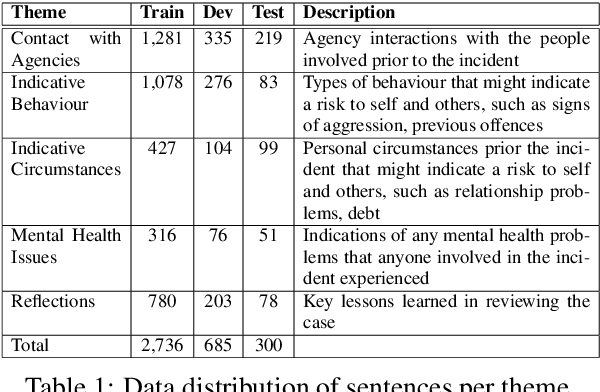
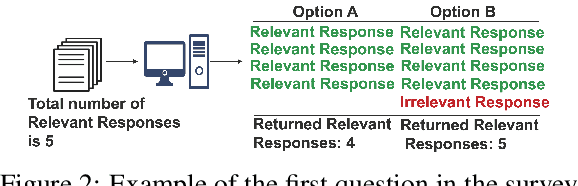
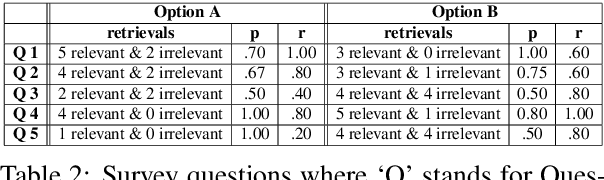
The task of text and sentence classification is associated with the need for large amounts of labelled training data. The acquisition of high volumes of labelled datasets can be expensive or unfeasible, especially for highly-specialised domains for which documents are hard to obtain. Research on the application of supervised classification based on small amounts of training data is limited. In this paper, we address the combination of state-of-the-art deep learning and classification methods and provide an insight into what combination of methods fit the needs of small, domain-specific, and terminologically-rich corpora. We focus on a real-world scenario related to a collection of safeguarding reports comprising learning experiences and reflections on tackling serious incidents involving children and vulnerable adults. The relatively small volume of available reports and their use of highly domain-specific terminology makes the application of automated approaches difficult. We focus on the problem of automatically identifying the main themes in a safeguarding report using supervised classification approaches. Our results show the potential of deep learning models to simulate subject-expert behaviour even for complex tasks with limited labelled data.