 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe Need to Measure Data Diversity in NLP -- Better and Broader
May 26, 2025Although diversity in NLP datasets has received growing attention, the question of how to measure it remains largely underexplored. This opinion paper examines the conceptual and methodological challenges of measuring data diversity and argues that interdisciplinary perspectives are essential for developing more fine-grained and valid measures.
Tokenization is Sensitive to Language Variation
Feb 21, 2025



Variation in language is ubiquitous and often systematically linked to regional, social, and contextual factors. Tokenizers split texts into smaller units and might behave differently for less common linguistic forms. This might affect downstream LLM performance differently on two types of tasks: Tasks where the model should be robust to language variation (e.g., for semantic tasks like NLI, labels do not depend on whether a text uses British or American spelling) and tasks where the model should be sensitive to language variation (e.g., for form-based tasks like authorship verification, labels depend on whether a text uses British or American spelling). We pre-train BERT base models for the popular Byte-Pair Encoding algorithm to investigate how key algorithmic design choices impact downstream models' performances: fitting corpus, pre-tokenizer and vocabulary size. We find that the best tokenizer varies on the two task types -- with the pre-tokenizer having the biggest impact on performance. Further, we introduce a new approach to estimate tokenizer impact on downstream LLM performance, showing significant improvement over techniques like R\'enyi efficiency. We encourage more work on language variation and its relation to tokenizers and thus LLM performance.
Transforming Dutch: Debiasing Dutch Coreference Resolution Systems for Non-binary Pronouns
Apr 30, 2024Gender-neutral pronouns are increasingly being introduced across Western languages. Recent evaluations have however demonstrated that English NLP systems are unable to correctly process gender-neutral pronouns, with the risk of erasing and misgendering non-binary individuals. This paper examines a Dutch coreference resolution system's performance on gender-neutral pronouns, specifically hen and die. In Dutch, these pronouns were only introduced in 2016, compared to the longstanding existence of singular they in English. We additionally compare two debiasing techniques for coreference resolution systems in non-binary contexts: Counterfactual Data Augmentation (CDA) and delexicalisation. Moreover, because pronoun performance can be hard to interpret from a general evaluation metric like LEA, we introduce an innovative evaluation metric, the pronoun score, which directly represents the portion of correctly processed pronouns. Our results reveal diminished performance on gender-neutral pronouns compared to gendered counterparts. Nevertheless, although delexicalisation fails to yield improvements, CDA substantially reduces the performance gap between gendered and gender-neutral pronouns. We further show that CDA remains effective in low-resource settings, in which a limited set of debiasing documents is used. This efficacy extends to previously unseen neopronouns, which are currently infrequently used but may gain popularity in the future, underscoring the viability of effective debiasing with minimal resources and low computational costs.
What's Mine becomes Yours: Defining, Annotating and Detecting Context-Dependent Paraphrases in News Interview Dialogs
Apr 10, 2024Best practices for high conflict conversations like counseling or customer support almost always include recommendations to paraphrase the previous speaker. Although paraphrase classification has received widespread attention in NLP, paraphrases are usually considered independent from context, and common models and datasets are not applicable to dialog settings. In this work, we investigate paraphrases in dialog (e.g., Speaker 1: "That book is mine." becomes Speaker 2: "That book is yours."). We provide an operationalization of context-dependent paraphrases, and develop a training for crowd-workers to classify paraphrases in dialog. We introduce a dataset with utterance pairs from NPR and CNN news interviews annotated for context-dependent paraphrases. To enable analyses on label variation, the dataset contains 5,581 annotations on 600 utterance pairs. We present promising results with in-context learning and with token classification models for automatic paraphrase detection in dialog.
PATCH -- Psychometrics-AssisTed benCHmarking of Large Language Models: A Case Study of Mathematics Proficiency
Apr 02, 2024Many existing benchmarks of large (multimodal) language models (LLMs) focus on measuring LLMs' academic proficiency, often with also an interest in comparing model performance with human test takers. While these benchmarks have proven key to the development of LLMs, they suffer from several limitations, including questionable measurement quality (e.g., Do they measure what they are supposed to in a reliable way?), lack of quality assessment on the item level (e.g., Are some items more important or difficult than others?) and unclear human population reference (e.g., To whom can the model be compared?). In response to these challenges, we propose leveraging knowledge from psychometrics - a field dedicated to the measurement of latent variables like academic proficiency - into LLM benchmarking. We make three primary contributions. First, we introduce PATCH: a novel framework for Psychometrics-AssisTed benCHmarking of LLMs. PATCH addresses the aforementioned limitations, presenting a new direction for LLM benchmark research. Second, we implement PATCH by measuring GPT-4 and Gemini-Pro-Vision's proficiency in 8th grade mathematics against 56 human populations. We show that adopting a psychometrics-based approach yields evaluation outcomes that diverge from those based on existing benchmarking practices. Third, we release 4 datasets to support measuring and comparing LLM proficiency in grade school mathematics and science against human populations.
Designing and Evaluating General-Purpose User Representations Based on Behavioral Logs from a Measurement Process Perspective: A Case Study with Snapchat
Dec 19, 2023In human-computer interaction, understanding user behaviors and tailoring systems accordingly is pivotal. To this end, general-purpose user representation learning based on behavior logs is emerging as a powerful tool in user modeling, offering adaptability to various downstream tasks such as item recommendations and ad conversion prediction, without the need to fine-tune the upstream user model. While this methodology has shown promise in contexts like search engines and e-commerce platforms, its fit for instant messaging apps, a cornerstone of modern digital communication, remains largely uncharted. These apps, with their distinct interaction patterns, data structures, and user expectations, necessitate specialized attention. We explore this user modeling approach with Snapchat data as a case study. Furthermore, we introduce a novel design and evaluation framework rooted in the principles of the Measurement Process Framework from social science research methodology. Using this new framework, we design a Transformer-based user model that can produce high-quality general-purpose user representations for instant messaging platforms like Snapchat.
FTFT: efficient and robust Fine-Tuning by transFerring Training dynamics
Oct 10, 2023Despite the massive success of fine-tuning large Pre-trained Language Models (PLMs) on a wide range of Natural Language Processing (NLP) tasks, they remain susceptible to out-of-distribution (OOD) and adversarial inputs. Data map (DM) is a simple yet effective dual-model approach that enhances the robustness of fine-tuned PLMs, which involves fine-tuning a model on the original training set (i.e. reference model), selecting a specified fraction of important training examples according to the training dynamics of the reference model, and fine-tuning the same model on these selected examples (i.e. main model). However, it suffers from the drawback of requiring fine-tuning the same model twice, which is computationally expensive for large models. In this paper, we first show that 1) training dynamics are highly transferable across different model sizes and different pre-training methods, and that 2) main models fine-tuned using DM learn faster than when using conventional Empirical Risk Minimization (ERM). Building on these observations, we propose a novel fine-tuning approach based on the DM method: Fine-Tuning by transFerring Training dynamics (FTFT). Compared with DM, FTFT uses more efficient reference models and then fine-tunes more capable main models for fewer steps. Our experiments show that FTFT achieves better generalization robustness than ERM while spending less than half of the training cost.
Epicurus at SemEval-2023 Task 4: Improving Prediction of Human Values behind Arguments by Leveraging Their Definitions
Feb 27, 2023
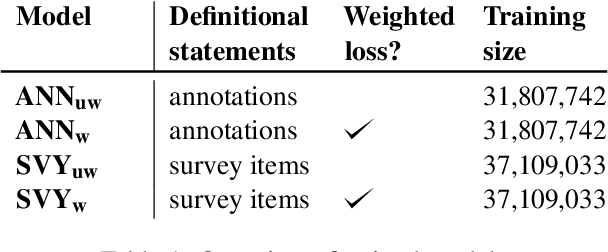


