 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempoFit: Plug-and-Play Layer-Wise Temporal KV Memory for Long-Horizon Vision-Language-Action Manipulation
Mar 08, 2026Pretrained Vision-Language-Action (VLA) policies have achieved strong single-step manipulation, but their inference remains largely memoryless, which is brittle in non-Markovian long-horizon settings with occlusion, state aliasing, and subtle post-action changes. Prior approaches inject history either by stacking frames, which scales visual tokens and latency while adding near-duplicate pixels, or by learning additional temporal interfaces that require (re-)training and may break the original single-frame inference graph. We present TempoFit, a training-free temporal retrofit that upgrades frozen VLAs through state-level memory. Our key insight is that prefix attention K/V already form a model-native, content-addressable runtime state; reusing them across timesteps introduces history without new tokens or trainable modules. TempoFit stores layer-wise FIFO prefix K/V at selected intermediate layers, performs parameter-free K-to-K retrieval with Frame-Gap Temporal Bias (FGTB), a fixed recency bias inspired by positional biases in NLP, to keep decisions present-dominant, and injects the retrieved context via pre-attention residual loading with norm-preserving rescaling to avoid distribution shift under frozen weights. On LIBERO-LONG, TempoFit improves strong pretrained backbones by up to +4.0% average success rate while maintaining near-real-time latency, and it transfers consistently to CALVIN and real-robot long-horizon tasks.
Estimating Respiratory Effort from Nocturnal Breathing Sounds for Obstructive Sleep Apnoea Screening
Sep 18, 2025



Obstructive sleep apnoea (OSA) is a prevalent condition with significant health consequences, yet many patients remain undiagnosed due to the complexity and cost of over-night polysomnography. Acoustic-based screening provides a scalable alternative, yet performance is limited by environmental noise and the lack of physiological context. Respiratory effort is a key signal used in clinical scoring of OSA events, but current approaches require additional contact sensors that reduce scalability and patient comfort. This paper presents the first study to estimate respiratory effort directly from nocturnal audio, enabling physiological context to be recovered from sound alone. We propose a latent-space fusion framework that integrates the estimated effort embeddings with acoustic features for OSA detection. Using a dataset of 157 nights from 103 participants recorded in home environments, our respiratory effort estimator achieves a concordance correlation coefficient of 0.48, capturing meaningful respiratory dynamics. Fusing effort and audio improves sensitivity and AUC over audio-only baselines, especially at low apnoea-hypopnoea index thresholds. The proposed approach requires only smartphone audio at test time, which enables sensor-free, scalable, and longitudinal OSA monitoring.
Transfer Learning for Paediatric Sleep Apnoea Detection Using Physiology-Guided Acoustic Models
Sep 18, 2025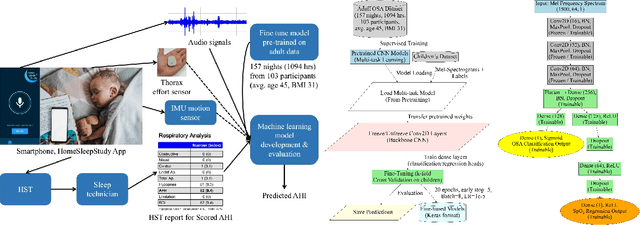



