 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Reasoning Paradigms Induce Out-of-Domain Generalization in Language Models
Feb 09, 2026Deduction, induction, and abduction are fundamental reasoning paradigms, core for human logical thinking. Although improving Large Language Model (LLM) reasoning has attracted significant research efforts, the extent to which the fundamental paradigms induce generalization has yet to be systematically explored. In this study, we shed light on how the interplay between these core paradigms influences LLMs' reasoning behavior. To this end, we first collect a new dataset of reasoning trajectories from symbolic tasks, each targeting one of the three fundamental paradigms, to abstract from concrete world knowledge. Then, we investigate effective ways for inducing these skills into LLMs. We experiment with a battery of methods including simple fine-tuning, and more complex approaches to increase model depth, or transform a dense model to a mixture-of-experts. We comprehensively evaluate induced models on realistic out-of-domain tasks, that are entirely formulated in natural language and contain real-world knowledge. Our results reveal that our approach yields strong generalizability with substantial performance gains (up to $14.60$) across realistic tasks.
An Empirical Study on Preference Tuning Generalization and Diversity Under Domain Shift
Jan 09, 2026Preference tuning aligns pretrained language models to human judgments of quality, helpfulness, or safety by optimizing over explicit preference signals rather than likelihood alone. Prior work has shown that preference-tuning degrades performance and reduces helpfulness when evaluated outside the training domain. However, the extent to which adaptation strategies mitigate this domain shift remains unexplored. We address this challenge by conducting a comprehensive and systematic study of alignment generalization under domain shift. We compare five popular alignment objectives and various adaptation strategies from source to target, including target-domain supervised fine-tuning and pseudo-labeling, across summarization and question-answering helpfulness tasks. Our findings reveal systematic differences in generalization across alignment objectives under domain shift. We show that adaptation strategies based on pseudo-labeling can substantially reduce domain-shift degradation
Enhancing Linguistic Competence of Language Models through Pre-training with Language Learning Tasks
Jan 06, 2026Language models (LMs) are pre-trained on raw text datasets to generate text sequences token-by-token. While this approach facilitates the learning of world knowledge and reasoning, it does not explicitly optimize for linguistic competence. To bridge this gap, we propose L2T, a pre-training framework integrating Language Learning Tasks alongside standard next-token prediction. Inspired by human language acquisition, L2T transforms raw text into structured input-output pairs to provide explicit linguistic stimulation. Pre-training LMs on a mixture of raw text and L2T data not only improves overall performance on linguistic competence benchmarks but accelerates its acquisition, while maintaining competitive performance on general reasoning tasks.
Analysing Chain of Thought Dynamics: Active Guidance or Unfaithful Post-hoc Rationalisation?
Aug 27, 2025Recent work has demonstrated that Chain-of-Thought (CoT) often yields limited gains for soft-reasoning problems such as analytical and commonsense reasoning. CoT can also be unfaithful to a model's actual reasoning. We investigate the dynamics and faithfulness of CoT in soft-reasoning tasks across instruction-tuned, reasoning and reasoning-distilled models. Our findings reveal differences in how these models rely on CoT, and show that CoT influence and faithfulness are not always aligned.
Progressive Depth Up-scaling via Optimal Transport
Aug 11, 2025Scaling Large Language Models (LLMs) yields performance gains but incurs substantial training costs. Depth up-scaling offers training efficiency by adding new layers to pre-trained models. However, most existing methods copy or average weights from base layers, neglecting neuron permutation differences. This limitation can potentially cause misalignment that harms performance. Inspired by applying Optimal Transport (OT) for neuron alignment, we propose Optimal Transport Depth Up-Scaling (OpT-DeUS). OpT-DeUS aligns and fuses Transformer blocks in adjacent base layers via OT for new layer creation, to mitigate neuron permutation mismatch between layers. OpT-DeUS achieves better overall performance and offers improved training efficiency than existing methods for continual pre-training and supervised fine-tuning across different model sizes. To further evaluate the impact of interpolation positions, our extensive analysis shows that inserting new layers closer to the top results in higher training efficiency due to shorter back-propagation time while obtaining additional performance gains.
Enhancing Logical Reasoning in Language Models via Symbolically-Guided Monte Carlo Process Supervision
May 26, 2025Large language models (LLMs) have shown promising performance in mathematical and logical reasoning benchmarks. However, recent studies have pointed to memorization, rather than generalization, as one of the leading causes for such performance. LLMs, in fact, are susceptible to content variations, demonstrating a lack of robust symbolic abstractions supporting their reasoning process. To improve reliability, many attempts have been made to combine LLMs with symbolic methods. Nevertheless, existing approaches fail to effectively leverage symbolic representations due to the challenges involved in developing reliable and scalable verification mechanisms. In this paper, we propose to overcome such limitations by generating symbolic reasoning trajectories and select the high-quality ones using a process reward model automatically tuned based on Monte Carlo estimation. The trajectories are then employed via fine-tuning methods to improve logical reasoning and generalization. Our results on logical reasoning benchmarks such as FOLIO and LogicAsker show the effectiveness of the proposed method with large gains on frontier and open-weight models. Moreover, additional experiments on claim verification reveal that fine-tuning on the generated symbolic reasoning trajectories enhances out-of-domain generalizability, suggesting the potential impact of symbolically-guided process supervision in alleviating the effect of memorization on LLM reasoning.
