 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Item Tokenization for Generative Recommendation through Self-Improvement
Dec 22, 2024



Generative recommendation systems, driven by large language models (LLMs), present an innovative approach to predicting user preferences by modeling items as token sequences and generating recommendations in a generative manner. A critical challenge in this approach is the effective tokenization of items, ensuring that they are represented in a form compatible with LLMs. Current item tokenization methods include using text descriptions, numerical strings, or sequences of discrete tokens. While text-based representations integrate seamlessly with LLM tokenization, they are often too lengthy, leading to inefficiencies and complicating accurate generation. Numerical strings, while concise, lack semantic depth and fail to capture meaningful item relationships. Tokenizing items as sequences of newly defined tokens has gained traction, but it often requires external models or algorithms for token assignment. These external processes may not align with the LLM's internal pretrained tokenization schema, leading to inconsistencies and reduced model performance. To address these limitations, we propose a self-improving item tokenization method that allows the LLM to refine its own item tokenizations during training process. Our approach starts with item tokenizations generated by any external model and periodically adjusts these tokenizations based on the LLM's learned patterns. Such alignment process ensures consistency between the tokenization and the LLM's internal understanding of the items, leading to more accurate recommendations. Furthermore, our method is simple to implement and can be integrated as a plug-and-play enhancement into existing generative recommendation systems. Experimental results on multiple datasets and using various initial tokenization strategies demonstrate the effectiveness of our method, with an average improvement of 8\% in recommendation performance.
Automatic Extraction of Metaphoric Analogies from Literary Texts: Task Formulation, Dataset Construction, and Evaluation
Dec 19, 2024



Extracting metaphors and analogies from free text requires high-level reasoning abilities such as abstraction and language understanding. Our study focuses on the extraction of the concepts that form metaphoric analogies in literary texts. To this end, we construct a novel dataset in this domain with the help of domain experts. We compare the out-of-the-box ability of recent large language models (LLMs) to structure metaphoric mappings from fragments of texts containing proportional analogies. The models are further evaluated on the generation of implicit elements of the analogy, which are indirectly suggested in the texts and inferred by human readers. The competitive results obtained by LLMs in our experiments are encouraging and open up new avenues such as automatically extracting analogies and metaphors from text instead of investing resources in domain experts to manually label data.
Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
Nov 29, 2024



The detection of sensitive content in large datasets is crucial for ensuring that shared and analysed data is free from harmful material. However, current moderation tools, such as external APIs, suffer from limitations in customisation, accuracy across diverse sensitive categories, and privacy concerns. Additionally, existing datasets and open-source models focus predominantly on toxic language, leaving gaps in detecting other sensitive categories such as substance abuse or self-harm. In this paper, we put forward a unified dataset tailored for social media content moderation across six sensitive categories: conflictual language, profanity, sexually explicit material, drug-related content, self-harm, and spam. By collecting and annotating data with consistent retrieval strategies and guidelines, we address the shortcomings of previous focalised research. Our analysis demonstrates that fine-tuning large language models (LLMs) on this novel dataset yields significant improvements in detection performance compared to open off-the-shelf models such as LLaMA, and even proprietary OpenAI models, which underperform by 10-15% overall. This limitation is even more pronounced on popular moderation APIs, which cannot be easily tailored to specific sensitive content categories, among others.
Multilingual Topic Classification in X: Dataset and Analysis
Oct 04, 2024



