 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntwisting RoPE: Frequency Control for Shared Attention in DiTs
Feb 04, 2026Positional encodings are essential to transformer-based generative models, yet their behavior in multimodal and attention-sharing settings is not fully understood. In this work, we present a principled analysis of Rotary Positional Embeddings (RoPE), showing that RoPE naturally decomposes into frequency components with distinct positional sensitivities. We demonstrate that this frequency structure explains why shared-attention mechanisms, where a target image is generated while attending to tokens from a reference image, can lead to reference copying, in which the model reproduces content from the reference instead of extracting only its stylistic cues. Our analysis reveals that the high-frequency components of RoPE dominate the attention computation, forcing queries to attend mainly to spatially aligned reference tokens and thereby inducing this unintended copying behavior. Building on these insights, we introduce a method for selectively modulating RoPE frequency bands so that attention reflects semantic similarity rather than strict positional alignment. Applied to modern transformer-based diffusion architectures, where all tokens share attention, this modulation restores stable and meaningful shared attention. As a result, it enables effective control over the degree of style transfer versus content copying, yielding a proper style-aligned generation process in which stylistic attributes are transferred without duplicating reference content.
Advances in 4D Representation: Geometry, Motion, and Interaction
Oct 22, 2025We present a survey on 4D generation and reconstruction, a fast-evolving subfield of computer graphics whose developments have been propelled by recent advances in neural fields, geometric and motion deep learning, as well 3D generative artificial intelligence (GenAI). While our survey is not the first of its kind, we build our coverage of the domain from a unique and distinctive perspective of 4D representations\/}, to model 3D geometry evolving over time while exhibiting motion and interaction. Specifically, instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios. The main take-away message we aim to convey to the readers is on how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions. Throughout our survey, we will reprise the role of large language models (LLMs) and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide a dedicated coverage on what 4D datasets are currently available, as well as what is lacking, in driving the subfield forward. Project page:https://mingrui-zhao.github.io/4DRep-GMI/
Cora: Correspondence-aware image editing using few step diffusion
May 29, 2025Image editing is an important task in computer graphics, vision, and VFX, with recent diffusion-based methods achieving fast and high-quality results. However, edits requiring significant structural changes, such as non-rigid deformations, object modifications, or content generation, remain challenging. Existing few step editing approaches produce artifacts such as irrelevant texture or struggle to preserve key attributes of the source image (e.g., pose). We introduce Cora, a novel editing framework that addresses these limitations by introducing correspondence-aware noise correction and interpolated attention maps. Our method aligns textures and structures between the source and target images through semantic correspondence, enabling accurate texture transfer while generating new content when necessary. Cora offers control over the balance between content generation and preservation. Extensive experiments demonstrate that, quantitatively and qualitatively, Cora excels in maintaining structure, textures, and identity across diverse edits, including pose changes, object addition, and texture refinements. User studies confirm that Cora delivers superior results, outperforming alternatives.
ACT-R: Adaptive Camera Trajectories for 3D Reconstruction from Single Image
May 13, 2025We introduce adaptive view planning to multi-view synthesis, aiming to improve both occlusion revelation and 3D consistency for single-view 3D reconstruction. Instead of generating an unordered set of views independently or simultaneously, we generate a sequence of views, leveraging temporal consistency to enhance 3D coherence. Most importantly, our view sequence is not determined by a pre-determined camera setup. Instead, we compute an adaptive camera trajectory (ACT), specifically, an orbit of camera views, which maximizes the visibility of occluded regions of the 3D object to be reconstructed. Once the best orbit is found, we feed it to a video diffusion model to generate novel views around the orbit, which in turn, are passed to a multi-view 3D reconstruction model to obtain the final reconstruction. Our multi-view synthesis pipeline is quite efficient since it involves no run-time training/optimization, only forward inferences by applying the pre-trained models for occlusion analysis and multi-view synthesis. Our method predicts camera trajectories that reveal occlusions effectively and produce consistent novel views, significantly improving 3D reconstruction over SOTA on the unseen GSO dataset, both quantitatively and qualitatively.
Learning What NOT to Count
Apr 16, 2025Few/zero-shot object counting methods reduce the need for extensive annotations but often struggle to distinguish between fine-grained categories, especially when multiple similar objects appear in the same scene. To address this limitation, we propose an annotation-free approach that enables the seamless integration of new fine-grained categories into existing few/zero-shot counting models. By leveraging latent generative models, we synthesize high-quality, category-specific crowded scenes, providing a rich training source for adapting to new categories without manual labeling. Our approach introduces an attention prediction network that identifies fine-grained category boundaries trained using only synthetic pseudo-annotated data. At inference, these fine-grained attention estimates refine the output of existing few/zero-shot counting networks. To benchmark our method, we further introduce the FGTC dataset, a taxonomy-specific fine-grained object counting dataset for natural images. Our method substantially enhances pre-trained state-of-the-art models on fine-grained taxon counting tasks, while using only synthetic data. Code and data to be released upon acceptance.
In-2-4D: Inbetweening from Two Single-View Images to 4D Generation
Apr 11, 2025
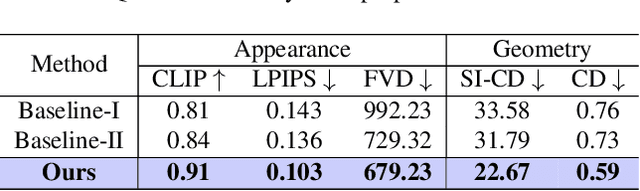

