 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alignment Bottleneck in Decomposition-Based Claim Verification
Feb 11, 2026Structured claim decomposition is often proposed as a solution for verifying complex, multi-faceted claims, yet empirical results have been inconsistent. We argue that these inconsistencies stem from two overlooked bottlenecks: evidence alignment and sub-claim error profiles. To better understand these factors, we introduce a new dataset of real-world complex claims, featuring temporally bounded evidence and human-annotated sub-claim evidence spans. We evaluate decomposition under two evidence alignment setups: Sub-claim Aligned Evidence (SAE) and Repeated Claim-level Evidence (SRE). Our results reveal that decomposition brings significant performance improvement only when evidence is granular and strictly aligned. By contrast, standard setups that rely on repeated claim-level evidence (SRE) fail to improve and often degrade performance as shown across different datasets and domains (PHEMEPlus, MMM-Fact, COVID-Fact). Furthermore, we demonstrate that in the presence of noisy sub-claim labels, the nature of the error ends up determining downstream robustness. We find that conservative "abstention" significantly reduces error propagation compared to aggressive but incorrect predictions. These findings suggest that future claim decomposition frameworks must prioritize precise evidence synthesis and calibrate the label bias of sub-claim verification models.
Fundamental Reasoning Paradigms Induce Out-of-Domain Generalization in Language Models
Feb 09, 2026Deduction, induction, and abduction are fundamental reasoning paradigms, core for human logical thinking. Although improving Large Language Model (LLM) reasoning has attracted significant research efforts, the extent to which the fundamental paradigms induce generalization has yet to be systematically explored. In this study, we shed light on how the interplay between these core paradigms influences LLMs' reasoning behavior. To this end, we first collect a new dataset of reasoning trajectories from symbolic tasks, each targeting one of the three fundamental paradigms, to abstract from concrete world knowledge. Then, we investigate effective ways for inducing these skills into LLMs. We experiment with a battery of methods including simple fine-tuning, and more complex approaches to increase model depth, or transform a dense model to a mixture-of-experts. We comprehensively evaluate induced models on realistic out-of-domain tasks, that are entirely formulated in natural language and contain real-world knowledge. Our results reveal that our approach yields strong generalizability with substantial performance gains (up to $14.60$) across realistic tasks.
Enhancing Logical Reasoning in Language Models via Symbolically-Guided Monte Carlo Process Supervision
May 26, 2025Large language models (LLMs) have shown promising performance in mathematical and logical reasoning benchmarks. However, recent studies have pointed to memorization, rather than generalization, as one of the leading causes for such performance. LLMs, in fact, are susceptible to content variations, demonstrating a lack of robust symbolic abstractions supporting their reasoning process. To improve reliability, many attempts have been made to combine LLMs with symbolic methods. Nevertheless, existing approaches fail to effectively leverage symbolic representations due to the challenges involved in developing reliable and scalable verification mechanisms. In this paper, we propose to overcome such limitations by generating symbolic reasoning trajectories and select the high-quality ones using a process reward model automatically tuned based on Monte Carlo estimation. The trajectories are then employed via fine-tuning methods to improve logical reasoning and generalization. Our results on logical reasoning benchmarks such as FOLIO and LogicAsker show the effectiveness of the proposed method with large gains on frontier and open-weight models. Moreover, additional experiments on claim verification reveal that fine-tuning on the generated symbolic reasoning trajectories enhances out-of-domain generalizability, suggesting the potential impact of symbolically-guided process supervision in alleviating the effect of memorization on LLM reasoning.
Temporal reasoning for timeline summarisation in social media
Dec 30, 2024



This paper explores whether enhancing temporal reasoning capabilities in Large Language Models (LLMs) can improve the quality of timeline summarization, the task of summarising long texts containing sequences of events, particularly social media threads . We introduce \textit{NarrativeReason}, a novel dataset focused on temporal relationships among sequential events within narratives, distinguishing it from existing temporal reasoning datasets that primarily address pair-wise event relationships. Our approach then combines temporal reasoning with timeline summarization through a knowledge distillation framework, where we first fine-tune a teacher model on temporal reasoning tasks and then distill this knowledge into a student model while simultaneously training it for the task of timeline summarization. Experimental results demonstrate that our model achieves superior performance on mental health-related timeline summarization tasks, which involve long social media threads with repetitions of events and a mix of emotions, highlighting the importance of leveraging temporal reasoning to improve timeline summarisation.
