 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOGO: Residual Quantized Hierarchical Causal Transformer for High-Quality and Real-Time 3D Human Motion Generation
Jun 06, 2025Recent advances in transformer-based text-to-motion generation have led to impressive progress in synthesizing high-quality human motion. Nevertheless, jointly achieving high fidelity, streaming capability, real-time responsiveness, and scalability remains a fundamental challenge. In this paper, we propose MOGO (Motion Generation with One-pass), a novel autoregressive framework tailored for efficient and real-time 3D motion generation. MOGO comprises two key components: (1) MoSA-VQ, a motion scale-adaptive residual vector quantization module that hierarchically discretizes motion sequences with learnable scaling to produce compact yet expressive representations; and (2) RQHC-Transformer, a residual quantized hierarchical causal transformer that generates multi-layer motion tokens in a single forward pass, significantly reducing inference latency. To enhance semantic fidelity, we further introduce a text condition alignment mechanism that improves motion decoding under textual control. Extensive experiments on benchmark datasets including HumanML3D, KIT-ML, and CMP demonstrate that MOGO achieves competitive or superior generation quality compared to state-of-the-art transformer-based methods, while offering substantial improvements in real-time performance, streaming generation, and generalization under zero-shot settings.
Energy-Aware Lane Planning for Connected Electric Vehicles in Urban Traffic: Design and Vehicle-in-the-Loop Validation
Mar 29, 2025Urban driving with connected and automated vehicles (CAVs) offers potential for energy savings, yet most eco-driving strategies focus solely on longitudinal speed control within a single lane. This neglects the significant impact of lateral decisions, such as lane changes, on overall energy efficiency, especially in environments with traffic signals and heterogeneous traffic flow. To address this gap, we propose a novel energy-aware motion planning framework that jointly optimizes longitudinal speed and lateral lane-change decisions using vehicle-to-infrastructure (V2I) communication. Our approach estimates long-term energy costs using a graph-based approximation and solves short-horizon optimal control problems under traffic constraints. Using a data-driven energy model calibrated to an actual battery electric vehicle, we demonstrate with vehicle-in-the-loop experiments that our method reduces motion energy consumption by up to 24 percent compared to a human driver, highlighting the potential of connectivity-enabled planning for sustainable urban autonomy.
Semantic Scene Completion with Multi-Feature Data Balancing Network
Dec 02, 2024Semantic Scene Completion (SSC) is a critical task in computer vision, that utilized in applications such as virtual reality (VR). SSC aims to construct detailed 3D models from partial views by transforming a single 2D image into a 3D representation, assigning each voxel a semantic label. The main challenge lies in completing 3D volumes with limited information, compounded by data imbalance, inter-class ambiguity, and intra-class diversity in indoor scenes. To address this, we propose the Multi-Feature Data Balancing Network (MDBNet), a dual-head model for RGB and depth data (F-TSDF) inputs. Our hybrid encoder-decoder architecture with identity transformation in a pre-activation residual module (ITRM) effectively manages diverse signals within F-TSDF. We evaluate RGB feature fusion strategies and use a combined loss function cross entropy for 2D RGB features and weighted cross-entropy for 3D SSC predictions. MDBNet results surpass comparable state-of-the-art (SOTA) methods on NYU datasets, demonstrating the effectiveness of our approach.
