 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Image-Text Matching with Optimal Partial Transport
Mar 15, 2026Cross-modal matching, a fundamental task in bridging vision and language, has recently garnered substantial research interest. Despite the development of numerous methods aimed at quantifying the semantic relatedness between image-text pairs, these methods often fall short of achieving both outstanding performance and high efficiency. In this paper, we propose the crOss-Modal sInkhorn maTching (OMIT) network as an effective solution to effectively improving performance while maintaining efficiency. Rooted in the theoretical foundations of Optimal Transport, OMIT harnesses the capabilities of Cross-modal Mover's Distance to precisely compute the similarity between fine-grained visual and textual fragments, utilizing Sinkhorn iterations for efficient approximation. To further alleviate the issue of redundant alignments, we seamlessly integrate partial matching into OMIT, leveraging local-to-global similarities to eliminate the interference of irrelevant fragments. We conduct extensive evaluations of OMIT on two benchmark image-text retrieval datasets, namely Flickr30K and MS-COCO. The superior performance achieved by OMIT on both datasets unequivocally demonstrates its effectiveness in cross-modal matching. Furthermore, through comprehensive visualization analysis, we elucidate OMIT's inherent tendency towards focal matching, thereby shedding light on its efficacy. Our code is publicly available at https://github.com/ppanzx/OMIT.
LLM-Bootstrapped Targeted Finding Guidance for Factual MLLM-based Medical Report Generation
Feb 28, 2026The automatic generation of medical reports utilizing Multimodal Large Language Models (MLLMs) frequently encounters challenges related to factual instability, which may manifest as the omission of findings or the incorporation of inaccurate information, thereby constraining their applicability in clinical settings. Current methodologies typically produce reports based directly on image features, which inherently lack a definitive factual basis. In response to this limitation, we introduce Fact-Flow, an innovative framework that separates the process of visual fact identification from the generation of reports. This is achieved by initially predicting clinical findings from the image, which subsequently directs the MLLM to produce a report that is factually precise. A pivotal advancement of our approach is a pipeline that leverages a Large Language Model (LLM) to autonomously create a dataset of labeled medical findings, effectively eliminating the need for expensive manual annotation. Extensive experimental evaluations conducted on two disease-focused medical datasets validate the efficacy of our method, demonstrating a significant enhancement in factual accuracy compared to state-of-the-art models, while concurrently preserving high standards of text quality.
Unsupervised Causal Prototypical Networks for De-biased Interpretable Dermoscopy Diagnosis
Feb 27, 2026Despite the success of deep learning in dermoscopy image analysis, its inherent black-box nature hinders clinical trust, motivating the use of prototypical networks for case-based visual transparency. However, inevitable selection bias in clinical data often drives these models toward shortcut learning, where environmental confounders are erroneously encoded as predictive prototypes, generating spurious visual evidence that misleads medical decision-making. To mitigate these confounding effects, we propose CausalProto, an Unsupervised Causal Prototypical Network that fundamentally purifies the visual evidence chain. Framed within a Structural Causal Model, we employ an Information Bottleneck-constrained encoder to enforce strict unsupervised orthogonal disentanglement between pathological features and environmental confounders. By mapping these decoupled representations into independent prototypical spaces, we leverage the learned spurious dictionary to perform backdoor adjustment via do-calculus, transforming complex causal interventions into efficient expectation pooling to marginalize environmental noise. Extensive experiments on multiple dermoscopy datasets demonstrate that CausalProto achieves superior diagnostic performance and consistently outperforms standard black box models, while simultaneously providing transparent and high purity visual interpretability without suffering from the traditional accuracy compromise.
