 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs
Apr 23, 2026LLMs have been showing limitations when it comes to cultural coverage and competence, and in some cases show regional biases such as amplifying Western and Anglocentric viewpoints. While there have been works analysing the cultural capabilities of LLMs, there has not been specific work on highlighting LLM regional preferences when it comes to cultural-related questions. In this work, we propose a new dataset based on a comprehensive taxonomy of Culture-Related Open Questions (CROQ). The results show that, contrary to previous cultural bias work, LLMs show a clear tendency towards countries such as Japan. Moveover, our results show that when prompting in languages such as English or other high-resource ones, LLMs tend to provide more diverse outputs and show less inclinations towards answering questions highlighting countries for which the input language is an official language. Finally, we also investigate at which point of LLM training this cultural bias emerges, with our results suggesting that the first clear signs appear after supervised fine-tuning, and not during pre-training.
Understanding LLM Performance Degradation in Multi-Instance Processing: The Roles of Instance Count and Context Length
Mar 23, 2026Users often rely on Large Language Models (LLMs) for processing multiple documents or performing analysis over a number of instances. For example, analysing the overall sentiment of a number of movie reviews requires an LLM to process the sentiment of each review individually in order to provide a final aggregated answer. While LLM performance on such individual tasks is generally high, there has been little research on how LLMs perform when dealing with multi-instance inputs. In this paper, we perform a comprehensive evaluation of the multi-instance processing (MIP) ability of LLMs for tasks in which they excel individually. The results show that all LLMs follow a pattern of slight performance degradation for small numbers of instances (approximately 20-100), followed by a performance collapse on larger instance counts. Crucially, our analysis shows that while context length is associated with this degradation, the number of instances has a stronger effect on the final results. This finding suggests that when optimising LLM performance for MIP, attention should be paid to both context length and, in particular, instance count.
Exploring State Tracking Capabilities of Large Language Models
Nov 13, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in solving complex tasks, including those requiring a certain level of reasoning. In this paper, we focus on state tracking, a problem where models need to keep track of the state governing a number of entities. To isolate the state tracking component from other factors, we propose a benchmark based on three well-defined state tracking tasks and analyse the performance of LLMs in different scenarios. The results indicate that the recent generation of LLMs (specifically, GPT-4 and Llama3) are capable of tracking state, especially when integrated with mechanisms such as Chain of Thought. However, models from the former generation, while understanding the task and being able to solve it at the initial stages, often fail at this task after a certain number of steps.
MORABLES: A Benchmark for Assessing Abstract Moral Reasoning in LLMs with Fables
Sep 15, 2025As LLMs excel on standard reading comprehension benchmarks, attention is shifting toward evaluating their capacity for complex abstract reasoning and inference. Literature-based benchmarks, with their rich narrative and moral depth, provide a compelling framework for evaluating such deeper comprehension skills. Here, we present MORABLES, a human-verified benchmark built from fables and short stories drawn from historical literature. The main task is structured as multiple-choice questions targeting moral inference, with carefully crafted distractors that challenge models to go beyond shallow, extractive question answering. To further stress-test model robustness, we introduce adversarial variants designed to surface LLM vulnerabilities and shortcuts due to issues such as data contamination. Our findings show that, while larger models outperform smaller ones, they remain susceptible to adversarial manipulation and often rely on superficial patterns rather than true moral reasoning. This brittleness results in significant self-contradiction, with the best models refuting their own answers in roughly 20% of cases depending on the framing of the moral choice. Interestingly, reasoning-enhanced models fail to bridge this gap, suggesting that scale - not reasoning ability - is the primary driver of performance.
Automatic Extraction of Metaphoric Analogies from Literary Texts: Task Formulation, Dataset Construction, and Evaluation
Dec 19, 2024



Extracting metaphors and analogies from free text requires high-level reasoning abilities such as abstraction and language understanding. Our study focuses on the extraction of the concepts that form metaphoric analogies in literary texts. To this end, we construct a novel dataset in this domain with the help of domain experts. We compare the out-of-the-box ability of recent large language models (LLMs) to structure metaphoric mappings from fragments of texts containing proportional analogies. The models are further evaluated on the generation of implicit elements of the analogy, which are indirectly suggested in the texts and inferred by human readers. The competitive results obtained by LLMs in our experiments are encouraging and open up new avenues such as automatically extracting analogies and metaphors from text instead of investing resources in domain experts to manually label data.
Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
Nov 29, 2024



The detection of sensitive content in large datasets is crucial for ensuring that shared and analysed data is free from harmful material. However, current moderation tools, such as external APIs, suffer from limitations in customisation, accuracy across diverse sensitive categories, and privacy concerns. Additionally, existing datasets and open-source models focus predominantly on toxic language, leaving gaps in detecting other sensitive categories such as substance abuse or self-harm. In this paper, we put forward a unified dataset tailored for social media content moderation across six sensitive categories: conflictual language, profanity, sexually explicit material, drug-related content, self-harm, and spam. By collecting and annotating data with consistent retrieval strategies and guidelines, we address the shortcomings of previous focalised research. Our analysis demonstrates that fine-tuning large language models (LLMs) on this novel dataset yields significant improvements in detection performance compared to open off-the-shelf models such as LLaMA, and even proprietary OpenAI models, which underperform by 10-15% overall. This limitation is even more pronounced on popular moderation APIs, which cannot be easily tailored to specific sensitive content categories, among others.
MetaphorShare: A Dynamic Collaborative Repository of Open Metaphor Datasets
Nov 27, 2024

