 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Web Accessibility Audit with MLLMs as Copilots
Nov 05, 2025


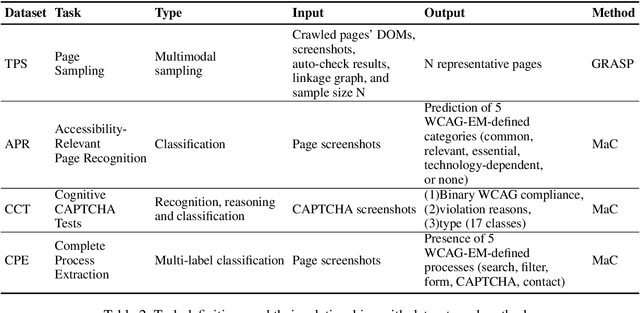
Ensuring web accessibility is crucial for advancing social welfare, justice, and equality in digital spaces, yet the vast majority of website user interfaces remain non-compliant, due in part to the resource-intensive and unscalable nature of current auditing practices. While WCAG-EM offers a structured methodology for site-wise conformance evaluation, it involves great human efforts and lacks practical support for execution at scale. In this work, we present an auditing framework, AAA, which operationalizes WCAG-EM through a human-AI partnership model. AAA is anchored by two key innovations: GRASP, a graph-based multimodal sampling method that ensures representative page coverage via learned embeddings of visual, textual, and relational cues; and MaC, a multimodal large language model-based copilot that supports auditors through cross-modal reasoning and intelligent assistance in high-effort tasks. Together, these components enable scalable, end-to-end web accessibility auditing, empowering human auditors with AI-enhanced assistance for real-world impact. We further contribute four novel datasets designed for benchmarking core stages of the audit pipeline. Extensive experiments demonstrate the effectiveness of our methods, providing insights that small-scale language models can serve as capable experts when fine-tuned.
Multi-Omics Analysis for Cancer Subtype Inference via Unrolling Graph Smoothness Priors
Aug 08, 2025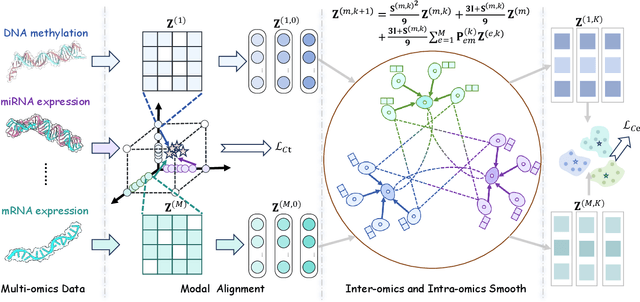
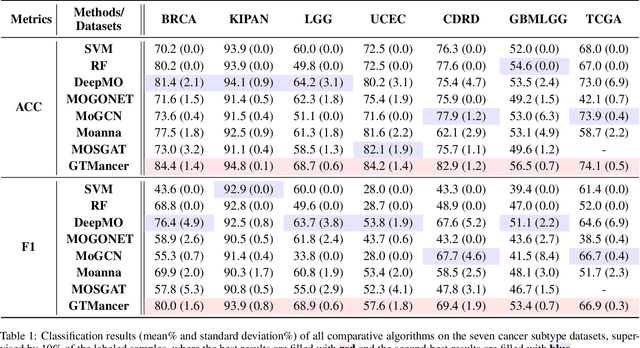
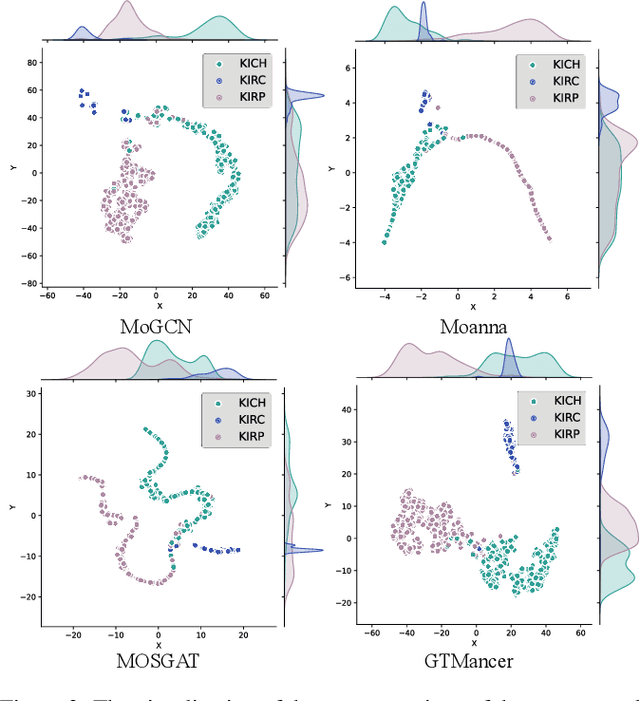
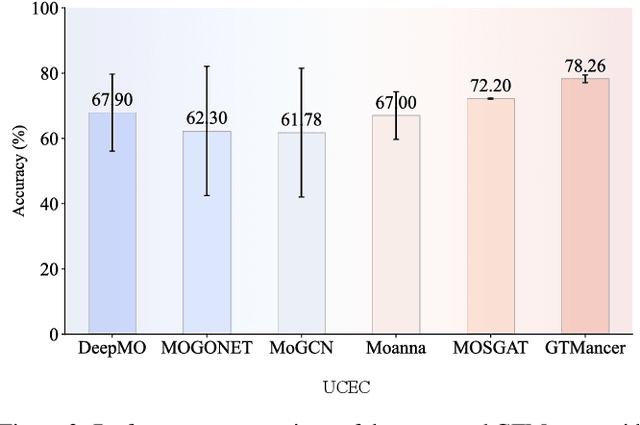
Integrating multi-omics datasets through data-driven analysis offers a comprehensive understanding of the complex biological processes underlying various diseases, particularly cancer. Graph Neural Networks (GNNs) have recently demonstrated remarkable ability to exploit relational structures in biological data, enabling advances in multi-omics integration for cancer subtype classification. Existing approaches often neglect the intricate coupling between heterogeneous omics, limiting their capacity to resolve subtle cancer subtype heterogeneity critical for precision oncology. To address these limitations, we propose a framework named Graph Transformer for Multi-omics Cancer Subtype Classification (GTMancer). This framework builds upon the GNN optimization problem and extends its application to complex multi-omics data. Specifically, our method leverages contrastive learning to embed multi-omics data into a unified semantic space. We unroll the multiplex graph optimization problem in that unified space and introduce dual sets of attention coefficients to capture structural graph priors both within and among multi-omics data. This approach enables global omics information to guide the refining of the representations of individual omics. Empirical experiments on seven real-world cancer datasets demonstrate that GTMancer outperforms existing state-of-the-art algorithms.
OpenGT: A Comprehensive Benchmark For Graph Transformers