GreekBarBench: A Challenging Benchmark for Free-Text Legal Reasoning and Citations
May 22, 2025We introduce GreekBarBench, a benchmark that evaluates LLMs on legal questions across five different legal areas from the Greek Bar exams, requiring citations to statutory articles and case facts. To tackle the challenges of free-text evaluation, we propose a three-dimensional scoring system combined with an LLM-as-a-judge approach. We also develop a meta-evaluation benchmark to assess the correlation between LLM-judges and human expert evaluations, revealing that simple, span-based rubrics improve their alignment. Our systematic evaluation of 13 proprietary and open-weight LLMs shows that even though the best models outperform average expert scores, they fall short of the 95th percentile of experts.
Compressing Language Models for Specialized Domains
Feb 25, 2025Compression techniques such as pruning and quantization offer a solution for more efficient deployment of language models (LMs), albeit with small performance drops in benchmark performance. However, general-purpose LM compression methods can negatively affect performance in specialized domains (e.g. biomedical or legal). Recent work has sought to address this, yet requires computationally expensive full-parameter fine-tuning. To this end, we propose cross-calibration, a novel training-free approach for improving the domain performance of compressed LMs. Our approach effectively leverages Hessian-based sensitivity to identify weights that are influential for both in-domain and general performance. Through extensive experimentation, we demonstrate that cross-calibration substantially outperforms existing approaches on domain-specific tasks, without compromising general performance. Notably, these gains come without additional computational overhead, displaying remarkable potential towards extracting domain-specialized compressed models from general-purpose LMs.
Vocabulary Expansion of Chat Models with Unlabeled Target Language Data
Dec 16, 2024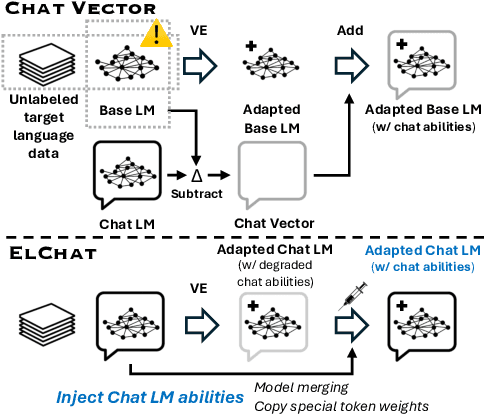
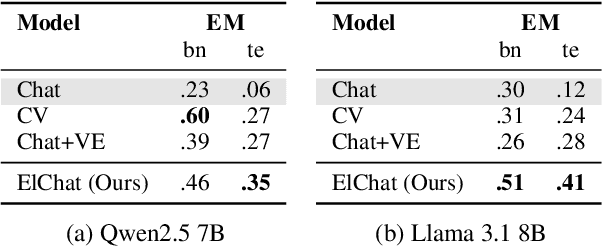
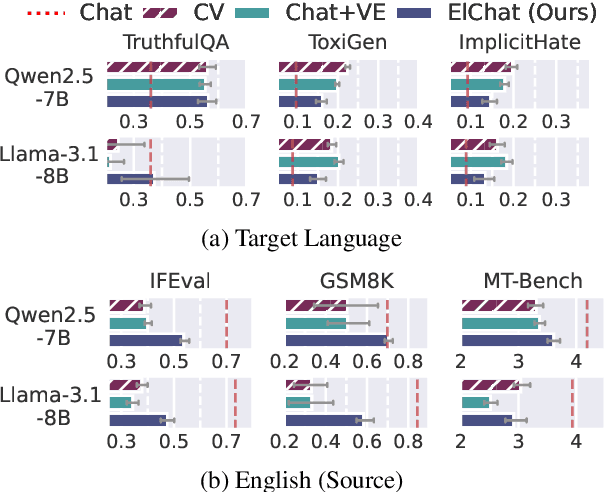
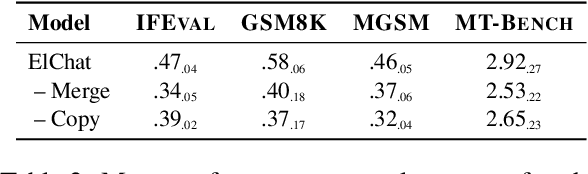
Chat models (i.e. language models trained to follow instructions through conversation with humans) outperform base models (i.e. trained solely on unlabeled data) in both conversation and general task-solving abilities. These models are generally English-centric and require further adaptation for languages that are underrepresented in or absent from their training data. A common technique for adapting base models is to extend the model's vocabulary with target language tokens, i.e. vocabulary expansion (VE), and then continually pre-train it on language-specific data. Using chat data is ideal for chat model adaptation, but often, either this does not exist or is costly to construct. Alternatively, adapting chat models with unlabeled data is a possible solution, but it could result in catastrophic forgetting. In this paper, we investigate the impact of using unlabeled target language data for VE on chat models for the first time. We first show that off-the-shelf VE generally performs well across target language tasks and models in 71% of cases, though it underperforms in scenarios where source chat models are already strong. To further improve adapted models, we propose post-hoc techniques that inject information from the source model without requiring any further training. Experiments reveal the effectiveness of our methods, helping the adapted models to achieve performance improvements in 87% of cases.
How Private are Language Models in Abstractive Summarization?
Dec 16, 2024Language models (LMs) have shown outstanding performance in text summarization including sensitive domains such as medicine and law. In these settings, it is important that personally identifying information (PII) included in the source document should not leak in the summary. Prior efforts have mostly focused on studying how LMs may inadvertently elicit PII from training data. However, to what extent LMs can provide privacy-preserving summaries given a non-private source document remains under-explored. In this paper, we perform a comprehensive study across two closed- and three open-weight LMs of different sizes and families. We experiment with prompting and fine-tuning strategies for privacy-preservation across a range of summarization datasets across three domains. Our extensive quantitative and qualitative analysis including human evaluation shows that LMs often cannot prevent PII leakage on their summaries and that current widely-used metrics cannot capture context dependent privacy risks.