 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePATCH -- Psychometrics-AssisTed benCHmarking of Large Language Models: A Case Study of Mathematics Proficiency
Apr 02, 2024Many existing benchmarks of large (multimodal) language models (LLMs) focus on measuring LLMs' academic proficiency, often with also an interest in comparing model performance with human test takers. While these benchmarks have proven key to the development of LLMs, they suffer from several limitations, including questionable measurement quality (e.g., Do they measure what they are supposed to in a reliable way?), lack of quality assessment on the item level (e.g., Are some items more important or difficult than others?) and unclear human population reference (e.g., To whom can the model be compared?). In response to these challenges, we propose leveraging knowledge from psychometrics - a field dedicated to the measurement of latent variables like academic proficiency - into LLM benchmarking. We make three primary contributions. First, we introduce PATCH: a novel framework for Psychometrics-AssisTed benCHmarking of LLMs. PATCH addresses the aforementioned limitations, presenting a new direction for LLM benchmark research. Second, we implement PATCH by measuring GPT-4 and Gemini-Pro-Vision's proficiency in 8th grade mathematics against 56 human populations. We show that adopting a psychometrics-based approach yields evaluation outcomes that diverge from those based on existing benchmarking practices. Third, we release 4 datasets to support measuring and comparing LLM proficiency in grade school mathematics and science against human populations.
USE: Dynamic User Modeling with Stateful Sequence Models
Mar 20, 2024



User embeddings play a crucial role in user engagement forecasting and personalized services. Recent advances in sequence modeling have sparked interest in learning user embeddings from behavioral data. Yet behavior-based user embedding learning faces the unique challenge of dynamic user modeling. As users continuously interact with the apps, user embeddings should be periodically updated to account for users' recent and long-term behavior patterns. Existing methods highly rely on stateless sequence models that lack memory of historical behavior. They have to either discard historical data and use only the most recent data or reprocess the old and new data jointly. Both cases incur substantial computational overhead. To address this limitation, we introduce User Stateful Embedding (USE). USE generates user embeddings and reflects users' evolving behaviors without the need for exhaustive reprocessing by storing previous model states and revisiting them in the future. Furthermore, we introduce a novel training objective named future W-behavior prediction to transcend the limitations of next-token prediction by forecasting a broader horizon of upcoming user behaviors. By combining it with the Same User Prediction, a contrastive learning-based objective that predicts whether different segments of behavior sequences belong to the same user, we further improve the embeddings' distinctiveness and representativeness. We conducted experiments on 8 downstream tasks using Snapchat users' behavioral logs in both static (i.e., fixed user behavior sequences) and dynamic (i.e., periodically updated user behavior sequences) settings. We demonstrate USE's superior performance over established baselines. The results underscore USE's effectiveness and efficiency in integrating historical and recent user behavior sequences into user embeddings in dynamic user modeling.
Designing and Evaluating General-Purpose User Representations Based on Behavioral Logs from a Measurement Process Perspective: A Case Study with Snapchat
Dec 19, 2023In human-computer interaction, understanding user behaviors and tailoring systems accordingly is pivotal. To this end, general-purpose user representation learning based on behavior logs is emerging as a powerful tool in user modeling, offering adaptability to various downstream tasks such as item recommendations and ad conversion prediction, without the need to fine-tune the upstream user model. While this methodology has shown promise in contexts like search engines and e-commerce platforms, its fit for instant messaging apps, a cornerstone of modern digital communication, remains largely uncharted. These apps, with their distinct interaction patterns, data structures, and user expectations, necessitate specialized attention. We explore this user modeling approach with Snapchat data as a case study. Furthermore, we introduce a novel design and evaluation framework rooted in the principles of the Measurement Process Framework from social science research methodology. Using this new framework, we design a Transformer-based user model that can produce high-quality general-purpose user representations for instant messaging platforms like Snapchat.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023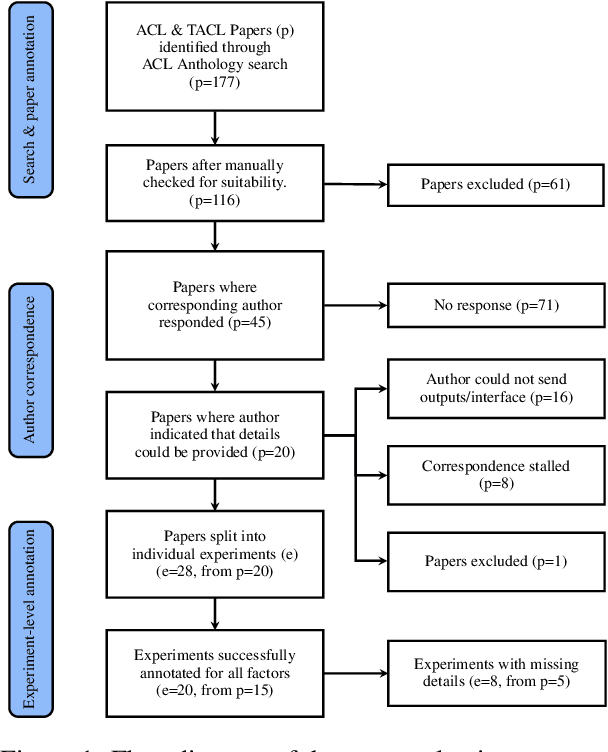
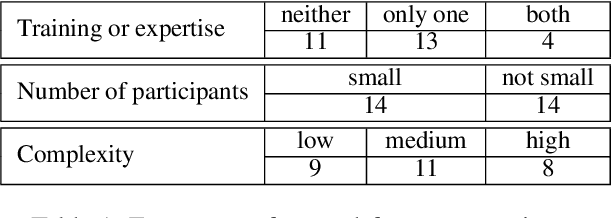


