 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSD-LLM: Predicting Ship Detention in Port State Control Inspections with Large Language Model
May 26, 2025Maritime transportation is the backbone of global trade, making ship inspection essential for ensuring maritime safety and environmental protection. Port State Control (PSC), conducted by national ports, enforces compliance with safety regulations, with ship detention being the most severe consequence, impacting both ship schedules and company reputations. Traditional machine learning methods for ship detention prediction are limited by the capacity of representation learning and thus suffer from low accuracy. Meanwhile, autoencoder-based deep learning approaches face challenges due to the severe data imbalance in learning historical PSC detention records. To address these limitations, we propose Maritime Ship Detention with Large Language Models (MSD-LLM), integrating a dual robust subspace recovery (DSR) layer-based autoencoder with a progressive learning pipeline to handle imbalanced data and extract meaningful PSC representations. Then, a large language model groups and ranks features to identify likely detention cases, enabling dynamic thresholding for flexible detention predictions. Extensive evaluations on 31,707 PSC inspection records from the Asia-Pacific region show that MSD-LLM outperforms state-of-the-art methods more than 12\% on Area Under the Curve (AUC) for Singapore ports. Additionally, it demonstrates robustness to real-world challenges, making it adaptable to diverse maritime risk assessment scenarios.
Aggregated Structural Representation with Large Language Models for Human-Centric Layout Generation
May 26, 2025Time consumption and the complexity of manual layout design make automated layout generation a critical task, especially for multiple applications across different mobile devices. Existing graph-based layout generation approaches suffer from limited generative capability, often resulting in unreasonable and incompatible outputs. Meanwhile, vision based generative models tend to overlook the original structural information, leading to component intersections and overlaps. To address these challenges, we propose an Aggregation Structural Representation (ASR) module that integrates graph networks with large language models (LLMs) to preserve structural information while enhancing generative capability. This novel pipeline utilizes graph features as hierarchical prior knowledge, replacing the traditional Vision Transformer (ViT) module in multimodal large language models (MLLM) to predict full layout information for the first time. Moreover, the intermediate graph matrix used as input for the LLM is human editable, enabling progressive, human centric design generation. A comprehensive evaluation on the RICO dataset demonstrates the strong performance of ASR, both quantitatively using mean Intersection over Union (mIoU), and qualitatively through a crowdsourced user study. Additionally, sampling on relational features ensures diverse layout generation, further enhancing the adaptability and creativity of the proposed approach.
MP-GUI: Modality Perception with MLLMs for GUI Understanding
Mar 18, 2025Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.
MobileFlow: A Multimodal LLM For Mobile GUI Agent
Jul 05, 2024Currently, the integration of mobile Graphical User Interfaces (GUIs) is ubiquitous in most people's daily lives. And the ongoing evolution of multimodal large-scale models, such as GPT-4v, Qwen-VL-Max, has significantly bolstered the capabilities of GUI comprehension and user action analysis, showcasing the potentiality of intelligent GUI assistants. However, current GUI Agents often need to access page layout information through calling system APIs, which may pose privacy risks. Fixing GUI (such as mobile interfaces) to a certain low resolution might result in the loss of fine-grained image details. At the same time, the multimodal large models built for GUI Agents currently have poor understanding and decision-making abilities for Chinese GUI interfaces, making them difficult to apply to a large number of Chinese apps. This paper introduces MobileFlow, a multimodal large language model meticulously crafted for mobile GUI agents. Transforming from the open-source model Qwen-VL-Chat into GUI domain, MobileFlow contains approximately 21 billion parameters and is equipped with novel hybrid visual encoders, making it possible for variable resolutions of image inputs and good support for multilingual GUI. By incorporating Mixture of Experts (MoE) expansions and pioneering alignment training strategies, MobileFlow has the capacity to fully interpret image data and comprehend user instructions for GUI interaction tasks. Finally, MobileFlow outperforms Qwen-VL-Max and GPT-4v in terms of task execution by GUI agents on both public and our proposed evaluation metrics, and has been successfully deployed in real-world business contexts, proving its effectiveness for practical applications.
PREMA: Part-based REcurrent Multi-view Aggregation Network for 3D Shape Retrieval
Nov 09, 2021



