 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHist2Style: Histogram-Guided Stylization with Bilateral Grids
Jun 01, 2026Photorealistic style transfer aims to match the color and tone of an input image to that of a style target while preserving the content and details of the original scene. Although existing large image models can facilitate these kinds of appearance edits, their high computational demands, potential for hallucinations, and limited user control make them unsuitable for high-resolution, real-time workflows. We introduce Hist2Style, a bilateral-grid formulation for fast, edge-aware stylization that preserves visual fidelity by constraining operations to locally affine transforms in bilateral space. Our model distills a large image editing model into a lightweight network by training on a large supervised corpus generated with language and vision-language models, targeting spatially varying color edits. The network conditions on a histogram-based embedding of the style target to provide an interpretable interface for adjusting the output style by modifying the target color distribution. Overall, Hist2Style maintains content structure by construction, avoids hallucinations, and supports real-time, high-resolution photorealistic stylization with interactive user-controllable color and tone adjustments.
Lucky High Dynamic Range Smartphone Imaging
Apr 21, 2026While the human eye can perceive an impressive twenty stops of dynamic range, smartphone camera sensors remain limited to about twelve stops despite decades of research. A variety of high dynamic range (HDR) image capture and processing techniques have been proposed, and, in practice, they can extend the dynamic range by 3-5 stops for handheld photography. This paper proposes an approach that robustly captures dynamic range using a handheld smartphone camera and lightweight networks suitable for running on mobile devices. Our method operates indirectly on linear raw pixels in bracketed exposures. Every pixel in the final HDR image is a convex combination of input pixels in the neighborhood, adjusted for exposure, and thus avoids hallucination artifacts typical of recent deep image synthesis networks. We validate our system on both synthetic imagery and unseen real bracketed images -- we confirm zero-shot generalization of the method to smartphone camera captures. Our iterative inference architecture is capable of processing an arbitrary number of bracketed input photos, and we show examples from capture stacks containing 3--9 images. Our training process relies only on synthetic captures yet generalizes to unseen real photos from several cameras. Moreover, we show that this training scheme improves other SOTA methods over their pretrained counterparts.
Predicting Dynamics of Ultra-Large Complex Systems by Inferring Governing Equations
Apr 01, 2026Predicting the behavior of ultra-large complex systems, from climate to biological and technological networks, is a central unsolved challenge. Existing approaches face a fundamental trade-off: equation discovery methods provide interpretability but fail to scale, while neural networks scale but operate as black boxes and often lose reliability over long times. Here, we introduce the Sparse Identification Graph Neural Network, a framework that overcome this divide by allowing to infer the governing equations of large networked systems from data. By defining symbolic discovery as edge-level information, SIGN decouples the scalability of sparse identification from network size, enabling efficient equation discovery even in large systems. SIGN allows to study networks with over 100,000 nodes while remaining robust to noise, sparse sampling, and missing data. Across diverse benchmark systems, including coupled chaotic oscillators, neural dynamics, and epidemic spreading, it recovers governing equations with high precision and sustains accurate long-term predictions. Applied to a data set of time series of temperature measurements in 71,987 sea surface positions, SIGN identifies a compact predictive network model and captures large-scale sea surface temperature conditions up to two years in advance. By enabling equation discovery at previously inaccessible scales, SIGN opens a path toward interpretable and reliable prediction of real-world complex systems.
CCMamba: Selective State-Space Models for Higher-Order Graph Learning on Combinatorial Complexes
Jan 28, 2026Topological deep learning has emerged for modeling higher-order relational structures beyond pairwise interactions that standard graph neural networks fail to capture. Although combinatorial complexes offer a unified topological framework, most existing topological deep learning methods rely on local message passing via attention mechanisms, which incur quadratic complexity and remain low-dimensional, limiting scalability and rank-aware information aggregation in higher-order complexes.We propose Combinatorial Complex Mamba (CCMamba), the first unified mamba-based neural framework for learning on combinatorial complexes. CCMamba reformulates message passing as a selective state-space modeling problem by organizing multi-rank incidence relations into structured sequences processed by rank-aware state-space models. This enables adaptive, directional, and long range information propagation in linear time without self attention. We further establish the theoretical analysis that the expressive power upper-bound of CCMamba message passing is the 1-Weisfeiler-Lehman test. Experiments on graph, hypergraph, and simplicial benchmarks demonstrate that CCMamba consistently outperforms existing methods while exhibiting improved scalability and robustness to depth.