Directed Ordinal Diffusion Regularization for Progression-Aware Diabetic Retinopathy Grading
Feb 25, 2026Diabetic Retinopathy (DR) progresses as a continuous and irreversible deterioration of the retina, following a well-defined clinical trajectory from mild to severe stages. However, most existing ordinal regression approaches model DR severity as a set of static, symmetric ranks, capturing relative order while ignoring the inherent unidirectional nature of disease progression. As a result, the learned feature representations may violate biological plausibility, allowing implausible proximity between non-consecutive stages or even reverse transitions. To bridge this gap, we propose Directed Ordinal Diffusion Regularization (D-ODR), which explicitly models the feature space as a directed flow by constructing a progression-constrained directed graph that strictly enforces forward disease evolution. By performing multi-scale diffusion on this directed structure, D-ODR imposes penalties on score inversions along valid progression paths, thereby effectively preventing the model from learning biologically inconsistent reverse transitions. This mechanism aligns the feature representation with the natural trajectory of DR worsening. Extensive experiments demonstrate that D-ODR yields superior grading performance compared to state-of-the-art ordinal regression and DR-specific grading methods, offering a more clinically reliable assessment of disease severity. Our code is available on https://github.com/HovChen/D-ODR.
Multi-Omics Analysis for Cancer Subtype Inference via Unrolling Graph Smoothness Priors
Aug 08, 2025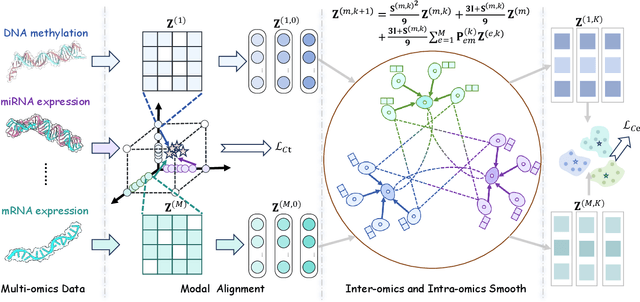
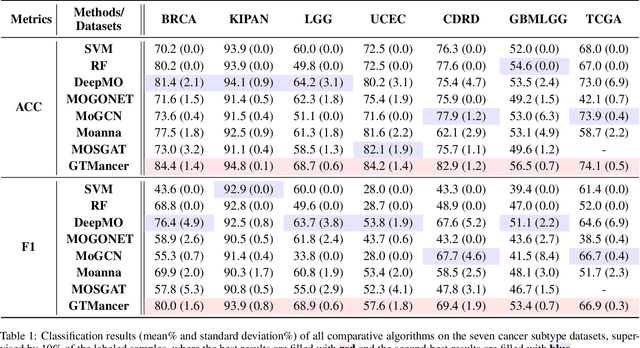
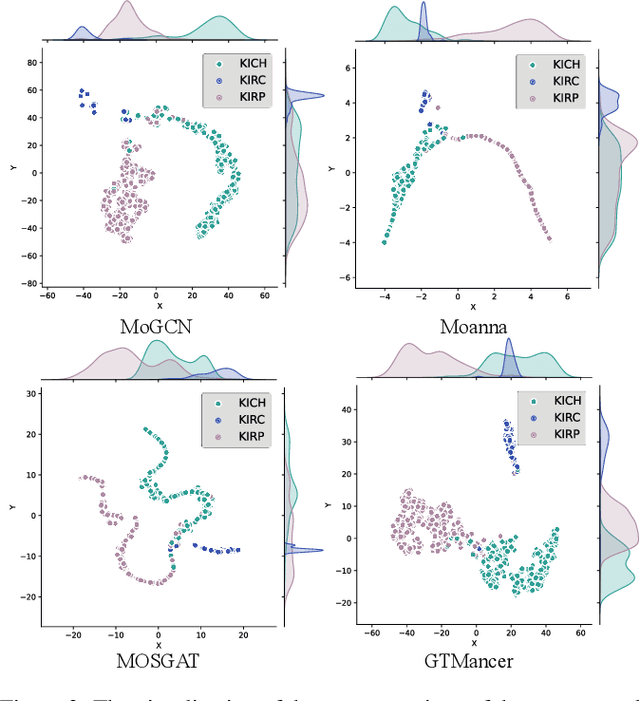
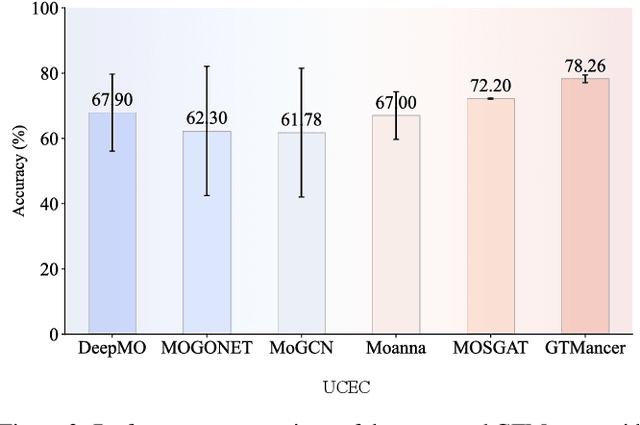
Integrating multi-omics datasets through data-driven analysis offers a comprehensive understanding of the complex biological processes underlying various diseases, particularly cancer. Graph Neural Networks (GNNs) have recently demonstrated remarkable ability to exploit relational structures in biological data, enabling advances in multi-omics integration for cancer subtype classification. Existing approaches often neglect the intricate coupling between heterogeneous omics, limiting their capacity to resolve subtle cancer subtype heterogeneity critical for precision oncology. To address these limitations, we propose a framework named Graph Transformer for Multi-omics Cancer Subtype Classification (GTMancer). This framework builds upon the GNN optimization problem and extends its application to complex multi-omics data. Specifically, our method leverages contrastive learning to embed multi-omics data into a unified semantic space. We unroll the multiplex graph optimization problem in that unified space and introduce dual sets of attention coefficients to capture structural graph priors both within and among multi-omics data. This approach enables global omics information to guide the refining of the representations of individual omics. Empirical experiments on seven real-world cancer datasets demonstrate that GTMancer outperforms existing state-of-the-art algorithms.
