Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpicurus at SemEval-2023 Task 4: Improving Prediction of Human Values behind Arguments by Leveraging Their Definitions
Paper and Code

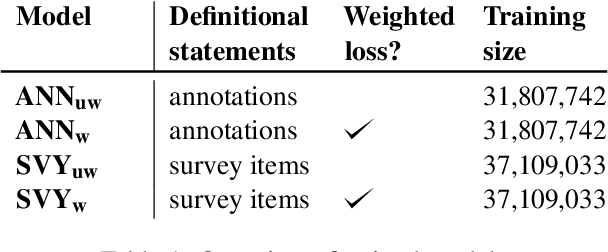


We describe our experiments for SemEval-2023 Task 4 on the identification of human values behind arguments (ValueEval). Because human values are subjective concepts which require precise definitions, we hypothesize that incorporating the definitions of human values (in the form of annotation instructions and validated survey items) during model training can yield better prediction performance. We explore this idea and show that our proposed models perform better than the challenge organizers' baselines, with improvements in macro F1 scores of up to 18%.
* Under review of SemEval23
View paper on