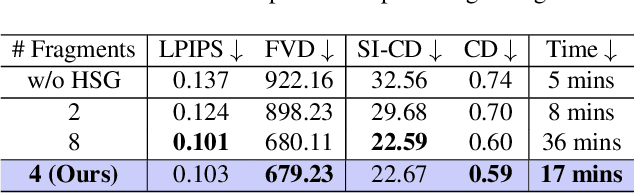
We propose a new problem, In-2-4D, for generative 4D (i.e., 3D + motion) inbetweening from a minimalistic input setting: two single-view images capturing an object in two distinct motion states. Given two images representing the start and end states of an object in motion, our goal is to generate and reconstruct the motion in 4D. We utilize a video interpolation model to predict the motion, but large frame-to-frame motions can lead to ambiguous interpretations. To overcome this, we employ a hierarchical approach to identify keyframes that are visually close to the input states and show significant motion, then generate smooth fragments between them. For each fragment, we construct the 3D representation of the keyframe using Gaussian Splatting. The temporal frames within the fragment guide the motion, enabling their transformation into dynamic Gaussians through a deformation field. To improve temporal consistency and refine 3D motion, we expand the self-attention of multi-view diffusion across timesteps and apply rigid transformation regularization. Finally, we merge the independently generated 3D motion segments by interpolating boundary deformation fields and optimizing them to align with the guiding video, ensuring smooth and flicker-free transitions. Through extensive qualitative and quantitiave experiments as well as a user study, we show the effectiveness of our method and its components. The project page is available at https://in-2-4d.github.io/
SINGAPO: Single Image Controlled Generation of Articulated Parts in Object
Oct 21, 2024
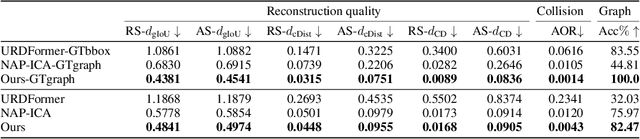


We address the challenge of creating 3D assets for household articulated objects from a single image. Prior work on articulated object creation either requires multi-view multi-state input, or only allows coarse control over the generation process. These limitations hinder the scalability and practicality for articulated object modeling. In this work, we propose a method to generate articulated objects from a single image. Observing the object in resting state from an arbitrary view, our method generates an articulated object that is visually consistent with the input image. To capture the ambiguity in part shape and motion posed by a single view of the object, we design a diffusion model that learns the plausible variations of objects in terms of geometry and kinematics. To tackle the complexity of generating structured data with attributes in multiple domains, we design a pipeline that produces articulated objects from high-level structure to geometric details in a coarse-to-fine manner, where we use a part connectivity graph and part abstraction as proxies. Our experiments show that our method outperforms the state-of-the-art in articulated object creation by a large margin in terms of the generated object realism, resemblance to the input image, and reconstruction quality.
SweepNet: Unsupervised Learning Shape Abstraction via Neural Sweepers
Jul 08, 2024