Learning Two-agent Motion Planning Strategies from Generalized Nash Equilibrium for Model Predictive Control
Nov 21, 2024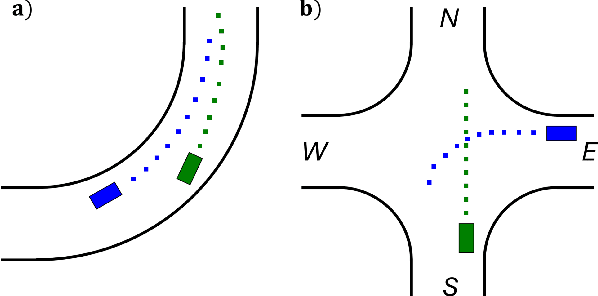


We introduce an Implicit Game-Theoretic MPC (IGT-MPC), a decentralized algorithm for two-agent motion planning that uses a learned value function that predicts the game-theoretic interaction outcomes as the terminal cost-to-go function in a model predictive control (MPC) framework, guiding agents to implicitly account for interactions with other agents and maximize their reward. This approach applies to competitive and cooperative multi-agent motion planning problems which we formulate as constrained dynamic games. Given a constrained dynamic game, we randomly sample initial conditions and solve for the generalized Nash equilibrium (GNE) to generate a dataset of GNE solutions, computing the reward outcome of each game-theoretic interaction from the GNE. The data is used to train a simple neural network to predict the reward outcome, which we use as the terminal cost-to-go function in an MPC scheme. We showcase emerging competitive and coordinated behaviors using IGT-MPC in scenarios such as two-vehicle head-to-head racing and un-signalized intersection navigation. IGT-MPC offers a novel method integrating machine learning and game-theoretic reasoning into model-based decentralized multi-agent motion planning.
Improving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
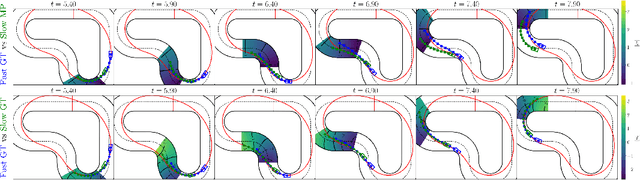
Mar 14, 2024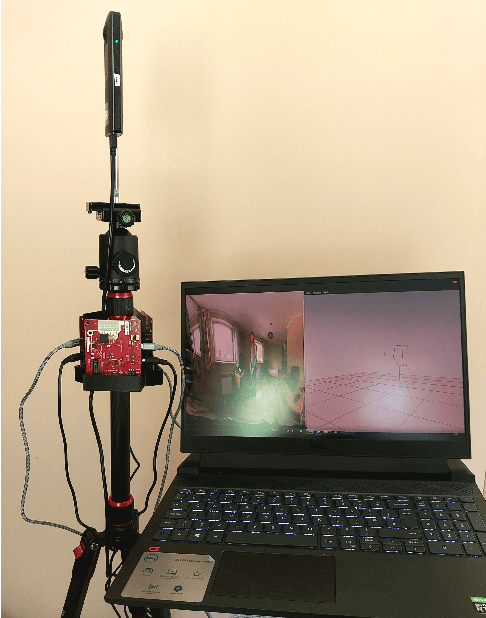
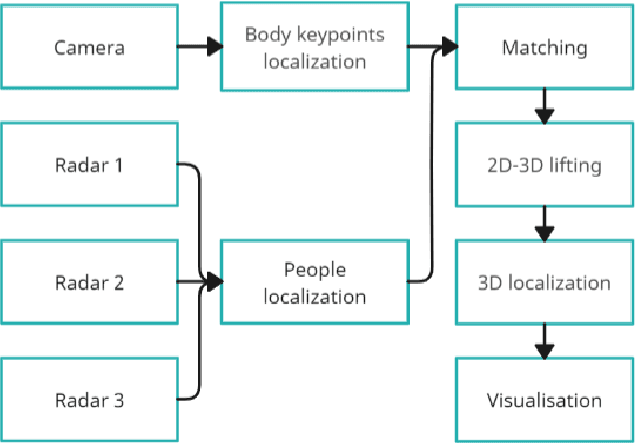
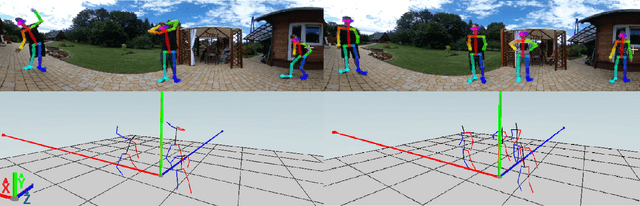
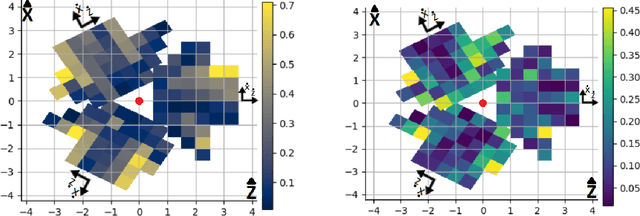
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
Scalable Multi-modal Model Predictive Control via Duality-based Interaction Predictions
Feb 02, 2024



We propose a hierarchical architecture designed for scalable real-time Model Predictive Control (MPC) in complex, multi-modal traffic scenarios. This architecture comprises two key components: 1) RAID-Net, a novel attention-based Recurrent Neural Network that predicts relevant interactions along the MPC prediction horizon between the autonomous vehicle and the surrounding vehicles using Lagrangian duality, and 2) a reduced Stochastic MPC problem that eliminates irrelevant collision avoidance constraints, enhancing computational efficiency. Our approach is demonstrated in a simulated traffic intersection with interactive surrounding vehicles, showcasing a 12x speed-up in solving the motion planning problem. A video demonstrating the proposed architecture in multiple complex traffic scenarios can be found here: https://youtu.be/-TcMeolCLWc
