 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
MotionBridge: Dynamic Video Inbetweening with Flexible Controls
Dec 17, 2024



By generating plausible and smooth transitions between two image frames, video inbetweening is an essential tool for video editing and long video synthesis. Traditional works lack the capability to generate complex large motions. While recent video generation techniques are powerful in creating high-quality results, they often lack fine control over the details of intermediate frames, which can lead to results that do not align with the creative mind. We introduce MotionBridge, a unified video inbetweening framework that allows flexible controls, including trajectory strokes, keyframes, masks, guide pixels, and text. However, learning such multi-modal controls in a unified framework is a challenging task. We thus design two generators to extract the control signal faithfully and encode feature through dual-branch embedders to resolve ambiguities. We further introduce a curriculum training strategy to smoothly learn various controls. Extensive qualitative and quantitative experiments have demonstrated that such multi-modal controls enable a more dynamic, customizable, and contextually accurate visual narrative.
Benchmarking Video Frame Interpolation
Mar 25, 2024



Video frame interpolation, the task of synthesizing new frames in between two or more given ones, is becoming an increasingly popular research target. However, the current evaluation of frame interpolation techniques is not ideal. Due to the plethora of test datasets available and inconsistent computation of error metrics, a coherent and fair comparison across papers is very challenging. Furthermore, new test sets have been proposed as part of method papers so they are unable to provide the in-depth evaluation of a dedicated benchmarking paper. Another severe downside is that these test sets violate the assumption of linearity when given two input frames, making it impossible to solve without an oracle. We hence strongly believe that the community would greatly benefit from a benchmarking paper, which is what we propose. Specifically, we present a benchmark which establishes consistent error metrics by utilizing a submission website that computes them, provides insights by analyzing the interpolation quality with respect to various per-pixel attributes such as the motion magnitude, contains a carefully designed test set adhering to the assumption of linearity by utilizing synthetic data, and evaluates the computational efficiency in a coherent manner.
Explorative Inbetweening of Time and Space
Mar 21, 2024



We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.
Fast View Synthesis of Casual Videos
Dec 04, 2023Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
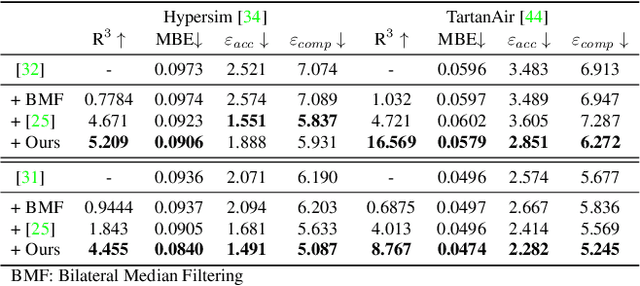
Video Frame Interpolation with Many-to-many Splatting and Spatial Selective Refinement
Oct 29, 2023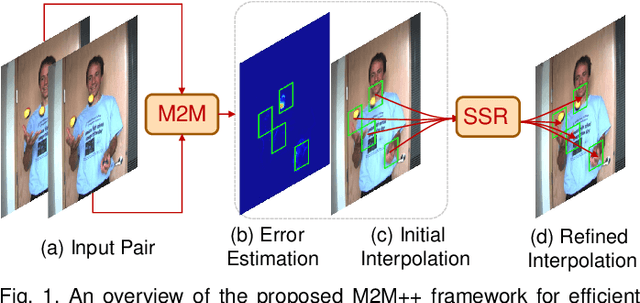
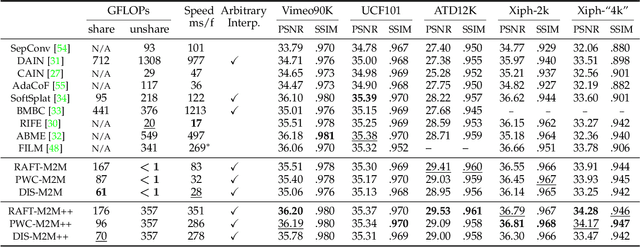
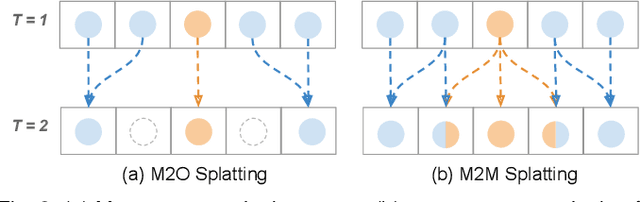
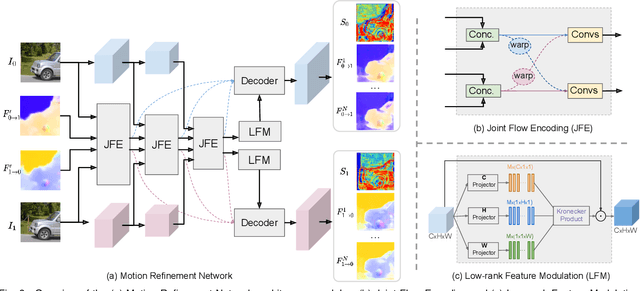
In this work, we first propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step before fusing overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context, establishing a many-to-many splatting scheme with robustness to undesirable artifacts. For each input frame pair, M2M has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. However, directly warping and fusing pixels in the intensity domain is sensitive to the quality of motion estimation and may suffer from less effective representation capacity. To improve interpolation accuracy, we further extend an M2M++ framework by introducing a flexible Spatial Selective Refinement (SSR) component, which allows for trading computational efficiency for interpolation quality and vice versa. Instead of refining the entire interpolated frame, SSR only processes difficult regions selected under the guidance of an estimated error map, thereby avoiding redundant computation. Evaluation on multiple benchmark datasets shows that our method is able to improve the efficiency while maintaining competitive video interpolation quality, and it can be adjusted to use more or less compute as needed.
Towards Domain-agnostic Depth Completion
Jul 29, 2022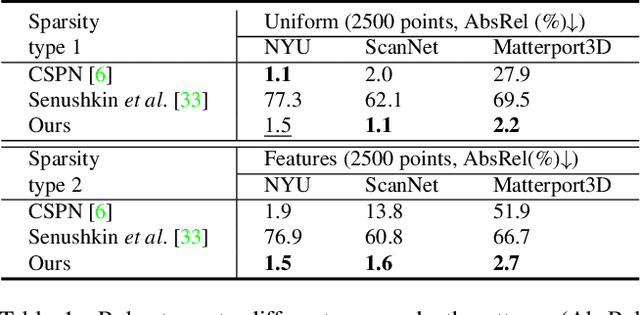