Jun 05, 2025Graph Transformers (GTs) have recently demonstrated remarkable performance across diverse domains. By leveraging attention mechanisms, GTs are capable of modeling long-range dependencies and complex structural relationships beyond local neighborhoods. However, their applicable scenarios are still underexplored, this highlights the need to identify when and why they excel. Furthermore, unlike GNNs, which predominantly rely on message-passing mechanisms, GTs exhibit a diverse design space in areas such as positional encoding, attention mechanisms, and graph-specific adaptations. Yet, it remains unclear which of these design choices are truly effective and under what conditions. As a result, the community currently lacks a comprehensive benchmark and library to promote a deeper understanding and further development of GTs. To address this gap, this paper introduces OpenGT, a comprehensive benchmark for Graph Transformers. OpenGT enables fair comparisons and multidimensional analysis by establishing standardized experimental settings and incorporating a broad selection of state-of-the-art GNNs and GTs. Our benchmark evaluates GTs from multiple perspectives, encompassing diverse tasks and datasets with varying properties. Through extensive experiments, our benchmark has uncovered several critical insights, including the difficulty of transferring models across task levels, the limitations of local attention, the efficiency trade-offs in several models, the application scenarios of specific positional encodings, and the preprocessing overhead of some positional encodings. We aspire for this work to establish a foundation for future graph transformer research emphasizing fairness, reproducibility, and generalizability. We have developed an easy-to-use library OpenGT for training and evaluating existing GTs. The benchmark code is available at https://github.com/eaglelab-zju/OpenGT.
ImputeINR: Time Series Imputation via Implicit Neural Representations for Disease Diagnosis with Missing Data
May 16, 2025Healthcare data frequently contain a substantial proportion of missing values, necessitating effective time series imputation to support downstream disease diagnosis tasks. However, existing imputation methods focus on discrete data points and are unable to effectively model sparse data, resulting in particularly poor performance for imputing substantial missing values. In this paper, we propose a novel approach, ImputeINR, for time series imputation by employing implicit neural representations (INR) to learn continuous functions for time series. ImputeINR leverages the merits of INR in that the continuous functions are not coupled to sampling frequency and have infinite sampling frequency, allowing ImputeINR to generate fine-grained imputations even on extremely sparse observed values. Extensive experiments conducted on eight datasets with five ratios of masked values show the superior imputation performance of ImputeINR, especially for high missing ratios in time series data. Furthermore, we validate that applying ImputeINR to impute missing values in healthcare data enhances the performance of downstream disease diagnosis tasks. Codes are available.