In the dynamic realm of social media, diverse topics are discussed daily, transcending linguistic boundaries. However, the complexities of understanding and categorising this content across various languages remain an important challenge with traditional techniques like topic modelling often struggling to accommodate this multilingual diversity. In this paper, we introduce X-Topic, a multilingual dataset featuring content in four distinct languages (English, Spanish, Japanese, and Greek), crafted for the purpose of tweet topic classification. Our dataset includes a wide range of topics, tailored for social media content, making it a valuable resource for scientists and professionals working on cross-linguistic analysis, the development of robust multilingual models, and computational scientists studying online dialogue. Finally, we leverage X-Topic to perform a comprehensive cross-linguistic and multilingual analysis, and compare the capabilities of current general- and domain-specific language models.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024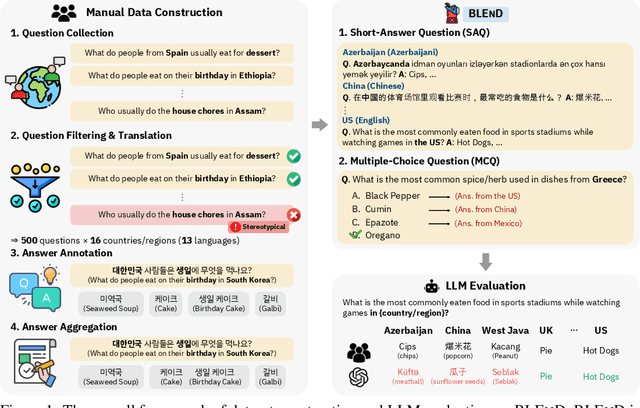
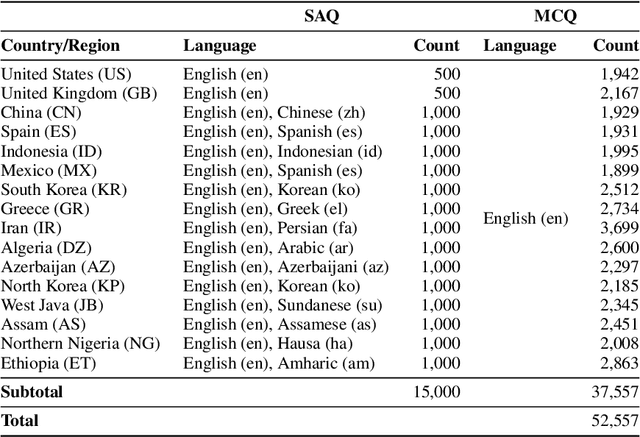
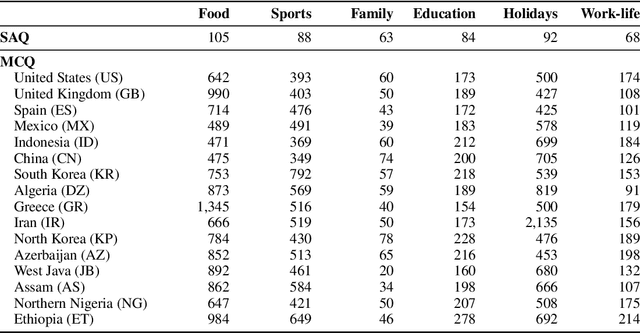
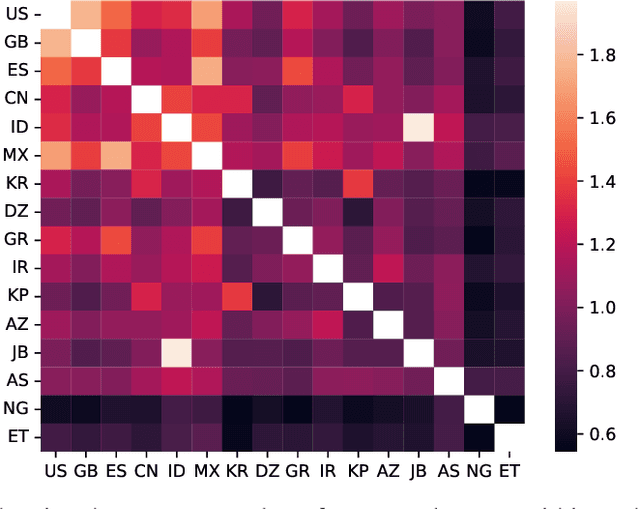
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
Words as Trigger Points in Social Media Discussions
May 16, 2024



Trigger points are a concept introduced by Mau, Lux, and Westheuser (2023) to study qualitative focus group interviews and understand polarisation in Germany. When people communicate, trigger points represent moments when individuals feel that their understanding of what is fair, normal, or appropriate in society is questioned. In the original studies, individuals react affectively to such triggers and show strong and negative emotional responses. In this paper, we introduce the first systematic study of the large-scale effect of individual words as trigger points by analysing a large amount of social media posts. We examine online deliberations on Reddit between 2020 and 2022 and collect >100 million posts from subreddits related to a set of words identified as trigger points in UK politics. We find that such trigger words affect user engagement and have noticeable consequences on animosity in online discussions. We share empirical evidence of trigger words causing animosity, and how they provide incentives for hate speech, adversarial debates, and disagreements. Our work is the first to introduce trigger points to computational studies of online communication. Our findings are relevant to researchers interested in online harms and who examine how citizens debate politics and society in light of affective polarisation.
SuperTweetEval: A Challenging, Unified and Heterogeneous Benchmark for Social Media NLP Research
Oct 23, 2023