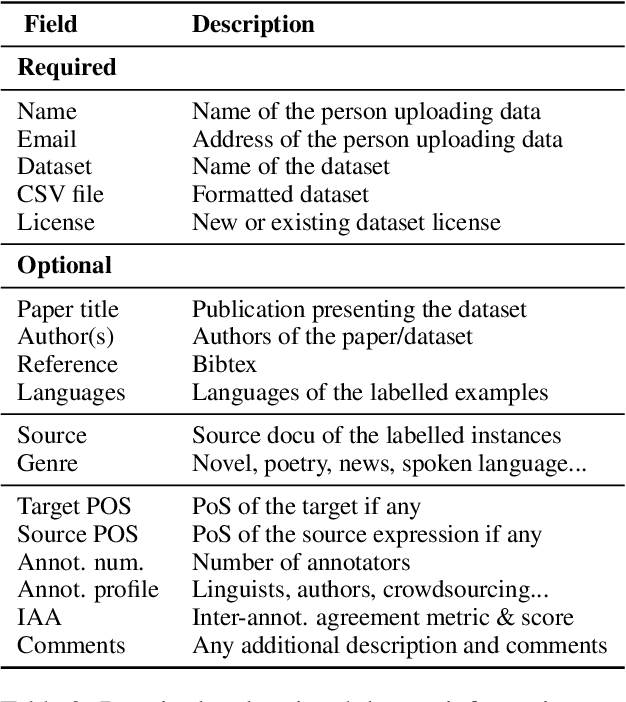

The metaphor studies community has developed numerous valuable labelled corpora in various languages over the years. Many of these resources are not only unknown to the NLP community, but are also often not easily shared among the researchers. Both in human sciences and in NLP, researchers could benefit from a centralised database of labelled resources, easily accessible and unified under an identical format. To facilitate this, we present MetaphorShare, a website to integrate metaphor datasets making them open and accessible. With this effort, our aim is to encourage researchers to share and upload more datasets in any language in order to facilitate metaphor studies and the development of future metaphor processing NLP systems. The website is accessible at www.metaphorshare.com.
Multilingual Topic Classification in X: Dataset and Analysis
Oct 04, 2024



In the dynamic realm of social media, diverse topics are discussed daily, transcending linguistic boundaries. However, the complexities of understanding and categorising this content across various languages remain an important challenge with traditional techniques like topic modelling often struggling to accommodate this multilingual diversity. In this paper, we introduce X-Topic, a multilingual dataset featuring content in four distinct languages (English, Spanish, Japanese, and Greek), crafted for the purpose of tweet topic classification. Our dataset includes a wide range of topics, tailored for social media content, making it a valuable resource for scientists and professionals working on cross-linguistic analysis, the development of robust multilingual models, and computational scientists studying online dialogue. Finally, we leverage X-Topic to perform a comprehensive cross-linguistic and multilingual analysis, and compare the capabilities of current general- and domain-specific language models.
Analysing Zero-Shot Readability-Controlled Sentence Simplification
Sep 30, 2024



Readability-controlled text simplification (RCTS) rewrites texts to lower readability levels while preserving their meaning. RCTS models often depend on parallel corpora with readability annotations on both source and target sides. Such datasets are scarce and difficult to curate, especially at the sentence level. To reduce reliance on parallel data, we explore using instruction-tuned large language models for zero-shot RCTS. Through automatic and manual evaluations, we examine: (1) how different types of contextual information affect a model's ability to generate sentences with the desired readability, and (2) the trade-off between achieving target readability and preserving meaning. Results show that all tested models struggle to simplify sentences (especially to the lowest levels) due to models' limitations and characteristics of the source sentences that impede adequate rewriting. Our experiments also highlight the need for better automatic evaluation metrics tailored to RCTS, as standard ones often misinterpret common simplification operations, and inaccurately assess readability and meaning preservation.
Evaluating Short-Term Temporal Fluctuations of Social Biases in Social Media Data and Masked Language Models
Jun 19, 2024



Social biases such as gender or racial biases have been reported in language models (LMs), including Masked Language Models (MLMs). Given that MLMs are continuously trained with increasing amounts of additional data collected over time, an important yet unanswered question is how the social biases encoded with MLMs vary over time. In particular, the number of social media users continues to grow at an exponential rate, and it is a valid concern for the MLMs trained specifically on social media data whether their social biases (if any) would also amplify over time. To empirically analyse this problem, we use a series of MLMs pretrained on chronologically ordered temporal snapshots of corpora. Our analysis reveals that, although social biases are present in all MLMs, most types of social bias remain relatively stable over time (with a few exceptions). To further understand the mechanisms that influence social biases in MLMs, we analyse the temporal corpora used to train the MLMs. Our findings show that some demographic groups, such as male, obtain higher preference over the other, such as female on the training corpora constantly.