Depth Insight -- Contribution of Different Features to Indoor Single-image Depth Estimation
Nov 16, 2023Depth estimation from a single image is a challenging problem in computer vision because binocular disparity or motion information is absent. Whereas impressive performances have been reported in this area recently using end-to-end trained deep neural architectures, as to what cues in the images that are being exploited by these black box systems is hard to know. To this end, in this work, we quantify the relative contributions of the known cues of depth in a monocular depth estimation setting using an indoor scene data set. Our work uses feature extraction techniques to relate the single features of shape, texture, colour and saturation, taken in isolation, to predict depth. We find that the shape of objects extracted by edge detection substantially contributes more than others in the indoor setting considered, while the other features also have contributions in varying degrees. These insights will help optimise depth estimation models, boosting their accuracy and robustness. They promise to broaden the practical applications of vision-based depth estimation. The project code is attached to the supplementary material and will be published on GitHub.
Unsupervised Reconstruction of 3D Human Pose Interactions From 2D Poses Alone
Sep 26, 2023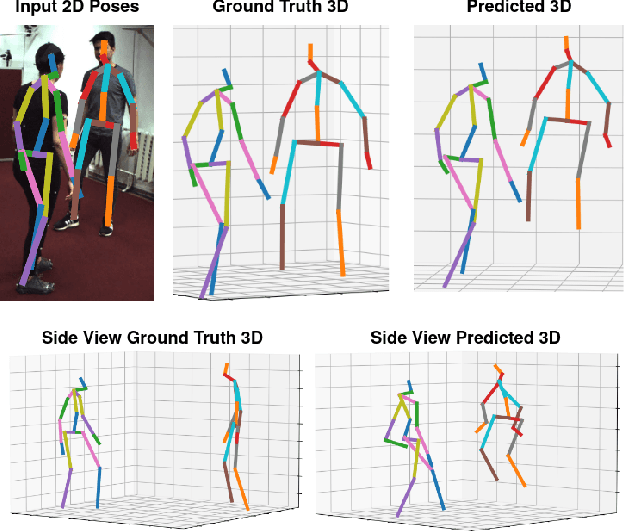


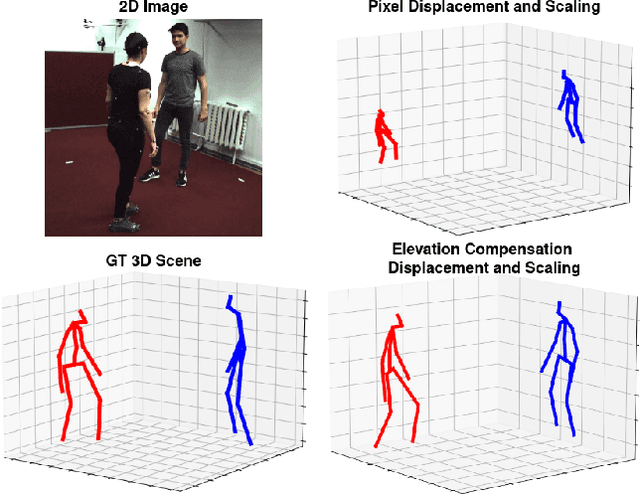
Current unsupervised 2D-3D human pose estimation (HPE) methods do not work in multi-person scenarios due to perspective ambiguity in monocular images. Therefore, we present one of the first studies investigating the feasibility of unsupervised multi-person 2D-3D HPE from just 2D poses alone, focusing on reconstructing human interactions. To address the issue of perspective ambiguity, we expand upon prior work by predicting the cameras' elevation angle relative to the subjects' pelvis. This allows us to rotate the predicted poses to be level with the ground plane, while obtaining an estimate for the vertical offset in 3D between individuals. Our method involves independently lifting each subject's 2D pose to 3D, before combining them in a shared 3D coordinate system. The poses are then rotated and offset by the predicted elevation angle before being scaled. This by itself enables us to retrieve an accurate 3D reconstruction of their poses. We present our results on the CHI3D dataset, introducing its use for unsupervised 2D-3D pose estimation with three new quantitative metrics, and establishing a benchmark for future research.