TempoFormer: A Transformer for Temporally-aware Representations in Change Detection
Aug 28, 2024



Dynamic representation learning plays a pivotal role in understanding the evolution of linguistic content over time. On this front both context and time dynamics as well as their interplay are of prime importance. Current approaches model context via pre-trained representations, which are typically temporally agnostic. Previous work on modeling context and temporal dynamics has used recurrent methods, which are slow and prone to overfitting. Here we introduce TempoFormer, the fist task-agnostic transformer-based and temporally-aware model for dynamic representation learning. Our approach is jointly trained on inter and intra context dynamics and introduces a novel temporal variation of rotary positional embeddings. The architecture is flexible and can be used as the temporal representation foundation of other models or applied to different transformer-based architectures. We show new SOTA performance on three different real-time change detection tasks.
Feedback-aligned Mixed LLMs for Machine Language-Molecule Translation
May 22, 2024The intersection of chemistry and Artificial Intelligence (AI) is an active area of research focused on accelerating scientific discovery. While using large language models (LLMs) with scientific modalities has shown potential, there are significant challenges to address, such as improving training efficiency and dealing with the out-of-distribution problem. Focussing on the task of automated language-molecule translation, we are the first to use state-of-the art (SOTA) human-centric optimisation algorithms in the cross-modal setting, successfully aligning cross-language-molecule modals. We empirically show that we can augment the capabilities of scientific LLMs without the need for extensive data or large models. We conduct experiments using only 10% of the available data to mitigate memorisation effects associated with training large models on extensive datasets. We achieve significant performance gains, surpassing the best benchmark model trained on extensive in-distribution data by a large margin and reach new SOTA levels. Additionally we are the first to propose employing non-linear fusion for mixing cross-modal LLMs which further boosts performance gains without increasing training costs or data needs. Finally, we introduce a fine-grained, domain-agnostic evaluation method to assess hallucination in LLMs and promote responsible use.
Assessing the Reasoning Abilities of ChatGPT in the Context of Claim Verification
Feb 16, 2024
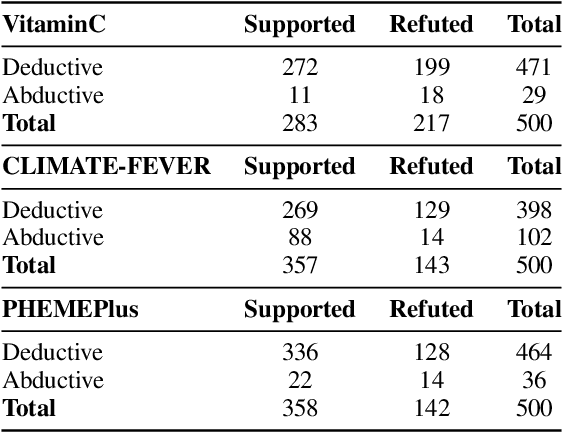
