 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
REALTALK: A 21-Day Real-World Dataset for Long-Term Conversation
Feb 18, 2025Long-term, open-domain dialogue capabilities are essential for chatbots aiming to recall past interactions and demonstrate emotional intelligence (EI). Yet, most existing research relies on synthetic, LLM-generated data, leaving open questions about real-world conversational patterns. To address this gap, we introduce REALTALK, a 21-day corpus of authentic messaging app dialogues, providing a direct benchmark against genuine human interactions. We first conduct a dataset analysis, focusing on EI attributes and persona consistency to understand the unique challenges posed by real-world dialogues. By comparing with LLM-generated conversations, we highlight key differences, including diverse emotional expressions and variations in persona stability that synthetic dialogues often fail to capture. Building on these insights, we introduce two benchmark tasks: (1) persona simulation where a model continues a conversation on behalf of a specific user given prior dialogue context; and (2) memory probing where a model answers targeted questions requiring long-term memory of past interactions. Our findings reveal that models struggle to simulate a user solely from dialogue history, while fine-tuning on specific user chats improves persona emulation. Additionally, existing models face significant challenges in recalling and leveraging long-term context within real-world conversations.
Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
Nov 29, 2024



The detection of sensitive content in large datasets is crucial for ensuring that shared and analysed data is free from harmful material. However, current moderation tools, such as external APIs, suffer from limitations in customisation, accuracy across diverse sensitive categories, and privacy concerns. Additionally, existing datasets and open-source models focus predominantly on toxic language, leaving gaps in detecting other sensitive categories such as substance abuse or self-harm. In this paper, we put forward a unified dataset tailored for social media content moderation across six sensitive categories: conflictual language, profanity, sexually explicit material, drug-related content, self-harm, and spam. By collecting and annotating data with consistent retrieval strategies and guidelines, we address the shortcomings of previous focalised research. Our analysis demonstrates that fine-tuning large language models (LLMs) on this novel dataset yields significant improvements in detection performance compared to open off-the-shelf models such as LLaMA, and even proprietary OpenAI models, which underperform by 10-15% overall. This limitation is even more pronounced on popular moderation APIs, which cannot be easily tailored to specific sensitive content categories, among others.
Multilingual Topic Classification in X: Dataset and Analysis
Oct 04, 2024



In the dynamic realm of social media, diverse topics are discussed daily, transcending linguistic boundaries. However, the complexities of understanding and categorising this content across various languages remain an important challenge with traditional techniques like topic modelling often struggling to accommodate this multilingual diversity. In this paper, we introduce X-Topic, a multilingual dataset featuring content in four distinct languages (English, Spanish, Japanese, and Greek), crafted for the purpose of tweet topic classification. Our dataset includes a wide range of topics, tailored for social media content, making it a valuable resource for scientists and professionals working on cross-linguistic analysis, the development of robust multilingual models, and computational scientists studying online dialogue. Finally, we leverage X-Topic to perform a comprehensive cross-linguistic and multilingual analysis, and compare the capabilities of current general- and domain-specific language models.
Explainability and Hate Speech: Structured Explanations Make Social Media Moderators Faster
Jun 06, 2024

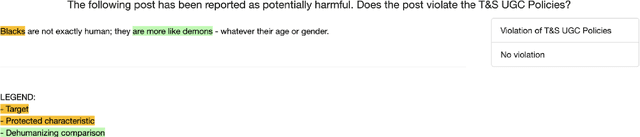
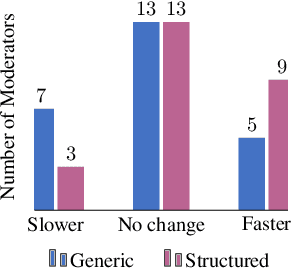
Content moderators play a key role in keeping the conversation on social media healthy. While the high volume of content they need to judge represents a bottleneck to the moderation pipeline, no studies have explored how models could support them to make faster decisions. There is, by now, a vast body of research into detecting hate speech, sometimes explicitly motivated by a desire to help improve content moderation, but published research using real content moderators is scarce. In this work we investigate the effect of explanations on the speed of real-world moderators. Our experiments show that while generic explanations do not affect their speed and are often ignored, structured explanations lower moderators' decision making time by 7.4%.
USE: Dynamic User Modeling with Stateful Sequence Models
Mar 20, 2024