ImputeINR: Time Series Imputation via Implicit Neural Representations for Disease Diagnosis with Missing Data
May 16, 2025Healthcare data frequently contain a substantial proportion of missing values, necessitating effective time series imputation to support downstream disease diagnosis tasks. However, existing imputation methods focus on discrete data points and are unable to effectively model sparse data, resulting in particularly poor performance for imputing substantial missing values. In this paper, we propose a novel approach, ImputeINR, for time series imputation by employing implicit neural representations (INR) to learn continuous functions for time series. ImputeINR leverages the merits of INR in that the continuous functions are not coupled to sampling frequency and have infinite sampling frequency, allowing ImputeINR to generate fine-grained imputations even on extremely sparse observed values. Extensive experiments conducted on eight datasets with five ratios of masked values show the superior imputation performance of ImputeINR, especially for high missing ratios in time series data. Furthermore, we validate that applying ImputeINR to impute missing values in healthcare data enhances the performance of downstream disease diagnosis tasks. Codes are available.
Collaborative Expert LLMs Guided Multi-Objective Molecular Optimization
Mar 05, 2025



Molecular optimization is a crucial yet complex and time-intensive process that often acts as a bottleneck for drug development. Traditional methods rely heavily on trial and error, making multi-objective optimization both time-consuming and resource-intensive. Current AI-based methods have shown limited success in handling multi-objective optimization tasks, hampering their practical utilization. To address this challenge, we present MultiMol, a collaborative large language model (LLM) system designed to guide multi-objective molecular optimization. MultiMol comprises two agents, including a data-driven worker agent and a literature-guided research agent. The data-driven worker agent is a large language model being fine-tuned to learn how to generate optimized molecules considering multiple objectives, while the literature-guided research agent is responsible for searching task-related literature to find useful prior knowledge that facilitates identifying the most promising optimized candidates. In evaluations across six multi-objective optimization tasks, MultiMol significantly outperforms existing methods, achieving a 82.30% success rate, in sharp contrast to the 27.50% success rate of current strongest methods. To further validate its practical impact, we tested MultiMol on two real-world challenges. First, we enhanced the selectivity of Xanthine Amine Congener (XAC), a promiscuous ligand that binds both A1R and A2AR, successfully biasing it towards A1R. Second, we improved the bioavailability of Saquinavir, an HIV-1 protease inhibitor with known bioavailability limitations. Overall, these results indicate that MultiMol represents a highly promising approach for multi-objective molecular optimization, holding great potential to accelerate the drug development process and contribute to the advancement of pharmaceutical research.