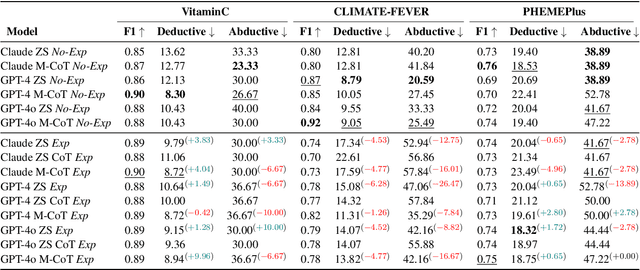
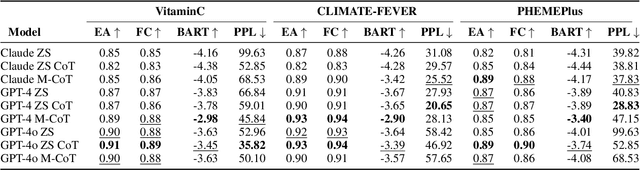
The reasoning capabilities of LLMs are currently hotly debated. We examine the issue from the perspective of claim/rumour verification. We propose the first logical reasoning framework designed to break down any claim or rumor paired with evidence into the atomic reasoning steps necessary for verification. Based on our framework, we curate two annotated collections of such claim/evidence pairs: a synthetic dataset from Wikipedia and a real-world set stemming from rumours circulating on Twitter. We use them to evaluate the reasoning capabilities of GPT-3.5-Turbo and GPT-4 (hereinafter referred to as ChatGPT) within the context of our framework, providing a thorough analysis. Our results show that ChatGPT struggles in abductive reasoning, although this can be somewhat mitigated by using manual Chain of Thought (CoT) as opposed to Zero Shot (ZS) and ZS CoT approaches. Our study contributes to the growing body of research suggesting that ChatGPT's reasoning processes are unlikely to mirror human-like reasoning, and that LLMs need to be more rigorously evaluated in order to distinguish between hype and actual capabilities, especially in high stake real-world tasks such as claim verification.
Clinically meaningful timeline summarisation in social media for mental health monitoring
Jan 29, 2024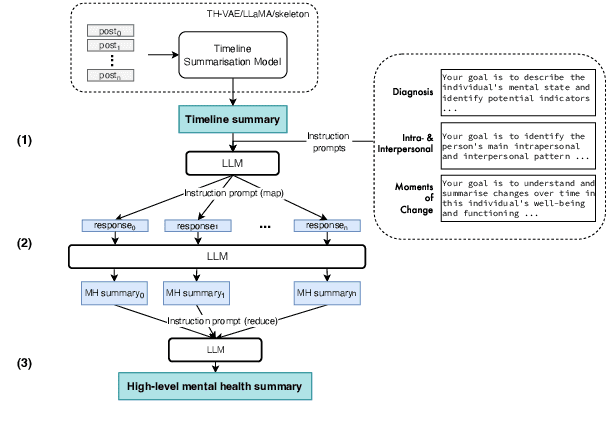


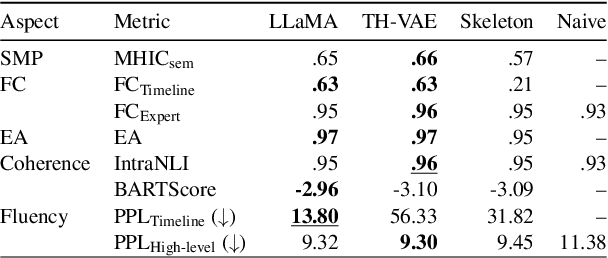
We introduce the new task of clinically meaningful summarisation of social media user timelines, appropriate for mental health monitoring. We develop a novel approach for unsupervised abstractive summarisation that produces a two-layer summary consisting of both high-level information, covering aspects useful to clinical experts, as well as accompanying time sensitive evidence from a user's social media timeline. A key methodological novelty comes from the timeline summarisation component based on a version of hierarchical variational autoencoder (VAE) adapted to represent long texts and guided by LLM-annotated key phrases. The resulting timeline summary is input into a LLM (LLaMA-2) to produce the final summary containing both the high level information, obtained through instruction prompting, as well as corresponding evidence from the user's timeline. We assess the summaries generated by our novel architecture via automatic evaluation against expert written summaries and via human evaluation with clinical experts, showing that timeline summarisation by TH-VAE results in logically coherent summaries rich in clinical utility and superior to LLM-only approaches in capturing changes over time.