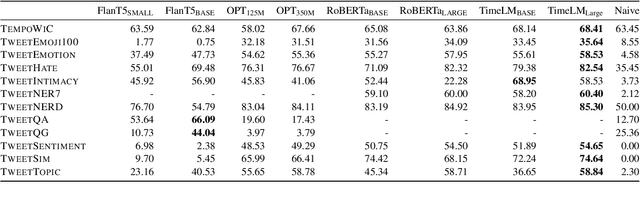
Despite its relevance, the maturity of NLP for social media pales in comparison with general-purpose models, metrics and benchmarks. This fragmented landscape makes it hard for the community to know, for instance, given a task, which is the best performing model and how it compares with others. To alleviate this issue, we introduce a unified benchmark for NLP evaluation in social media, SuperTweetEval, which includes a heterogeneous set of tasks and datasets combined, adapted and constructed from scratch. We benchmarked the performance of a wide range of models on SuperTweetEval and our results suggest that, despite the recent advances in language modelling, social media remains challenging.
Robust Hate Speech Detection in Social Media: A Cross-Dataset Empirical Evaluation
Jul 04, 2023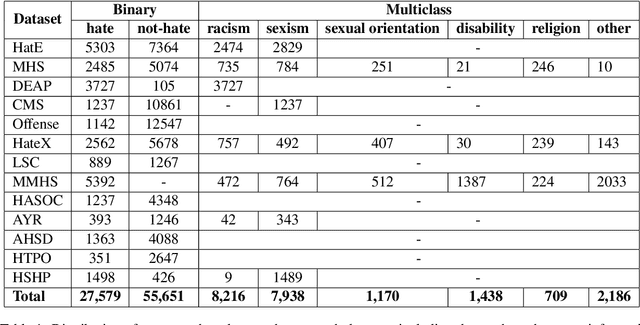
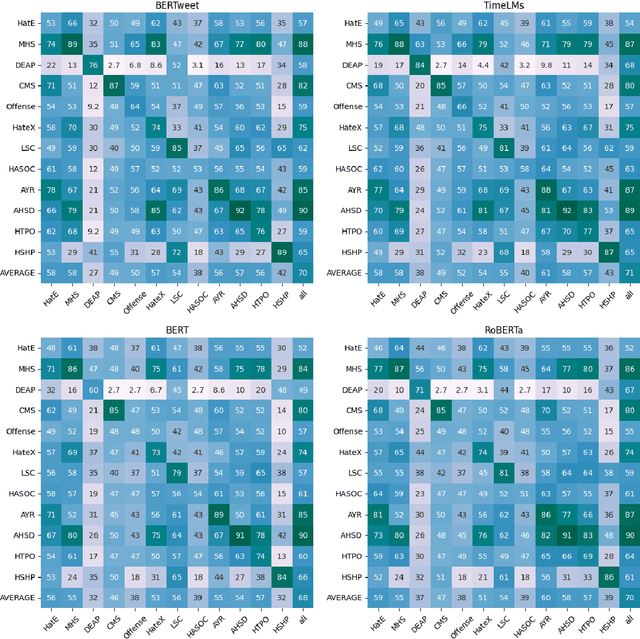
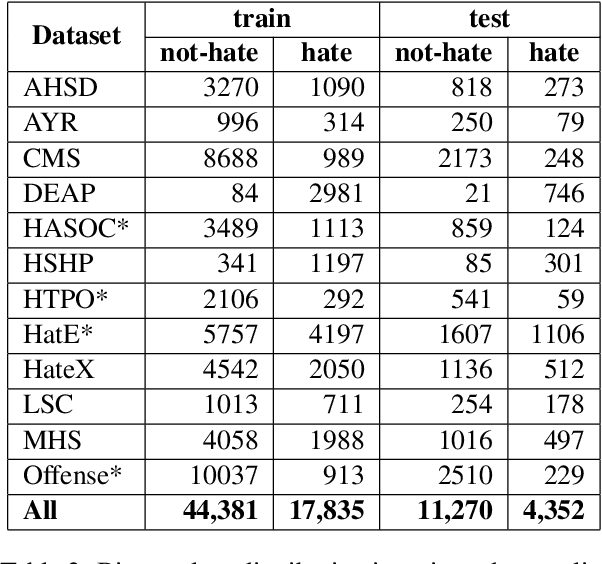
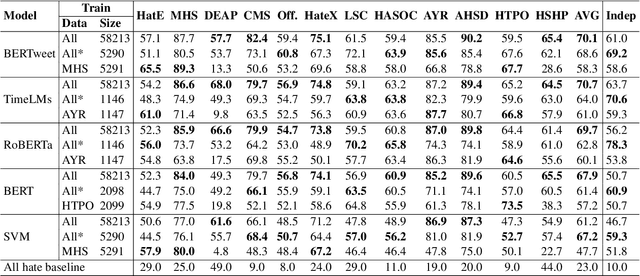
The automatic detection of hate speech online is an active research area in NLP. Most of the studies to date are based on social media datasets that contribute to the creation of hate speech detection models trained on them. However, data creation processes contain their own biases, and models inherently learn from these dataset-specific biases. In this paper, we perform a large-scale cross-dataset comparison where we fine-tune language models on different hate speech detection datasets. This analysis shows how some datasets are more generalisable than others when used as training data. Crucially, our experiments show how combining hate speech detection datasets can contribute to the development of robust hate speech detection models. This robustness holds even when controlling by data size and compared with the best individual datasets.
Twitter Topic Classification
Sep 20, 2022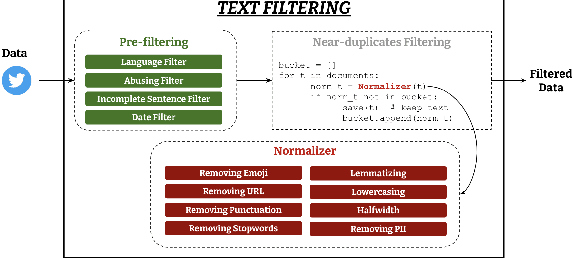