User embeddings play a crucial role in user engagement forecasting and personalized services. Recent advances in sequence modeling have sparked interest in learning user embeddings from behavioral data. Yet behavior-based user embedding learning faces the unique challenge of dynamic user modeling. As users continuously interact with the apps, user embeddings should be periodically updated to account for users' recent and long-term behavior patterns. Existing methods highly rely on stateless sequence models that lack memory of historical behavior. They have to either discard historical data and use only the most recent data or reprocess the old and new data jointly. Both cases incur substantial computational overhead. To address this limitation, we introduce User Stateful Embedding (USE). USE generates user embeddings and reflects users' evolving behaviors without the need for exhaustive reprocessing by storing previous model states and revisiting them in the future. Furthermore, we introduce a novel training objective named future W-behavior prediction to transcend the limitations of next-token prediction by forecasting a broader horizon of upcoming user behaviors. By combining it with the Same User Prediction, a contrastive learning-based objective that predicts whether different segments of behavior sequences belong to the same user, we further improve the embeddings' distinctiveness and representativeness. We conducted experiments on 8 downstream tasks using Snapchat users' behavioral logs in both static (i.e., fixed user behavior sequences) and dynamic (i.e., periodically updated user behavior sequences) settings. We demonstrate USE's superior performance over established baselines. The results underscore USE's effectiveness and efficiency in integrating historical and recent user behavior sequences into user embeddings in dynamic user modeling.
Evaluating Very Long-Term Conversational Memory of LLM Agents
Feb 27, 2024Existing works on long-term open-domain dialogues focus on evaluating model responses within contexts spanning no more than five chat sessions. Despite advancements in long-context large language models (LLMs) and retrieval augmented generation (RAG) techniques, their efficacy in very long-term dialogues remains unexplored. To address this research gap, we introduce a machine-human pipeline to generate high-quality, very long-term dialogues by leveraging LLM-based agent architectures and grounding their dialogues on personas and temporal event graphs. Moreover, we equip each agent with the capability of sharing and reacting to images. The generated conversations are verified and edited by human annotators for long-range consistency and grounding to the event graphs. Using this pipeline, we collect LoCoMo, a dataset of very long-term conversations, each encompassing 300 turns and 9K tokens on avg., over up to 35 sessions. Based on LoCoMo, we present a comprehensive evaluation benchmark to measure long-term memory in models, encompassing question answering, event summarization, and multi-modal dialogue generation tasks. Our experimental results indicate that LLMs exhibit challenges in understanding lengthy conversations and comprehending long-range temporal and causal dynamics within dialogues. Employing strategies like long-context LLMs or RAG can offer improvements but these models still substantially lag behind human performance.
Designing and Evaluating General-Purpose User Representations Based on Behavioral Logs from a Measurement Process Perspective: A Case Study with Snapchat
Dec 19, 2023In human-computer interaction, understanding user behaviors and tailoring systems accordingly is pivotal. To this end, general-purpose user representation learning based on behavior logs is emerging as a powerful tool in user modeling, offering adaptability to various downstream tasks such as item recommendations and ad conversion prediction, without the need to fine-tune the upstream user model. While this methodology has shown promise in contexts like search engines and e-commerce platforms, its fit for instant messaging apps, a cornerstone of modern digital communication, remains largely uncharted. These apps, with their distinct interaction patterns, data structures, and user expectations, necessitate specialized attention. We explore this user modeling approach with Snapchat data as a case study. Furthermore, we introduce a novel design and evaluation framework rooted in the principles of the Measurement Process Framework from social science research methodology. Using this new framework, we design a Transformer-based user model that can produce high-quality general-purpose user representations for instant messaging platforms like Snapchat.