Generating Unsupervised Abstractive Explanations for Rumour Verification
Jan 23, 2024



The task of rumour verification in social media concerns assessing the veracity of a claim on the basis of conversation threads that result from it. While previous work has focused on predicting a veracity label, here we reformulate the task to generate model-centric, free-text explanations of a rumour's veracity. We follow an unsupervised approach by first utilising post-hoc explainability methods to score the most important posts within a thread and then we use these posts to generate informative explanatory summaries by employing template-guided summarisation. To evaluate the informativeness of the explanatory summaries, we exploit the few-shot learning capabilities of a large language model (LLM). Our experiments show that LLMs can have similar agreement to humans in evaluating summaries. Importantly, we show that explanatory abstractive summaries are more informative and better reflect the predicted rumour veracity than just using the highest ranking posts in the thread.
Sig-Networks Toolkit: Signature Networks for Longitudinal Language Modelling
Dec 06, 2023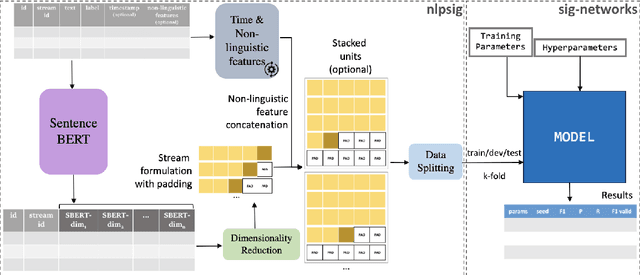
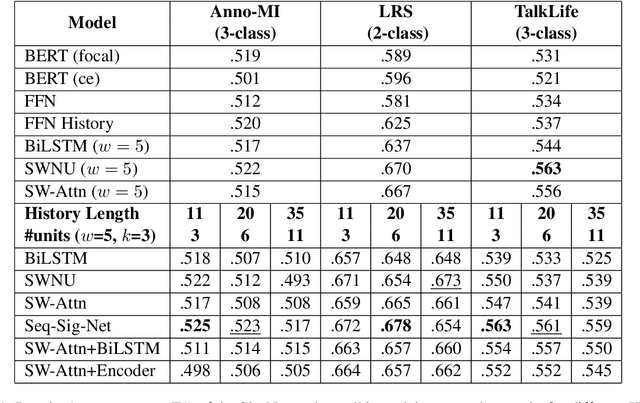
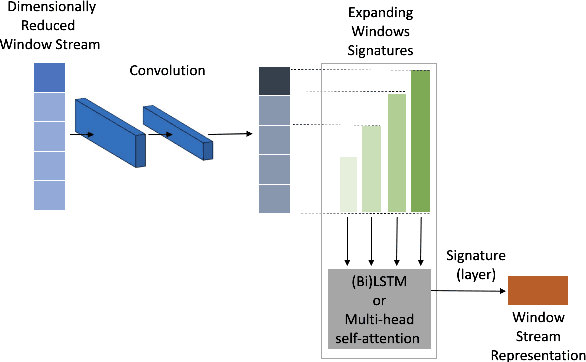
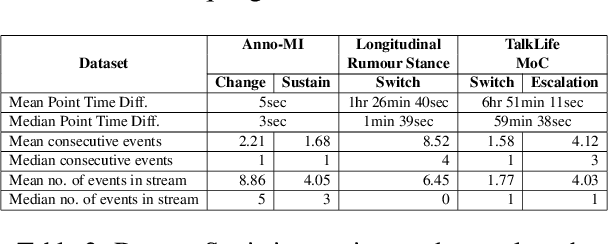
We present an open-source, pip installable toolkit, Sig-Networks, the first of its kind for longitudinal language modelling. A central focus is the incorporation of Signature-based Neural Network models, which have recently shown success in temporal tasks. We apply and extend published research providing a full suite of signature-based models. Their components can be used as PyTorch building blocks in future architectures. Sig-Networks enables task-agnostic dataset plug-in, seamless pre-processing for sequential data, parameter flexibility, automated tuning across a range of models. We examine signature networks under three different NLP tasks of varying temporal granularity: counselling conversations, rumour stance switch and mood changes in social media threads, showing SOTA performance in all three, and provide guidance for future tasks. We release the Toolkit as a PyTorch package with an introductory video, Git repositories for preprocessing and modelling including sample notebooks on the modeled NLP tasks.