MetaHGNIE: Meta-Path Induced Hypergraph Contrastive Learning in Heterogeneous Knowledge Graphs
Dec 13, 2025Node importance estimation (NIE) in heterogeneous knowledge graphs is a critical yet challenging task, essential for applications such as recommendation, knowledge reasoning, and question answering. Existing methods often rely on pairwise connections, neglecting high-order dependencies among multiple entities and relations, and they treat structural and semantic signals independently, hindering effective cross-modal integration. To address these challenges, we propose MetaHGNIE, a meta-path induced hypergraph contrastive learning framework for disentangling and aligning structural and semantic information. MetaHGNIE constructs a higher-order knowledge graph via meta-path sequences, where typed hyperedges capture multi-entity relational contexts. Structural dependencies are aggregated with local attention, while semantic representations are encoded through a hypergraph transformer equipped with sparse chunking to reduce redundancy. Finally, a multimodal fusion module integrates structural and semantic embeddings under contrastive learning with auxiliary supervision, ensuring robust cross-modal alignment. Extensive experiments on benchmark NIE datasets demonstrate that MetaHGNIE consistently outperforms state-of-the-art baselines. These results highlight the effectiveness of explicitly modeling higher-order interactions and cross-modal alignment in heterogeneous knowledge graphs. Our code is available at https://github.com/SEU-WENJIA/DualHNIE
Critical Nodes Identification in Complex Networks: A Survey
Jul 08, 2025Complex networks have become essential tools for understanding diverse phenomena in social systems, traffic systems, biomolecular systems, and financial systems. Identifying critical nodes is a central theme in contemporary research, serving as a vital bridge between theoretical foundations and practical applications. Nevertheless, the intrinsic complexity and structural heterogeneity characterizing real-world networks, with particular emphasis on dynamic and higher-order networks, present substantial obstacles to the development of universal frameworks for critical node identification. This paper provides a comprehensive review of critical node identification techniques, categorizing them into seven main classes: centrality, critical nodes deletion problem, influence maximization, network control, artificial intelligence, higher-order and dynamic methods. Our review bridges the gaps in existing surveys by systematically classifying methods based on their methodological foundations and practical implications, and by highlighting their strengths, limitations, and applicability across different network types. Our work enhances the understanding of critical node research by identifying key challenges, such as algorithmic universality, real-time evaluation in dynamic networks, analysis of higher-order structures, and computational efficiency in large-scale networks. The structured synthesis consolidates current progress and highlights open questions, particularly in modeling temporal dynamics, advancing efficient algorithms, integrating machine learning approaches, and developing scalable and interpretable metrics for complex systems.
Decoupling Spatio-Temporal Prediction: When Lightweight Large Models Meet Adaptive Hypergraphs
May 26, 2025Spatio-temporal prediction is a pivotal task with broad applications in traffic management, climate monitoring, energy scheduling, etc. However, existing methodologies often struggle to balance model expressiveness and computational efficiency, especially when scaling to large real-world datasets. To tackle these challenges, we propose STH-SepNet (Spatio-Temporal Hypergraph Separation Networks), a novel framework that decouples temporal and spatial modeling to enhance both efficiency and precision. Therein, the temporal dimension is modeled using lightweight large language models, which effectively capture low-rank temporal dynamics. Concurrently, the spatial dimension is addressed through an adaptive hypergraph neural network, which dynamically constructs hyperedges to model intricate, higher-order interactions. A carefully designed gating mechanism is integrated to seamlessly fuse temporal and spatial representations. By leveraging the fundamental principles of low-rank temporal dynamics and spatial interactions, STH-SepNet offers a pragmatic and scalable solution for spatio-temporal prediction in real-world applications. Extensive experiments on large-scale real-world datasets across multiple benchmarks demonstrate the effectiveness of STH-SepNet in boosting predictive performance while maintaining computational efficiency. This work may provide a promising lightweight framework for spatio-temporal prediction, aiming to reduce computational demands and while enhancing predictive performance. Our code is avaliable at https://github.com/SEU-WENJIA/ST-SepNet-Lightweight-LLMs-Meet-Adaptive-Hypergraphs.
CellTypeAgent: Trustworthy cell type annotation with Large Language Models
May 13, 2025Cell type annotation is a critical yet laborious step in single-cell RNA sequencing analysis. We present a trustworthy large language model (LLM)-agent, CellTypeAgent, which integrates LLMs with verification from relevant databases. CellTypeAgent achieves higher accuracy than existing methods while mitigating hallucinations. We evaluated CellTypeAgent across nine real datasets involving 303 cell types from 36 tissues. This combined approach holds promise for more efficient and reliable cell type annotation.