LInKs "Lifting Independent Keypoints" -- Partial Pose Lifting for Occlusion Handling with Improved Accuracy in 2D-3D Human Pose Estimation
Sep 13, 2023



We present LInKs, a novel unsupervised learning method to recover 3D human poses from 2D kinematic skeletons obtained from a single image, even when occlusions are present. Our approach follows a unique two-step process, which involves first lifting the occluded 2D pose to the 3D domain, followed by filling in the occluded parts using the partially reconstructed 3D coordinates. This lift-then-fill approach leads to significantly more accurate results compared to models that complete the pose in 2D space alone. Additionally, we improve the stability and likelihood estimation of normalising flows through a custom sampling function replacing PCA dimensionality reduction previously used in prior work. Furthermore, we are the first to investigate if different parts of the 2D kinematic skeleton can be lifted independently which we find by itself reduces the error of current lifting approaches. We attribute this to the reduction of long-range keypoint correlations. In our detailed evaluation, we quantify the error under various realistic occlusion scenarios, showcasing the versatility and applicability of our model. Our results consistently demonstrate the superiority of handling all types of occlusions in 3D space when compared to others that complete the pose in 2D space. Our approach also exhibits consistent accuracy in scenarios without occlusion, as evidenced by a 7.9% reduction in reconstruction error compared to prior works on the Human3.6M dataset. Furthermore, our method excels in accurately retrieving complete 3D poses even in the presence of occlusions, making it highly applicable in situations where complete 2D pose information is unavailable.
MatSpectNet: Material Segmentation Network with Domain-Aware and Physically-Constrained Hyperspectral Reconstruction
Aug 06, 2023Achieving accurate material segmentation for 3-channel RGB images is challenging due to the considerable variation in a material's appearance. Hyperspectral images, which are sets of spectral measurements sampled at multiple wavelengths, theoretically offer distinct information for material identification, as variations in intensity of electromagnetic radiation reflected by a surface depend on the material composition of a scene. However, existing hyperspectral datasets are impoverished regarding the number of images and material categories for the dense material segmentation task, and collecting and annotating hyperspectral images with a spectral camera is prohibitively expensive. To address this, we propose a new model, the MatSpectNet to segment materials with recovered hyperspectral images from RGB images. The network leverages the principles of colour perception in modern cameras to constrain the reconstructed hyperspectral images and employs the domain adaptation method to generalise the hyperspectral reconstruction capability from a spectral recovery dataset to material segmentation datasets. The reconstructed hyperspectral images are further filtered using learned response curves and enhanced with human perception. The performance of MatSpectNet is evaluated on the LMD dataset as well as the OpenSurfaces dataset. Our experiments demonstrate that MatSpectNet attains a 1.60% increase in average pixel accuracy and a 3.42% improvement in mean class accuracy compared with the most recent publication. The project code is attached to the supplementary material and will be published on GitHub.