FocusedAD: Character-centric Movie Audio Description
Apr 16, 2025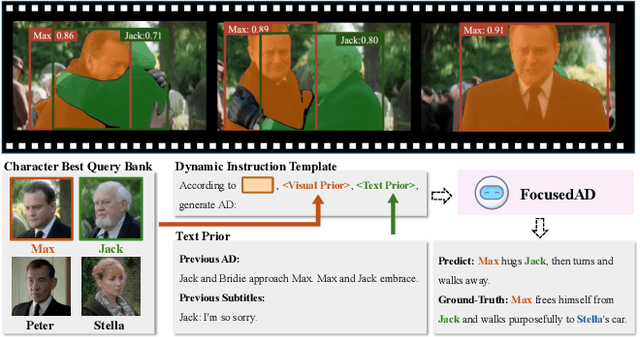
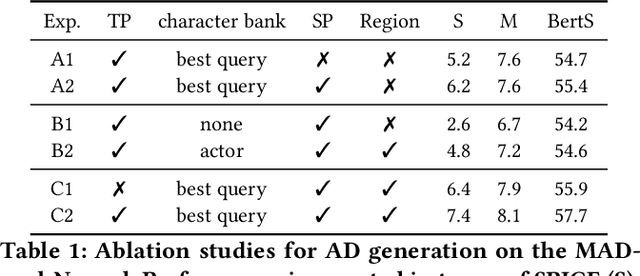
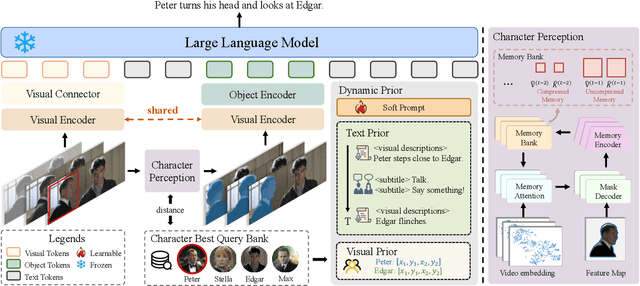
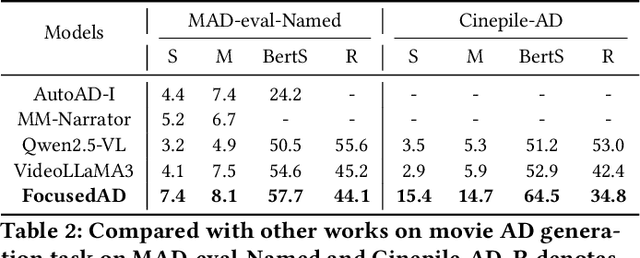
Movie Audio Description (AD) aims to narrate visual content during dialogue-free segments, particularly benefiting blind and visually impaired (BVI) audiences. Compared with general video captioning, AD demands plot-relevant narration with explicit character name references, posing unique challenges in movie understanding.To identify active main characters and focus on storyline-relevant regions, we propose FocusedAD, a novel framework that delivers character-centric movie audio descriptions. It includes: (i) a Character Perception Module(CPM) for tracking character regions and linking them to names; (ii) a Dynamic Prior Module(DPM) that injects contextual cues from prior ADs and subtitles via learnable soft prompts; and (iii) a Focused Caption Module(FCM) that generates narrations enriched with plot-relevant details and named characters. To overcome limitations in character identification, we also introduce an automated pipeline for building character query banks. FocusedAD achieves state-of-the-art performance on multiple benchmarks, including strong zero-shot results on MAD-eval-Named and our newly proposed Cinepile-AD dataset. Code and data will be released at https://github.com/Thorin215/FocusedAD .
MP-GUI: Modality Perception with MLLMs for GUI Understanding
Mar 18, 2025Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.
One Head Eight Arms: Block Matrix based Low Rank Adaptation for CLIP-based Few-Shot Learning
Jan 28, 2025



Recent advancements in fine-tuning Vision-Language Foundation Models (VLMs) have garnered significant attention for their effectiveness in downstream few-shot learning tasks.While these recent approaches exhibits some performance improvements, they often suffer from excessive training parameters and high computational costs. To address these challenges, we propose a novel Block matrix-based low-rank adaptation framework, called Block-LoRA, for fine-tuning VLMs on downstream few-shot tasks. Inspired by recent work on Low-Rank Adaptation (LoRA), Block-LoRA partitions the original low-rank decomposition matrix of LoRA into a series of sub-matrices while sharing all down-projection sub-matrices. This structure not only reduces the number of training parameters, but also transforms certain complex matrix multiplication operations into simpler matrix addition, significantly lowering the computational cost of fine-tuning. Notably, Block-LoRA enables fine-tuning CLIP on the ImageNet few-shot benchmark using a single 24GB GPU. We also show that Block-LoRA has the more tighter bound of generalization error than vanilla LoRA. Without bells and whistles, extensive experiments demonstrate that Block-LoRA achieves competitive performance compared to state-of-the-art CLIP-based few-shot methods, while maintaining a low training parameters count and reduced computational overhead.