Classic Video Denoising in a Machine Learning World: Robust, Fast, and Controllable
Apr 04, 2025Denoising is a crucial step in many video processing pipelines such as in interactive editing, where high quality, speed, and user control are essential. While recent approaches achieve significant improvements in denoising quality by leveraging deep learning, they are prone to unexpected failures due to discrepancies between training data distributions and the wide variety of noise patterns found in real-world videos. These methods also tend to be slow and lack user control. In contrast, traditional denoising methods perform reliably on in-the-wild videos and run relatively quickly on modern hardware. However, they require manually tuning parameters for each input video, which is not only tedious but also requires skill. We bridge the gap between these two paradigms by proposing a differentiable denoising pipeline based on traditional methods. A neural network is then trained to predict the optimal denoising parameters for each specific input, resulting in a robust and efficient approach that also supports user control.
STimage-1K4M: A histopathology image-gene expression dataset for spatial transcriptomics
Jun 10, 2024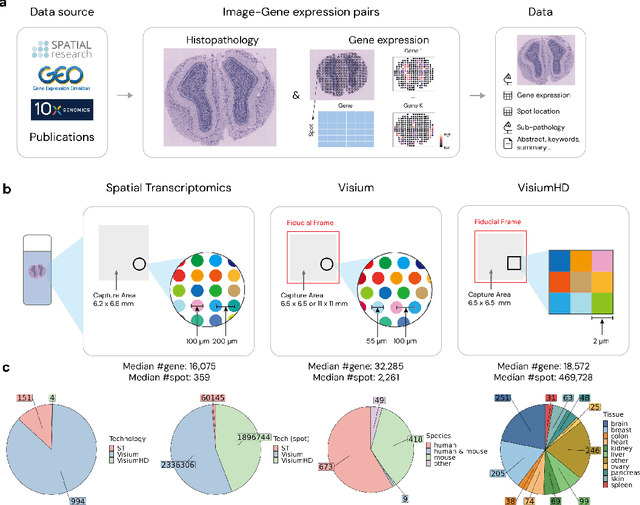
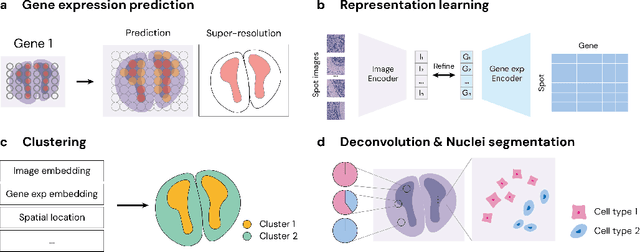

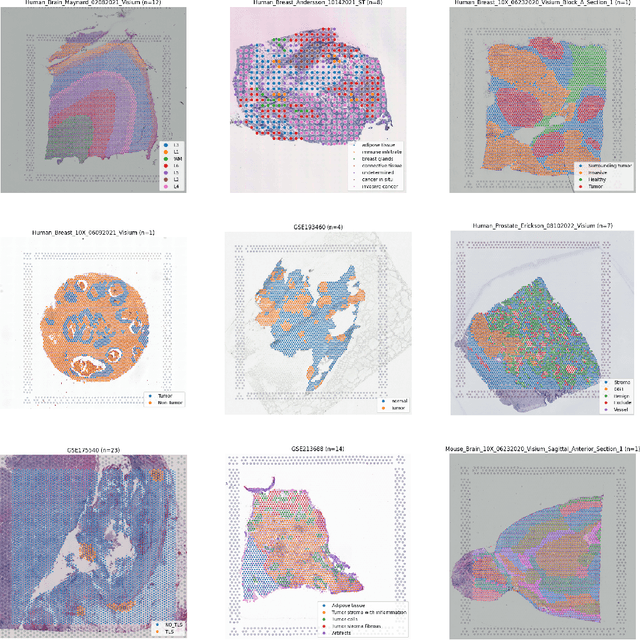
Recent advances in multi-modal algorithms have driven and been driven by the increasing availability of large image-text datasets, leading to significant strides in various fields, including computational pathology. However, in most existing medical image-text datasets, the text typically provides high-level summaries that may not sufficiently describe sub-tile regions within a large pathology image. For example, an image might cover an extensive tissue area containing cancerous and healthy regions, but the accompanying text might only specify that this image is a cancer slide, lacking the nuanced details needed for in-depth analysis. In this study, we introduce STimage-1K4M, a novel dataset designed to bridge this gap by providing genomic features for sub-tile images. STimage-1K4M contains 1,149 images derived from spatial transcriptomics data, which captures gene expression information at the level of individual spatial spots within a pathology image. Specifically, each image in the dataset is broken down into smaller sub-image tiles, with each tile paired with 15,000-30,000 dimensional gene expressions. With 4,293,195 pairs of sub-tile images and gene expressions, STimage-1K4M offers unprecedented granularity, paving the way for a wide range of advanced research in multi-modal data analysis an innovative applications in computational pathology, and beyond.