Existing depth completion methods are often targeted at a specific sparse depth type, and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and the robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high quality depth capture on a mobile device. Code is available at: https://github.com/YvanYin/FillDepth.
Layered Depth Refinement with Mask Guidance
Jun 07, 2022
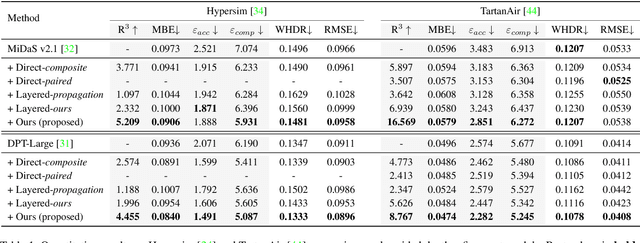
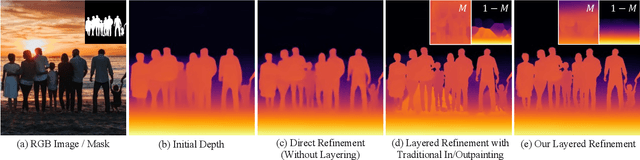
Depth maps are used in a wide range of applications from 3D rendering to 2D image effects such as Bokeh. However, those predicted by single image depth estimation (SIDE) models often fail to capture isolated holes in objects and/or have inaccurate boundary regions. Meanwhile, high-quality masks are much easier to obtain, using commercial auto-masking tools or off-the-shelf methods of segmentation and matting or even by manual editing. Hence, in this paper, we formulate a novel problem of mask-guided depth refinement that utilizes a generic mask to refine the depth prediction of SIDE models. Our framework performs layered refinement and inpainting/outpainting, decomposing the depth map into two separate layers signified by the mask and the inverse mask. As datasets with both depth and mask annotations are scarce, we propose a self-supervised learning scheme that uses arbitrary masks and RGB-D datasets. We empirically show that our method is robust to different types of masks and initial depth predictions, accurately refining depth values in inner and outer mask boundary regions. We further analyze our model with an ablation study and demonstrate results on real applications. More information can be found at https://sooyekim.github.io/MaskDepth/ .
Many-to-many Splatting for Efficient Video Frame Interpolation
Apr 07, 2022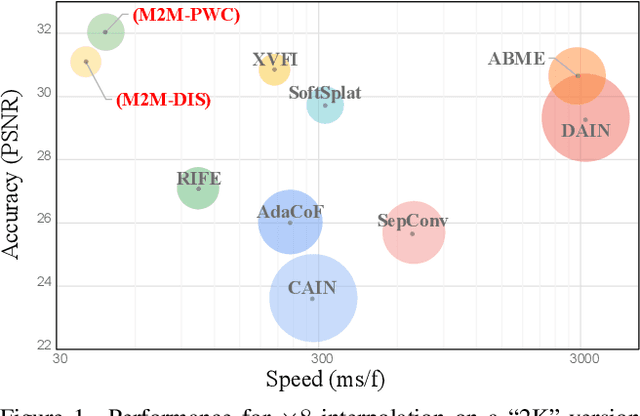
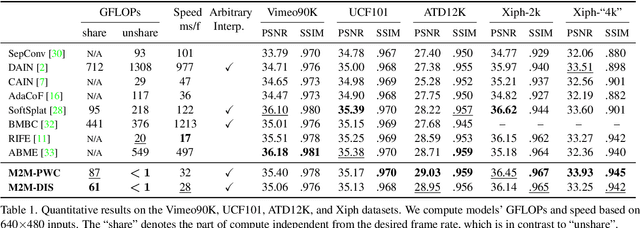
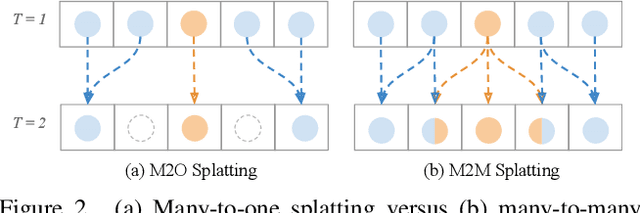
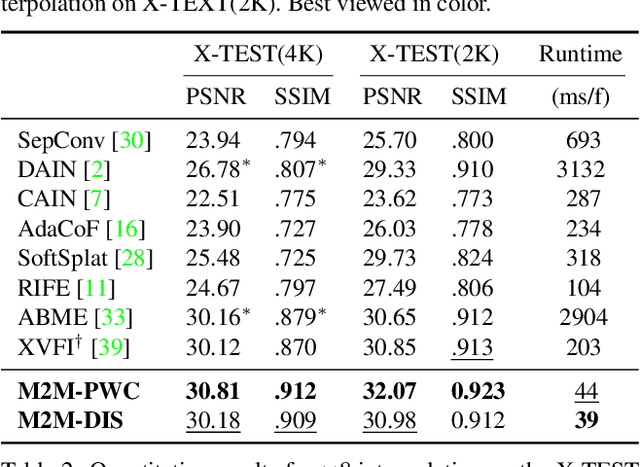