We propose the Part-based Recurrent Multi-view Aggregation network(PREMA) to eliminate the detrimental effects of the practical view defects, such as insufficient view numbers, occlusions or background clutters, and also enhance the discriminative ability of shape representations. Inspired by the fact that human recognize an object mainly by its discriminant parts, we define the multi-view coherent part(MCP), a discriminant part reoccurring in different views. Our PREMA can reliably locate and effectively utilize MCPs to build robust shape representations. Comprehensively, we design a novel Regional Attention Unit(RAU) in PREMA to compute the confidence map for each view, and extract MCPs by applying those maps to view features. PREMA accentuates MCPs via correlating features of different views, and aggregates the part-aware features for shape representation.
RaidaR: A Rich Annotated Image Dataset of Rainy Street Scenes
Apr 09, 2021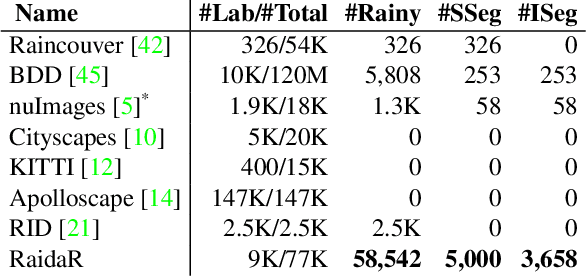

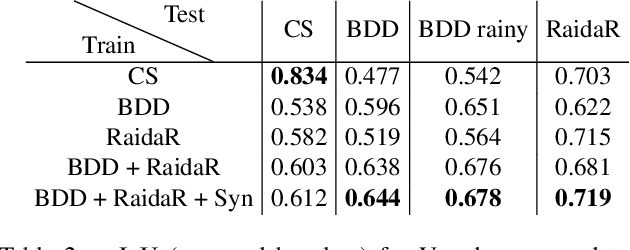

We introduce RaidaR, a rich annotated image dataset of rainy street scenes, to support autonomous driving research. The new dataset contains the largest number of rainy images (58,542) to date, 5,000 of which provide semantic segmentations and 3,658 provide object instance segmentations. The RaidaR images cover a wide range of realistic rain-induced artifacts, including fog, droplets, and road reflections, which can effectively augment existing street scene datasets to improve data-driven machine perception during rainy weather. To facilitate efficient annotation of a large volume of images, we develop a semi-automatic scheme combining manual segmentation and an automated processing akin to cross validation, resulting in 10-20 fold reduction on annotation time. We demonstrate the utility of our new dataset by showing how data augmentation with RaidaR can elevate the accuracy of existing segmentation algorithms. We also present a novel unpaired image-to-image translation algorithm for adding/removing rain artifacts, which directly benefits from RaidaR.
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 28, 2019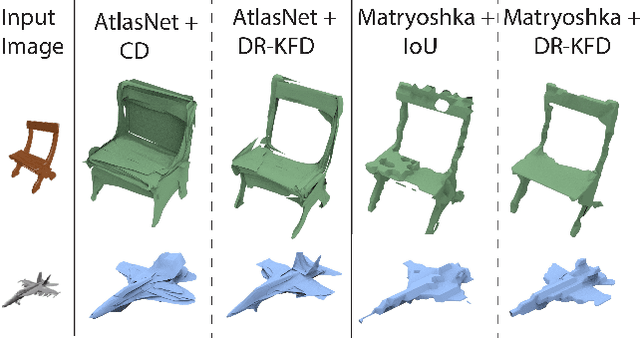
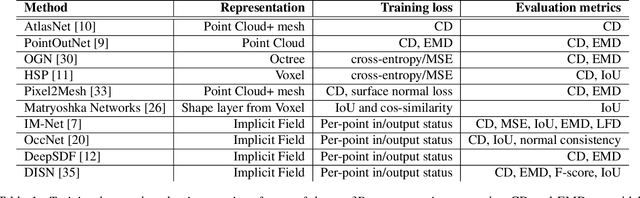
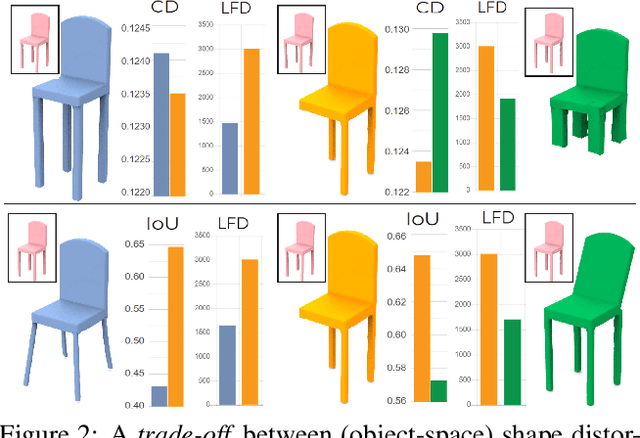
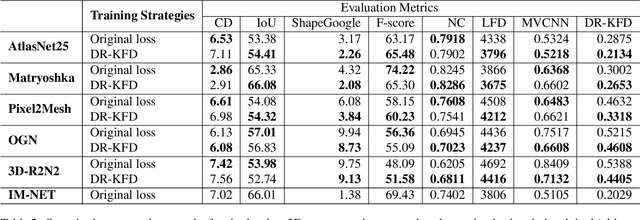
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.