 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Reconfiguration Planning for Deformable Quadrilateral Modular Robots
Jan 27, 2026For lattice modular self-reconfigurable robots (MSRRs), maintaining stable connections during reconfiguration is crucial for physical feasibility and deployability. This letter presents a novel self-reconfiguration planning algorithm for deformable quadrilateral MSRRs that guarantees stable connection. The method first constructs feasible connect/disconnect actions using a virtual graph representation, and then organizes these actions into a valid execution sequence through a Dependence-based Reverse Tree (DRTree) that resolves interdependencies. We also prove that reconfiguration sequences satisfying motion characteristics exist for any pair of configurations with seven or more modules (excluding linear topologies). Finally, comparisons with a modified BiRRT algorithm highlight the superior efficiency and stability of our approach, while deployment on a physical robotic platform confirms its practical feasibility.
Rhombot: Rhombus-shaped Modular Robots for Stable, Medium-Independent Reconfiguration Motion
Jan 27, 2026In this paper, we present Rhombot, a novel deformable planar lattice modular self-reconfigurable robot (MSRR) with a rhombus shaped module. Each module consists of a parallelogram skeleton with a single centrally mounted actuator that enables folding and unfolding along its diagonal. The core design philosophy is to achieve essential MSRR functionalities such as morphing, docking, and locomotion with minimal control complexity. This enables a continuous and stable reconfiguration process that is independent of the surrounding medium, allowing the system to reliably form various configurations in diverse environments. To leverage the unique kinematics of Rhombot, we introduce morphpivoting, a novel motion primitive for reconfiguration that differs from advanced MSRR systems, and propose a strategy for its continuous execution. Finally, a series of physical experiments validate the module's stable reconfiguration ability, as well as its positional and docking accuracy.
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
LEDiff: Latent Exposure Diffusion for HDR Generation
Dec 19, 2024While consumer displays increasingly support more than 10 stops of dynamic range, most image assets such as internet photographs and generative AI content remain limited to 8-bit low dynamic range (LDR), constraining their utility across high dynamic range (HDR) applications. Currently, no generative model can produce high-bit, high-dynamic range content in a generalizable way. Existing LDR-to-HDR conversion methods often struggle to produce photorealistic details and physically-plausible dynamic range in the clipped areas. We introduce LEDiff, a method that enables a generative model with HDR content generation through latent space fusion inspired by image-space exposure fusion techniques. It also functions as an LDR-to-HDR converter, expanding the dynamic range of existing low-dynamic range images. Our approach uses a small HDR dataset to enable a pretrained diffusion model to recover detail and dynamic range in clipped highlights and shadows. LEDiff brings HDR capabilities to existing generative models and converts any LDR image to HDR, creating photorealistic HDR outputs for image generation, image-based lighting (HDR environment map generation), and photographic effects such as depth of field simulation, where linear HDR data is essential for realistic quality.
Instruction-based Image Manipulation by Watching How Things Move
Dec 16, 2024



This paper introduces a novel dataset construction pipeline that samples pairs of frames from videos and uses multimodal large language models (MLLMs) to generate editing instructions for training instruction-based image manipulation models. Video frames inherently preserve the identity of subjects and scenes, ensuring consistent content preservation during editing. Additionally, video data captures diverse, natural dynamics-such as non-rigid subject motion and complex camera movements-that are difficult to model otherwise, making it an ideal source for scalable dataset construction. Using this approach, we create a new dataset to train InstructMove, a model capable of instruction-based complex manipulations that are difficult to achieve with synthetically generated datasets. Our model demonstrates state-of-the-art performance in tasks such as adjusting subject poses, rearranging elements, and altering camera perspectives.
Explorative Inbetweening of Time and Space
Mar 21, 2024



We introduce bounded generation as a generalized task to control video generation to synthesize arbitrary camera and subject motion based only on a given start and end frame. Our objective is to fully leverage the inherent generalization capability of an image-to-video model without additional training or fine-tuning of the original model. This is achieved through the proposed new sampling strategy, which we call Time Reversal Fusion, that fuses the temporally forward and backward denoising paths conditioned on the start and end frame, respectively. The fused path results in a video that smoothly connects the two frames, generating inbetweening of faithful subject motion, novel views of static scenes, and seamless video looping when the two bounding frames are identical. We curate a diverse evaluation dataset of image pairs and compare against the closest existing methods. We find that Time Reversal Fusion outperforms related work on all subtasks, exhibiting the ability to generate complex motions and 3D-consistent views guided by bounded frames. See project page at https://time-reversal.github.io.
Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos
Mar 19, 2024