Motion-based video frame interpolation commonly relies on optical flow to warp pixels from the inputs to the desired interpolation instant. Yet due to the inherent challenges of motion estimation (e.g. occlusions and discontinuities), most state-of-the-art interpolation approaches require subsequent refinement of the warped result to generate satisfying outputs, which drastically decreases the efficiency for multi-frame interpolation. In this work, we propose a fully differentiable Many-to-Many (M2M) splatting framework to interpolate frames efficiently. Specifically, given a frame pair, we estimate multiple bidirectional flows to directly forward warp the pixels to the desired time step, and then fuse any overlapping pixels. In doing so, each source pixel renders multiple target pixels and each target pixel can be synthesized from a larger area of visual context. This establishes a many-to-many splatting scheme with robustness to artifacts like holes. Moreover, for each input frame pair, M2M only performs motion estimation once and has a minuscule computational overhead when interpolating an arbitrary number of in-between frames, hence achieving fast multi-frame interpolation. We conducted extensive experiments to analyze M2M, and found that it significantly improves efficiency while maintaining high effectiveness.
Splatting-based Synthesis for Video Frame Interpolation
Jan 25, 2022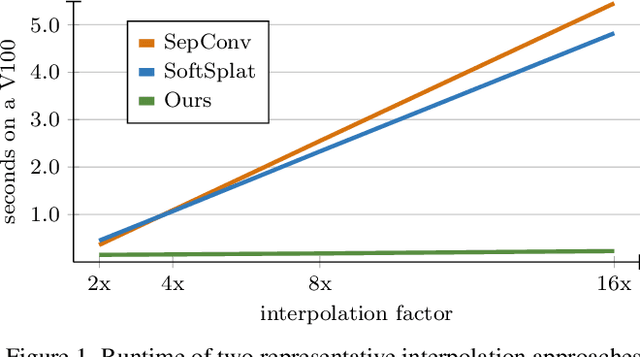


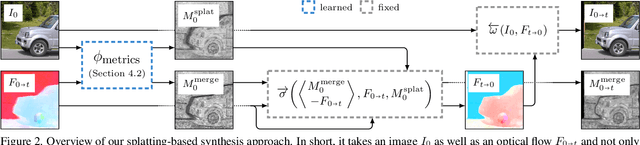
Frame interpolation is an essential video processing technique that adjusts the temporal resolution of an image sequence. An effective approach to perform frame interpolation is based on splatting, also known as forward warping. Specifically, splatting can be used to warp the input images to an arbitrary temporal location based on an optical flow estimate. A synthesis network, also sometimes referred to as refinement network, can then be used to generate the output frame from the warped images. In doing so, it is common to not only warp the images but also various feature representations which provide rich contextual cues to the synthesis network. However, while this approach has been shown to work well and enables arbitrary-time interpolation due to using splatting, the involved synthesis network is prohibitively slow. In contrast, we propose to solely rely on splatting to synthesize the output without any subsequent refinement. This splatting-based synthesis is much faster than similar approaches, especially for multi-frame interpolation, while enabling new state-of-the-art results at high resolutions.