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Epicurus at SemEval-2023 Task 4: Improving Prediction of Human Values behind Arguments by Leveraging Their Definitions
Feb 27, 2023
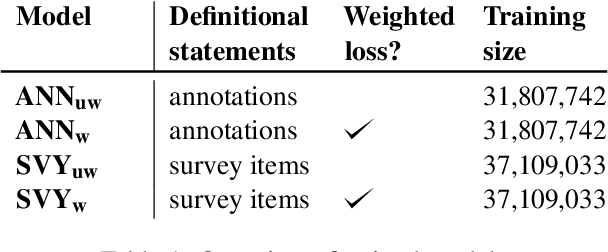


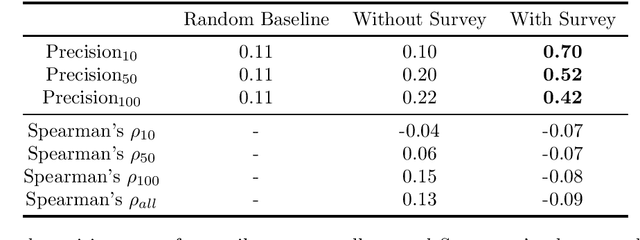
We describe our experiments for SemEval-2023 Task 4 on the identification of human values behind arguments (ValueEval). Because human values are subjective concepts which require precise definitions, we hypothesize that incorporating the definitions of human values (in the form of annotation instructions and validated survey items) during model training can yield better prediction performance. We explore this idea and show that our proposed models perform better than the challenge organizers' baselines, with improvements in macro F1 scores of up to 18%.
On Text-based Personality Computing: Challenges and Future Directions
Dec 14, 2022Text-based personality computing (TPC) has gained many research interests in NLP. In this paper, we describe 15 challenges that we consider deserving the attention of the research community. These challenges are organized by the following topics: personality taxonomies, measurement quality, datasets, performance evaluation, modelling choices, as well as ethics and fairness. When addressing each challenge, not only do we combine perspectives from both NLP and social sciences, but also offer concrete suggestions towards more valid and reliable TPC research.
Modelling Stance Detection as Textual Entailment Recognition and Leveraging Measurement Knowledge from Social Sciences
Dec 13, 2022
Stance detection (SD) can be considered a special case of textual entailment recognition (TER), a generic natural language task. Modelling SD as TER may offer benefits like more training data and a more general learning scheme. In this paper, we present an initial empirical analysis of this approach. We apply it to a difficult but relevant test case where no existing labelled SD dataset is available, because this is where modelling SD as TER may be especially helpful. We also leverage measurement knowledge from social sciences to improve model performance. We discuss our findings and suggest future research directions.
Evaluating the Construct Validity of Text Embeddings with Application to Survey Questions
Feb 18, 2022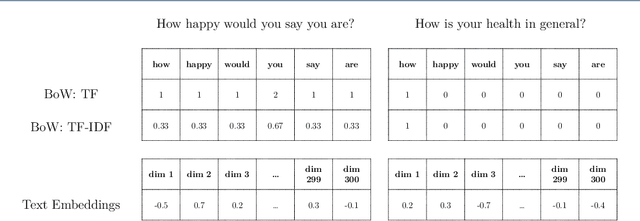