One Head Eight Arms: Block Matrix based Low Rank Adaptation for CLIP-based Few-Shot Learning
Jan 28, 2025



Recent advancements in fine-tuning Vision-Language Foundation Models (VLMs) have garnered significant attention for their effectiveness in downstream few-shot learning tasks.While these recent approaches exhibits some performance improvements, they often suffer from excessive training parameters and high computational costs. To address these challenges, we propose a novel Block matrix-based low-rank adaptation framework, called Block-LoRA, for fine-tuning VLMs on downstream few-shot tasks. Inspired by recent work on Low-Rank Adaptation (LoRA), Block-LoRA partitions the original low-rank decomposition matrix of LoRA into a series of sub-matrices while sharing all down-projection sub-matrices. This structure not only reduces the number of training parameters, but also transforms certain complex matrix multiplication operations into simpler matrix addition, significantly lowering the computational cost of fine-tuning. Notably, Block-LoRA enables fine-tuning CLIP on the ImageNet few-shot benchmark using a single 24GB GPU. We also show that Block-LoRA has the more tighter bound of generalization error than vanilla LoRA. Without bells and whistles, extensive experiments demonstrate that Block-LoRA achieves competitive performance compared to state-of-the-art CLIP-based few-shot methods, while maintaining a low training parameters count and reduced computational overhead.
MetaNeRV: Meta Neural Representations for Videos with Spatial-Temporal Guidance
Jan 05, 2025



Neural Representations for Videos (NeRV) has emerged as a promising implicit neural representation (INR) approach for video analysis, which represents videos as neural networks with frame indexes as inputs. However, NeRV-based methods are time-consuming when adapting to a large number of diverse videos, as each video requires a separate NeRV model to be trained from scratch. In addition, NeRV-based methods spatially require generating a high-dimension signal (i.e., an entire image) from the input of a low-dimension timestamp, and a video typically consists of tens of frames temporally that have a minor change between adjacent frames. To improve the efficiency of video representation, we propose Meta Neural Representations for Videos, named MetaNeRV, a novel framework for fast NeRV representation for unseen videos. MetaNeRV leverages a meta-learning framework to learn an optimal parameter initialization, which serves as a good starting point for adapting to new videos. To address the unique spatial and temporal characteristics of video modality, we further introduce spatial-temporal guidance to improve the representation capabilities of MetaNeRV. Specifically, the spatial guidance with a multi-resolution loss aims to capture the information from different resolution stages, and the temporal guidance with an effective progressive learning strategy could gradually refine the number of fitted frames during the meta-learning process. Extensive experiments conducted on multiple datasets demonstrate the superiority of MetaNeRV for video representations and video compression.
TSINR: Capturing Temporal Continuity via Implicit Neural Representations for Time Series Anomaly Detection
Nov 20, 2024



Time series anomaly detection aims to identify unusual patterns in data or deviations from systems' expected behavior. The reconstruction-based methods are the mainstream in this task, which learn point-wise representation via unsupervised learning. However, the unlabeled anomaly points in training data may cause these reconstruction-based methods to learn and reconstruct anomalous data, resulting in the challenge of capturing normal patterns. In this paper, we propose a time series anomaly detection method based on implicit neural representation (INR) reconstruction, named TSINR, to address this challenge. Due to the property of spectral bias, TSINR enables prioritizing low-frequency signals and exhibiting poorer performance on high-frequency abnormal data. Specifically, we adopt INR to parameterize time series data as a continuous function and employ a transformer-based architecture to predict the INR of given data. As a result, the proposed TSINR method achieves the advantage of capturing the temporal continuity and thus is more sensitive to discontinuous anomaly data. In addition, we further design a novel form of INR continuous function to learn inter- and intra-channel information, and leverage a pre-trained large language model to amplify the intense fluctuations in anomalies. Extensive experiments demonstrate that TSINR achieves superior overall performance on both univariate and multivariate time series anomaly detection benchmarks compared to other state-of-the-art reconstruction-based methods. Our codes are available.