 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionBridge: Dynamic Video Inbetweening with Flexible Controls
Dec 17, 2024



By generating plausible and smooth transitions between two image frames, video inbetweening is an essential tool for video editing and long video synthesis. Traditional works lack the capability to generate complex large motions. While recent video generation techniques are powerful in creating high-quality results, they often lack fine control over the details of intermediate frames, which can lead to results that do not align with the creative mind. We introduce MotionBridge, a unified video inbetweening framework that allows flexible controls, including trajectory strokes, keyframes, masks, guide pixels, and text. However, learning such multi-modal controls in a unified framework is a challenging task. We thus design two generators to extract the control signal faithfully and encode feature through dual-branch embedders to resolve ambiguities. We further introduce a curriculum training strategy to smoothly learn various controls. Extensive qualitative and quantitative experiments have demonstrated that such multi-modal controls enable a more dynamic, customizable, and contextually accurate visual narrative.
AnaMoDiff: 2D Analogical Motion Diffusion via Disentangled Denoising
Feb 05, 2024We present AnaMoDiff, a novel diffusion-based method for 2D motion analogies that is applied to raw, unannotated videos of articulated characters. Our goal is to accurately transfer motions from a 2D driving video onto a source character, with its identity, in terms of appearance and natural movement, well preserved, even when there may be significant discrepancies between the source and driving characters in their part proportions and movement speed and styles. Our diffusion model transfers the input motion via a latent optical flow (LOF) network operating in a noised latent space, which is spatially aware, efficient to process compared to the original RGB videos, and artifact-resistant through the diffusion denoising process even amid dense movements. To accomplish both motion analogy and identity preservation, we train our denoising model in a feature-disentangled manner, operating at two noise levels. While identity-revealing features of the source are learned via conventional noise injection, motion features are learned from LOF-warped videos by only injecting noise with large values, with the stipulation that motion properties involving pose and limbs are encoded by higher-level features. Experiments demonstrate that our method achieves the best trade-off between motion analogy and identity preservation.
DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion
Mar 16, 2023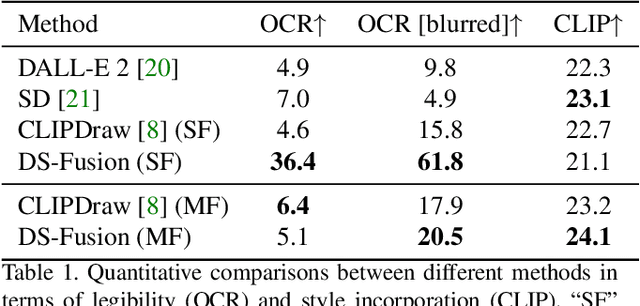
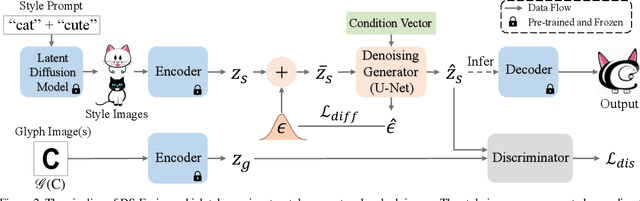
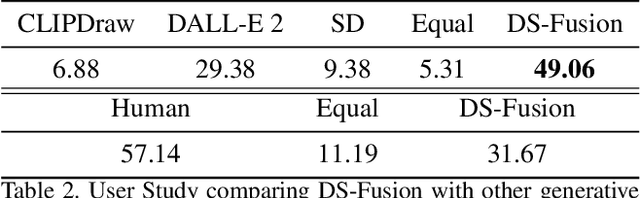
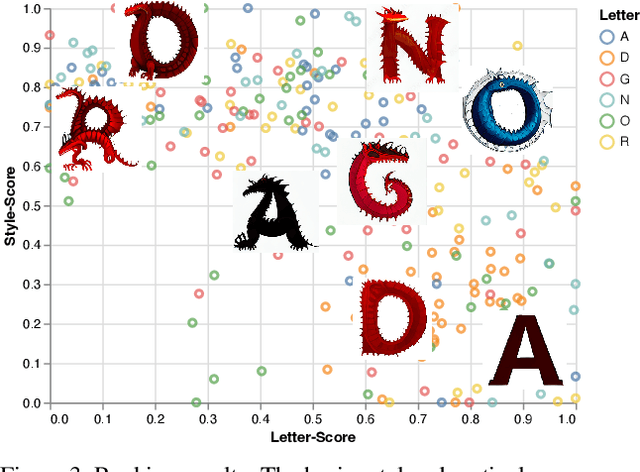
We introduce a novel method to automatically generate an artistic typography by stylizing one or more letter fonts to visually convey the semantics of an input word, while ensuring that the output remains readable. To address an assortment of challenges with our task at hand including conflicting goals (artistic stylization vs. legibility), lack of ground truth, and immense search space, our approach utilizes large language models to bridge texts and visual images for stylization and build an unsupervised generative model with a diffusion model backbone. Specifically, we employ the denoising generator in Latent Diffusion Model (LDM), with the key addition of a CNN-based discriminator to adapt the input style onto the input text. The discriminator uses rasterized images of a given letter/word font as real samples and output of the denoising generator as fake samples. Our model is coined DS-Fusion for discriminated and stylized diffusion. We showcase the quality and versatility of our method through numerous examples, qualitative and quantitative evaluation, as well as ablation studies. User studies comparing to strong baselines including CLIPDraw and DALL-E 2, as well as artist-crafted typographies, demonstrate strong performance of DS-Fusion.
DualCSG: Learning Dual CSG Trees for General and Compact CAD Modeling
Jan 27, 2023We present DualCSG, a novel neural network composed of two dual and complementary branches for unsupervised learning of constructive solid geometry (CSG) representations of 3D CAD shapes. Our network is trained to reconstruct a given 3D CAD shape through a compact assembly of quadric surface primitives via fixed-order CSG operations along two branches. The key difference between our method and all previous neural CSG models is that DualCSG has a dedicated branch, the residual branch, to assemble the potentially complex, complement or residual shape that is to be subtracted from an overall cover shape. The cover shape is modeled by the other branch, the cover branch. Both branches construct a union of primitive intersections, where the only difference is that the residual branch also learns primitive inverses while operating in the complement space. With the shape complements, our network is provably general. We demonstrate both quantitatively and qualitatively that our network produces CSG reconstructions with superior quality, more natural trees, and better quality-compactness tradeoff than all existing alternatives, especially over complex and high-genus CAD shapes.