 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Themes within Complex Unstructured Texts: A Case Study on Safeguarding Reports
Paper and Code
Oct 29, 2020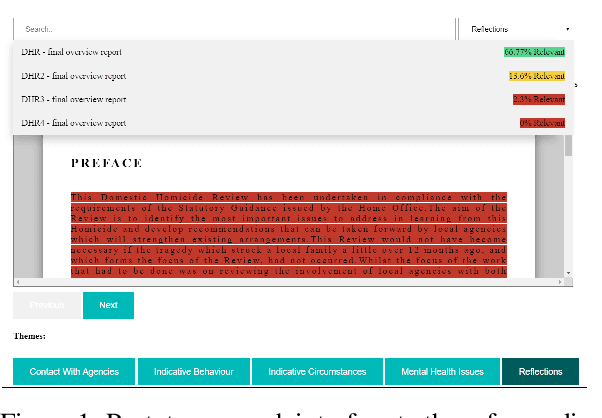
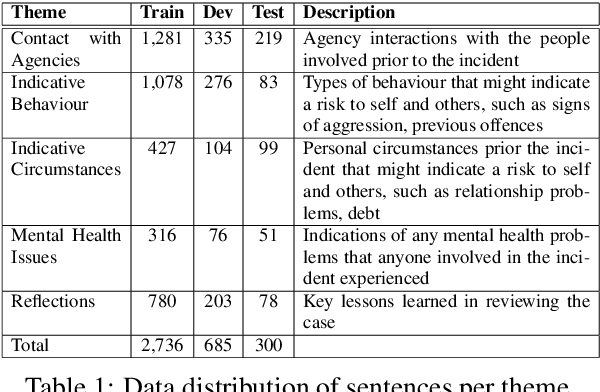
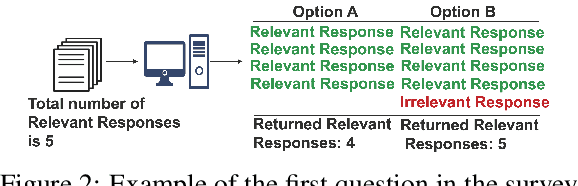
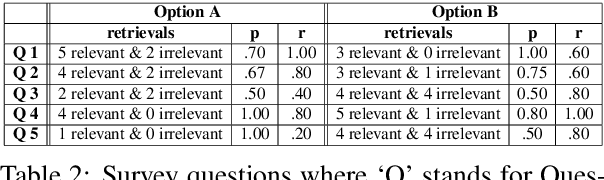
The task of text and sentence classification is associated with the need for large amounts of labelled training data. The acquisition of high volumes of labelled datasets can be expensive or unfeasible, especially for highly-specialised domains for which documents are hard to obtain. Research on the application of supervised classification based on small amounts of training data is limited. In this paper, we address the combination of state-of-the-art deep learning and classification methods and provide an insight into what combination of methods fit the needs of small, domain-specific, and terminologically-rich corpora. We focus on a real-world scenario related to a collection of safeguarding reports comprising learning experiences and reflections on tackling serious incidents involving children and vulnerable adults. The relatively small volume of available reports and their use of highly domain-specific terminology makes the application of automated approaches difficult. We focus on the problem of automatically identifying the main themes in a safeguarding report using supervised classification approaches. Our results show the potential of deep learning models to simulate subject-expert behaviour even for complex tasks with limited labelled data.