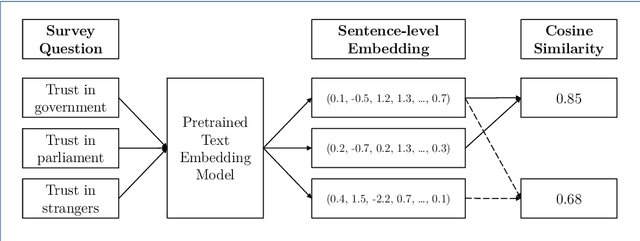

Text embedding models from Natural Language Processing can map text data (e.g. words, sentences, documents) to supposedly meaningful numerical representations (a.k.a. text embeddings). While such models are increasingly applied in social science research, one important issue is often not addressed: the extent to which these embeddings are valid representations of constructs relevant for social science research. We therefore propose the use of the classic construct validity framework to evaluate the validity of text embeddings. We show how this framework can be adapted to the opaque and high-dimensional nature of text embeddings, with application to survey questions. We include several popular text embedding methods (e.g. fastText, GloVe, BERT, Sentence-BERT, Universal Sentence Encoder) in our construct validity analyses. We find evidence of convergent and discriminant validity in some cases. We also show that embeddings can be used to predict respondent's answers to completely new survey questions. Furthermore, BERT-based embedding techniques and the Universal Sentence Encoder provide more valid representations of survey questions than do others. Our results thus highlight the necessity to examine the construct validity of text embeddings before deploying them in social science research.
Assessing the Reliability of Word Embedding Gender Bias Measures
Sep 10, 2021