Paediatric obstructive sleep apnoea (OSA) is clinically significant yet difficult to diagnose, as children poorly tolerate sensor-based polysomnography. Acoustic monitoring provides a non-invasive alternative for home-based OSA screening, but limited paediatric data hinders the development of robust deep learning approaches. This paper proposes a transfer learning framework that adapts acoustic models pretrained on adult sleep data to paediatric OSA detection, incorporating SpO2-based desaturation patterns to enhance model training. Using a large adult sleep dataset (157 nights) and a smaller paediatric dataset (15 nights), we systematically evaluate (i) single- versus multi-task learning, (ii) encoder freezing versus full fine-tuning, and (iii) the impact of delaying SpO2 labels to better align them with the acoustics and capture physiologically meaningful features. Results show that fine-tuning with SpO2 integration consistently improves paediatric OSA detection compared with baseline models without adaptation. These findings demonstrate the feasibility of transfer learning for home-based OSA screening in children and offer its potential clinical value for early diagnosis.
How Private are Language Models in Abstractive Summarization?
Dec 16, 2024Language models (LMs) have shown outstanding performance in text summarization including sensitive domains such as medicine and law. In these settings, it is important that personally identifying information (PII) included in the source document should not leak in the summary. Prior efforts have mostly focused on studying how LMs may inadvertently elicit PII from training data. However, to what extent LMs can provide privacy-preserving summaries given a non-private source document remains under-explored. In this paper, we perform a comprehensive study across two closed- and three open-weight LMs of different sizes and families. We experiment with prompting and fine-tuning strategies for privacy-preservation across a range of summarization datasets across three domains. Our extensive quantitative and qualitative analysis including human evaluation shows that LMs often cannot prevent PII leakage on their summaries and that current widely-used metrics cannot capture context dependent privacy risks.
DEL-Ranking: Ranking-Correction Denoising Framework for Elucidating Molecular Affinities in DNA-Encoded Libraries
Oct 19, 2024



DNA-encoded library (DEL) screening has revolutionized the detection of protein-ligand interactions through read counts, enabling rapid exploration of vast chemical spaces. However, noise in read counts, stemming from nonspecific interactions, can mislead this exploration process. We present DEL-Ranking, a novel distribution-correction denoising framework that addresses these challenges. Our approach introduces two key innovations: (1) a novel ranking loss that rectifies relative magnitude relationships between read counts, enabling the learning of causal features determining activity levels, and (2) an iterative algorithm employing self-training and consistency loss to establish model coherence between activity label and read count predictions. Furthermore, we contribute three new DEL screening datasets, the first to comprehensively include multi-dimensional molecular representations, protein-ligand enrichment values, and their activity labels. These datasets mitigate data scarcity issues in AI-driven DEL screening research. Rigorous evaluation on diverse DEL datasets demonstrates DEL-Ranking's superior performance across multiple correlation metrics, with significant improvements in binding affinity prediction accuracy. Our model exhibits zero-shot generalization ability across different protein targets and successfully identifies potential motifs determining compound binding affinity. This work advances DEL screening analysis and provides valuable resources for future research in this area.
SurgPETL: Parameter-Efficient Image-to-Surgical-Video Transfer Learning for Surgical Phase Recognition
Sep 30, 2024



Capitalizing on image-level pre-trained models for various downstream tasks has recently emerged with promising performance. However, the paradigm of "image pre-training followed by video fine-tuning" for high-dimensional video data inevitably poses significant performance bottlenecks. Furthermore, in the medical domain, many surgical video tasks encounter additional challenges posed by the limited availability of video data and the necessity for comprehensive spatial-temporal modeling. Recently, Parameter-Efficient Image-to-Video Transfer Learning has emerged as an efficient and effective paradigm for video action recognition tasks, which employs image-level pre-trained models with promising feature transferability and involves cross-modality temporal modeling with minimal fine-tuning. Nevertheless, the effectiveness and generalizability of this paradigm within intricate surgical domain remain unexplored. In this paper, we delve into a novel problem of efficiently adapting image-level pre-trained models to specialize in fine-grained surgical phase recognition, termed as Parameter-Efficient Image-to-Surgical-Video Transfer Learning. Firstly, we develop a parameter-efficient transfer learning benchmark SurgPETL for surgical phase recognition, and conduct extensive experiments with three advanced methods based on ViTs of two distinct scales pre-trained on five large-scale natural and medical datasets. Then, we introduce the Spatial-Temporal Adaptation module, integrating a standard spatial adapter with a novel temporal adapter to capture detailed spatial features and establish connections across temporal sequences for robust spatial-temporal modeling. Extensive experiments on three challenging datasets spanning various surgical procedures demonstrate the effectiveness of SurgPETL with STA.
CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Feb 21, 2024



Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.
Partition Speeds Up Learning Implicit Neural Representations Based on Exponential-Increase Hypothesis
Oct 22, 2023



$\textit{Implicit neural representations}$ (INRs) aim to learn a $\textit{continuous function}$ (i.e., a neural network) to represent an image, where the input and output of the function are pixel coordinates and RGB/Gray values, respectively. However, images tend to consist of many objects whose colors are not perfectly consistent, resulting in the challenge that image is actually a $\textit{discontinuous piecewise function}$ and cannot be well estimated by a continuous function. In this paper, we empirically investigate that if a neural network is enforced to fit a discontinuous piecewise function to reach a fixed small error, the time costs will increase exponentially with respect to the boundaries in the spatial domain of the target signal. We name this phenomenon the $\textit{exponential-increase}$ hypothesis. Under the $\textit{exponential-increase}$ hypothesis, learning INRs for images with many objects will converge very slowly. To address this issue, we first prove that partitioning a complex signal into several sub-regions and utilizing piecewise INRs to fit that signal can significantly speed up the convergence. Based on this fact, we introduce a simple partition mechanism to boost the performance of two INR methods for image reconstruction: one for learning INRs, and the other for learning-to-learn INRs. In both cases, we partition an image into different sub-regions and dedicate smaller networks for each part. In addition, we further propose two partition rules based on regular grids and semantic segmentation maps, respectively. Extensive experiments validate the effectiveness of the proposed partitioning methods in terms of learning INR for a single image (ordinary learning framework) and the learning-to-learn framework.
Intelligibility prediction with a pretrained noise-robust automatic speech recognition model
Oct 20, 2023This paper describes two intelligibility prediction systems derived from a pretrained noise-robust automatic speech recognition (ASR) model for the second Clarity Prediction Challenge (CPC2). One system is intrusive and leverages the hidden representations of the ASR model. The other system is non-intrusive and makes predictions with derived ASR uncertainty. The ASR model is only pretrained with a simulated noisy speech corpus and does not take advantage of the CPC2 data. For that reason, the intelligibility prediction systems are robust to unseen scenarios given the accurate prediction performance on the CPC2 evaluation.
Homophily-enhanced Structure Learning for Graph Clustering
Aug 11, 2023Graph clustering is a fundamental task in graph analysis, and recent advances in utilizing graph neural networks (GNNs) have shown impressive results. Despite the success of existing GNN-based graph clustering methods, they often overlook the quality of graph structure, which is inherent in real-world graphs due to their sparse and multifarious nature, leading to subpar performance. Graph structure learning allows refining the input graph by adding missing links and removing spurious connections. However, previous endeavors in graph structure learning have predominantly centered around supervised settings, and cannot be directly applied to our specific clustering tasks due to the absence of ground-truth labels. To bridge the gap, we propose a novel method called \textbf{ho}mophily-enhanced structure \textbf{le}arning for graph clustering (HoLe). Our motivation stems from the observation that subtly enhancing the degree of homophily within the graph structure can significantly improve GNNs and clustering outcomes. To realize this objective, we develop two clustering-oriented structure learning modules, i.e., hierarchical correlation estimation and cluster-aware sparsification. The former module enables a more accurate estimation of pairwise node relationships by leveraging guidance from latent and clustering spaces, while the latter one generates a sparsified structure based on the similarity matrix and clustering assignments. Additionally, we devise a joint optimization approach alternating between training the homophily-enhanced structure learning and GNN-based clustering, thereby enforcing their reciprocal effects. Extensive experiments on seven benchmark datasets of various types and scales, across a range of clustering metrics, demonstrate the superiority of HoLe against state-of-the-art baselines.