MetaNeRV: Meta Neural Representations for Videos with Spatial-Temporal Guidance
Jan 05, 2025



Neural Representations for Videos (NeRV) has emerged as a promising implicit neural representation (INR) approach for video analysis, which represents videos as neural networks with frame indexes as inputs. However, NeRV-based methods are time-consuming when adapting to a large number of diverse videos, as each video requires a separate NeRV model to be trained from scratch. In addition, NeRV-based methods spatially require generating a high-dimension signal (i.e., an entire image) from the input of a low-dimension timestamp, and a video typically consists of tens of frames temporally that have a minor change between adjacent frames. To improve the efficiency of video representation, we propose Meta Neural Representations for Videos, named MetaNeRV, a novel framework for fast NeRV representation for unseen videos. MetaNeRV leverages a meta-learning framework to learn an optimal parameter initialization, which serves as a good starting point for adapting to new videos. To address the unique spatial and temporal characteristics of video modality, we further introduce spatial-temporal guidance to improve the representation capabilities of MetaNeRV. Specifically, the spatial guidance with a multi-resolution loss aims to capture the information from different resolution stages, and the temporal guidance with an effective progressive learning strategy could gradually refine the number of fitted frames during the meta-learning process. Extensive experiments conducted on multiple datasets demonstrate the superiority of MetaNeRV for video representations and video compression.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025
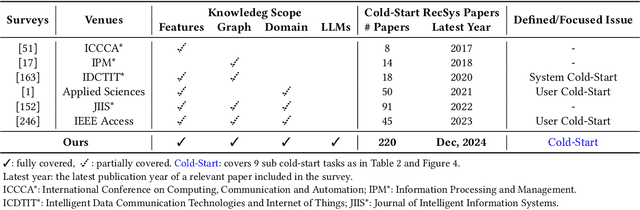
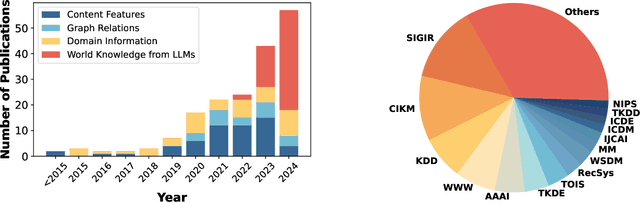
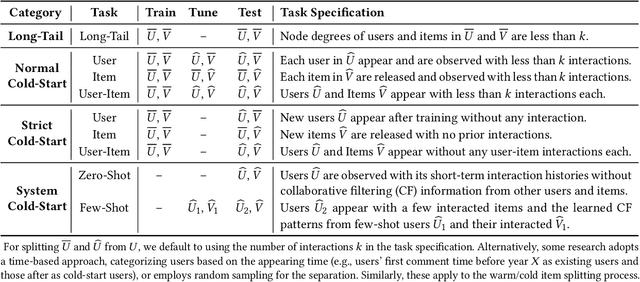
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.
Universal Inceptive GNNs by Eliminating the Smoothness-generalization Dilemma
Dec 13, 2024Graph Neural Networks (GNNs) have demonstrated remarkable success in various domains, such as transaction and social net-works. However, their application is often hindered by the varyinghomophily levels across different orders of neighboring nodes, ne-cessitating separate model designs for homophilic and heterophilicgraphs. In this paper, we aim to develop a unified framework ca-pable of handling neighborhoods of various orders and homophilylevels. Through theoretical exploration, we identify a previouslyoverlooked architectural aspect in multi-hop learning: the cascadedependency, which leads to asmoothness-generalization dilemma.This dilemma significantly affects the learning process, especiallyin the context of high-order neighborhoods and heterophilic graphs.To resolve this issue, we propose an Inceptive Graph Neural Net-work (IGNN), a universal message-passing framework that replacesthe cascade dependency with an inceptive architecture. IGNN pro-vides independent representations for each hop, allowing personal-ized generalization capabilities, and captures neighborhood-wiserelationships to select appropriate receptive fields. Extensive ex-periments show that our IGNN outperforms 23 baseline methods,demonstrating superior performance on both homophilic and het-erophilic graphs, while also scaling efficiently to large graphs.