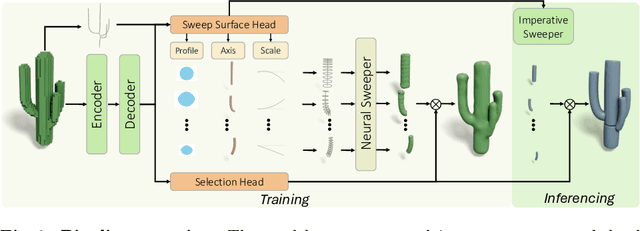

Shape abstraction is an important task for simplifying complex geometric structures while retaining essential features. Sweep surfaces, commonly found in human-made objects, aid in this process by effectively capturing and representing object geometry, thereby facilitating abstraction. In this paper, we introduce \papername, a novel approach to shape abstraction through sweep surfaces. We propose an effective parameterization for sweep surfaces, utilizing superellipses for profile representation and B-spline curves for the axis. This compact representation, requiring as few as 14 float numbers, facilitates intuitive and interactive editing while preserving shape details effectively. Additionally, by introducing a differentiable neural sweeper and an encoder-decoder architecture, we demonstrate the ability to predict sweep surface representations without supervision. We show the superiority of our model through several quantitative and qualitative experiments throughout the paper. Our code is available at https://mingrui-zhao.github.io/SweepNet/
pOps: Photo-Inspired Diffusion Operators
Jun 03, 2024Text-guided image generation enables the creation of visual content from textual descriptions. However, certain visual concepts cannot be effectively conveyed through language alone. This has sparked a renewed interest in utilizing the CLIP image embedding space for more visually-oriented tasks through methods such as IP-Adapter. Interestingly, the CLIP image embedding space has been shown to be semantically meaningful, where linear operations within this space yield semantically meaningful results. Yet, the specific meaning of these operations can vary unpredictably across different images. To harness this potential, we introduce pOps, a framework that trains specific semantic operators directly on CLIP image embeddings. Each pOps operator is built upon a pretrained Diffusion Prior model. While the Diffusion Prior model was originally trained to map between text embeddings and image embeddings, we demonstrate that it can be tuned to accommodate new input conditions, resulting in a diffusion operator. Working directly over image embeddings not only improves our ability to learn semantic operations but also allows us to directly use a textual CLIP loss as an additional supervision when needed. We show that pOps can be used to learn a variety of photo-inspired operators with distinct semantic meanings, highlighting the semantic diversity and potential of our proposed approach.
EASI-Tex: Edge-Aware Mesh Texturing from Single Image
May 27, 2024

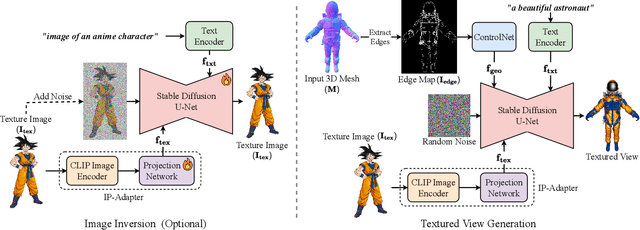
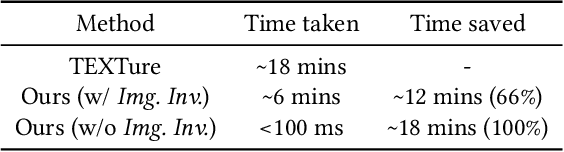
We present a novel approach for single-image mesh texturing, which employs a diffusion model with judicious conditioning to seamlessly transfer an object's texture from a single RGB image to a given 3D mesh object. We do not assume that the two objects belong to the same category, and even if they do, there can be significant discrepancies in their geometry and part proportions. Our method aims to rectify the discrepancies by conditioning a pre-trained Stable Diffusion generator with edges describing the mesh through ControlNet, and features extracted from the input image using IP-Adapter to generate textures that respect the underlying geometry of the mesh and the input texture without any optimization or training. We also introduce Image Inversion, a novel technique to quickly personalize the diffusion model for a single concept using a single image, for cases where the pre-trained IP-Adapter falls short in capturing all the details from the input image faithfully. Experimental results demonstrate the efficiency and effectiveness of our edge-aware single-image mesh texturing approach, coined EASI-Tex, in preserving the details of the input texture on diverse 3D objects, while respecting their geometry.