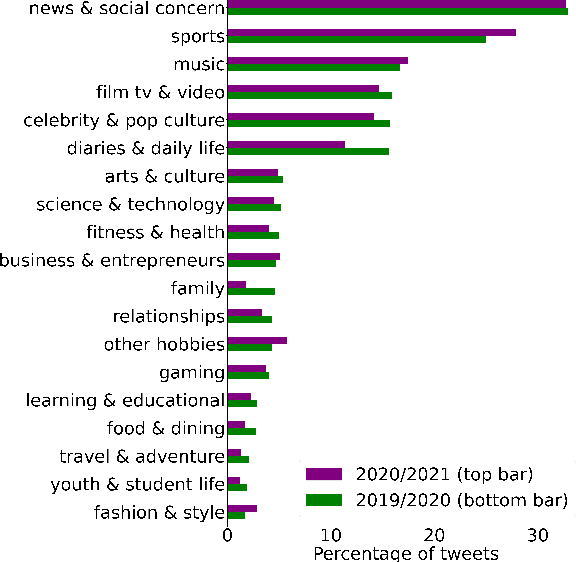
Social media platforms host discussions about a wide variety of topics that arise everyday. Making sense of all the content and organising it into categories is an arduous task. A common way to deal with this issue is relying on topic modeling, but topics discovered using this technique are difficult to interpret and can differ from corpus to corpus. In this paper, we present a new task based on tweet topic classification and release two associated datasets. Given a wide range of topics covering the most important discussion points in social media, we provide training and testing data from recent time periods that can be used to evaluate tweet classification models. Moreover, we perform a quantitative evaluation and analysis of current general- and domain-specific language models on the task, which provide more insights on the challenges and nature of the task.
TweetNLP: Cutting-Edge Natural Language Processing for Social Media
Jun 29, 2022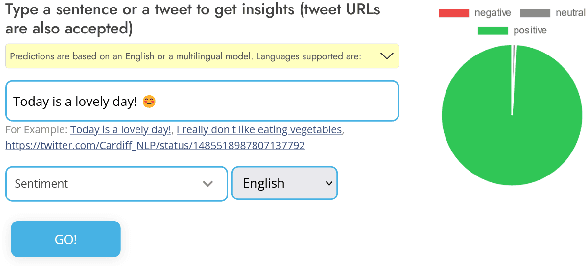
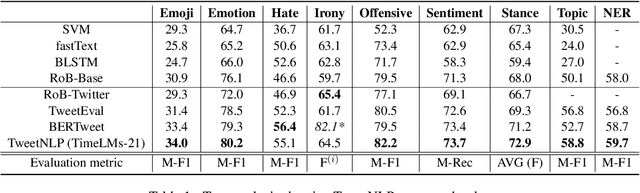
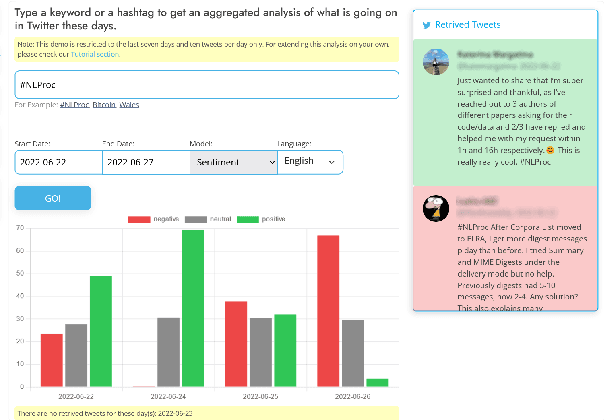

In this paper we present TweetNLP, an integrated platform for Natural Language Processing (NLP) in social media. TweetNLP supports a diverse set of NLP tasks, including generic focus areas such as sentiment analysis and named entity recognition, as well as social media-specific tasks such as emoji prediction and offensive language identification. Task-specific systems are powered by reasonably-sized Transformer-based language models specialized on social media text (in particular, Twitter) which can be run without the need for dedicated hardware or cloud services. The main contributions of TweetNLP are: (1) an integrated Python library for a modern toolkit supporting social media analysis using our various task-specific models adapted to the social domain; (2) an interactive online demo for codeless experimentation using our models; and (3) a tutorial covering a wide variety of typical social media applications.