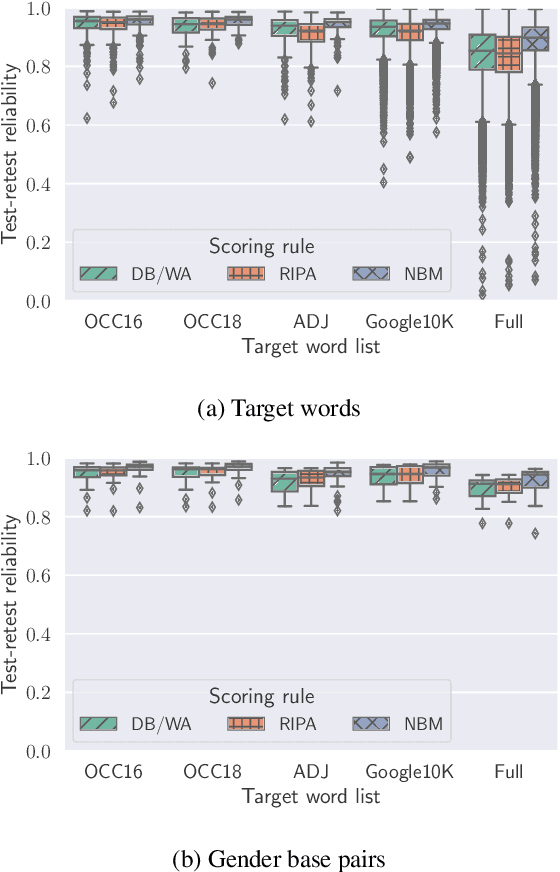
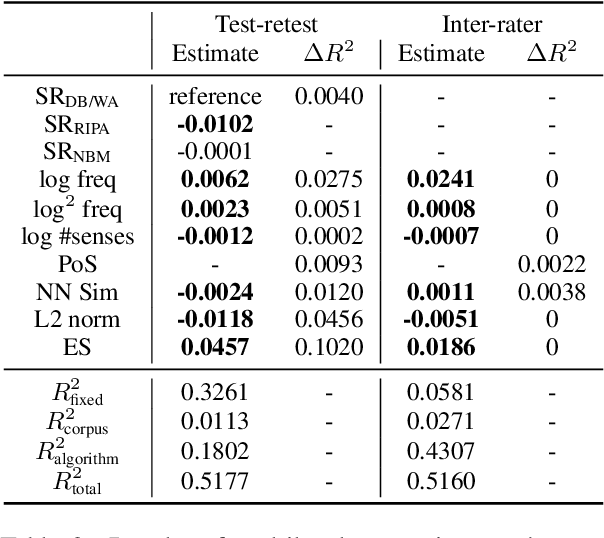
Various measures have been proposed to quantify human-like social biases in word embeddings. However, bias scores based on these measures can suffer from measurement error. One indication of measurement quality is reliability, concerning the extent to which a measure produces consistent results. In this paper, we assess three types of reliability of word embedding gender bias measures, namely test-retest reliability, inter-rater consistency and internal consistency. Specifically, we investigate the consistency of bias scores across different choices of random seeds, scoring rules and words. Furthermore, we analyse the effects of various factors on these measures' reliability scores. Our findings inform better design of word embedding gender bias measures. Moreover, we urge researchers to be more critical about the application of such measures.
ASReview: Open Source Software for Efficient and Transparent Active Learning for Systematic Reviews
Jun 22, 2020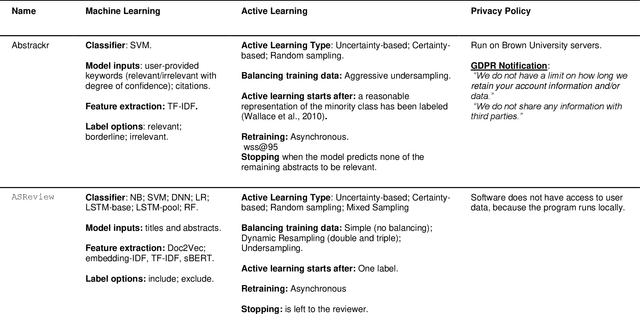
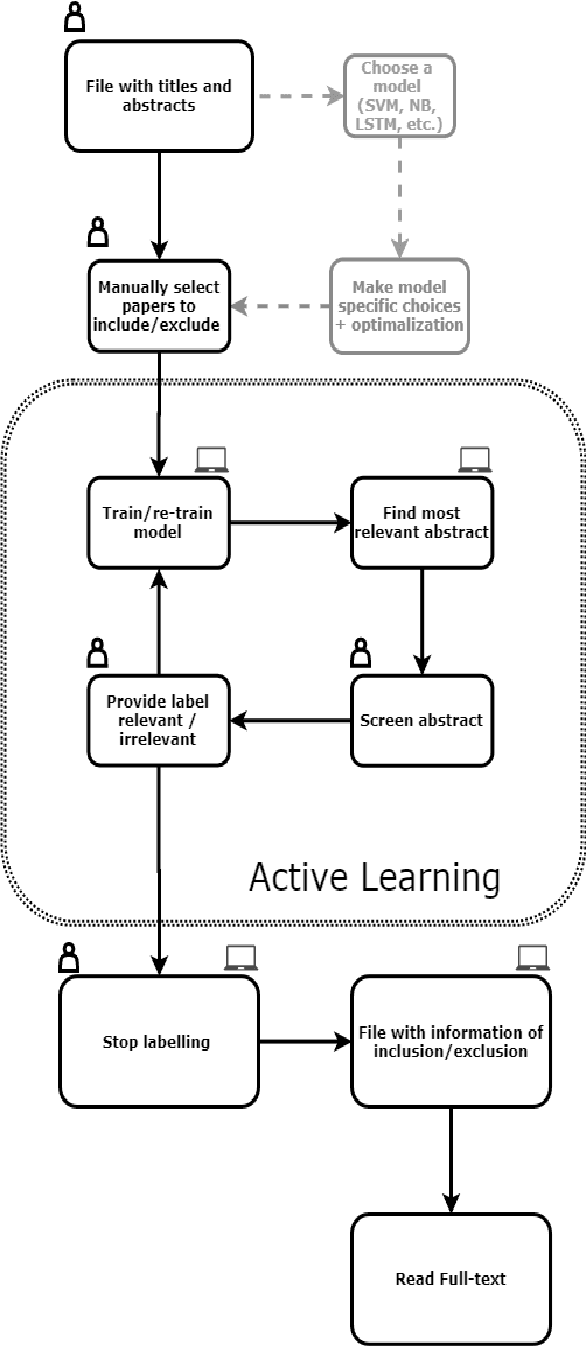

For many tasks -- including guideline development for medical doctors and systematic reviews for research fields -- the scientific literature needs to be checked systematically. The current practice is that scholars and practitioners screen thousands of studies by hand to find which studies to include in their review. This is error prone and inefficient. We therefore developed an open source machine learning (ML)-aided pipeline: Active learning for Systematic Reviews (ASReview). We show that by using active learning, ASReview can lead to far more efficient reviewing than manual reviewing, while exhibiting adequate quality. Furthermore, the presented software is fully transparent and open source.