We propose a generative model that, given a coarsely edited image, synthesizes a photorealistic output that follows the prescribed layout. Our method transfers fine details from the original image and preserves the identity of its parts. Yet, it adapts it to the lighting and context defined by the new layout. Our key insight is that videos are a powerful source of supervision for this task: objects and camera motions provide many observations of how the world changes with viewpoint, lighting, and physical interactions. We construct an image dataset in which each sample is a pair of source and target frames extracted from the same video at randomly chosen time intervals. We warp the source frame toward the target using two motion models that mimic the expected test-time user edits. We supervise our model to translate the warped image into the ground truth, starting from a pretrained diffusion model. Our model design explicitly enables fine detail transfer from the source frame to the generated image, while closely following the user-specified layout. We show that by using simple segmentations and coarse 2D manipulations, we can synthesize a photorealistic edit faithful to the user's input while addressing second-order effects like harmonizing the lighting and physical interactions between edited objects.
Restoration by Generation with Constrained Priors
Dec 28, 2023



The inherent generative power of denoising diffusion models makes them well-suited for image restoration tasks where the objective is to find the optimal high-quality image within the generative space that closely resembles the input image. We propose a method to adapt a pretrained diffusion model for image restoration by simply adding noise to the input image to be restored and then denoise. Our method is based on the observation that the space of a generative model needs to be constrained. We impose this constraint by finetuning the generative model with a set of anchor images that capture the characteristics of the input image. With the constrained space, we can then leverage the sampling strategy used for generation to do image restoration. We evaluate against previous methods and show superior performances on multiple real-world restoration datasets in preserving identity and image quality. We also demonstrate an important and practical application on personalized restoration, where we use a personal album as the anchor images to constrain the generative space. This approach allows us to produce results that accurately preserve high-frequency details, which previous works are unable to do. Project webpage: https://gen2res.github.io.
DiffusionRig: Learning Personalized Priors for Facial Appearance Editing
Apr 13, 2023


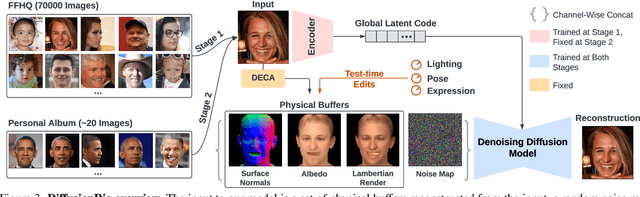
We address the problem of learning person-specific facial priors from a small number (e.g., 20) of portrait photos of the same person. This enables us to edit this specific person's facial appearance, such as expression and lighting, while preserving their identity and high-frequency facial details. Key to our approach, which we dub DiffusionRig, is a diffusion model conditioned on, or "rigged by," crude 3D face models estimated from single in-the-wild images by an off-the-shelf estimator. On a high level, DiffusionRig learns to map simplistic renderings of 3D face models to realistic photos of a given person. Specifically, DiffusionRig is trained in two stages: It first learns generic facial priors from a large-scale face dataset and then person-specific priors from a small portrait photo collection of the person of interest. By learning the CGI-to-photo mapping with such personalized priors, DiffusionRig can "rig" the lighting, facial expression, head pose, etc. of a portrait photo, conditioned only on coarse 3D models while preserving this person's identity and other high-frequency characteristics. Qualitative and quantitative experiments show that DiffusionRig outperforms existing approaches in both identity preservation and photorealism. Please see the project website: https://diffusionrig.github.io for the supplemental material, video, code, and data.
Semi-supervised Parametric Real-world Image Harmonization
Mar 01, 2023



Learning-based image harmonization techniques are usually trained to undo synthetic random global transformations applied to a masked foreground in a single ground truth photo. This simulated data does not model many of the important appearance mismatches (illumination, object boundaries, etc.) between foreground and background in real composites, leading to models that do not generalize well and cannot model complex local changes. We propose a new semi-supervised training strategy that addresses this problem and lets us learn complex local appearance harmonization from unpaired real composites, where foreground and background come from different images. Our model is fully parametric. It uses RGB curves to correct the global colors and tone and a shading map to model local variations. Our method outperforms previous work on established benchmarks and real composites, as shown in a user study, and processes high-resolution images interactively.