We describe our experiments for SemEval-2023 Task 4 on the identification of human values behind arguments (ValueEval). Because human values are subjective concepts which require precise definitions, we hypothesize that incorporating the definitions of human values (in the form of annotation instructions and validated survey items) during model training can yield better prediction performance. We explore this idea and show that our proposed models perform better than the challenge organizers' baselines, with improvements in macro F1 scores of up to 18%.
Measuring the Instability of Fine-Tuning
Feb 15, 2023Fine-tuning pre-trained language models on downstream tasks with varying random seeds has been shown to be unstable, especially on small datasets. Many previous studies have investigated this instability and proposed methods to mitigate it. However, most studies only used the standard deviation of performance scores (SD) as their measure, which is a narrow characterization of instability. In this paper, we analyze SD and six other measures quantifying instability at different levels of granularity. Moreover, we propose a systematic framework to evaluate the validity of these measures. Finally, we analyze the consistency and difference between different measures by reassessing existing instability mitigation methods. We hope our results will inform the development of better measurements of fine-tuning instability.
Template-based Abstractive Microblog Opinion Summarisation
Aug 08, 2022
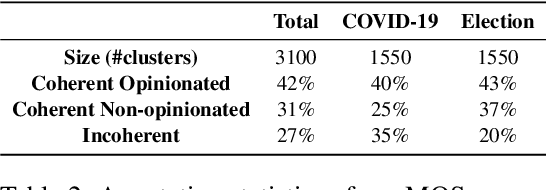


We introduce the task of microblog opinion summarisation (MOS) and share a dataset of 3100 gold-standard opinion summaries to facilitate research in this domain. The dataset contains summaries of tweets spanning a 2-year period and covers more topics than any other public Twitter summarisation dataset. Summaries are abstractive in nature and have been created by journalists skilled in summarising news articles following a template separating factual information (main story) from author opinions. Our method differs from previous work on generating gold-standard summaries from social media, which usually involves selecting representative posts and thus favours extractive summarisation models. To showcase the dataset's utility and challenges, we benchmark a range of abstractive and extractive state-of-the-art summarisation models and achieve good performance, with the former outperforming the latter. We also show that fine-tuning is necessary to improve performance and investigate the benefits of using different sample sizes.