 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
Mar 14, 2024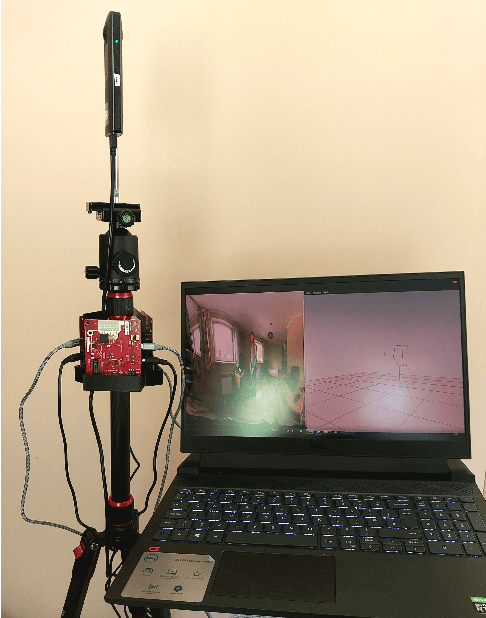
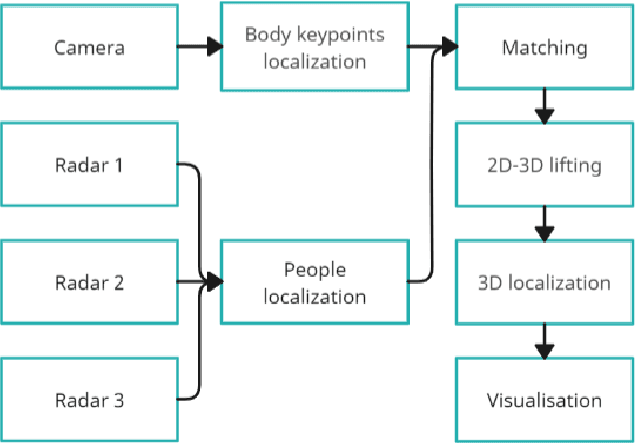
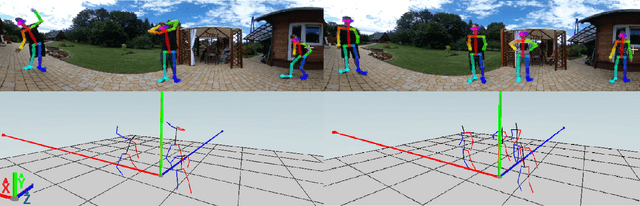
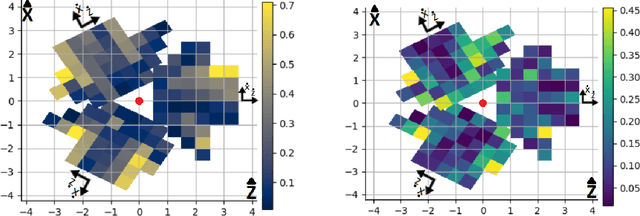
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
Unsupervised Reconstruction of 3D Human Pose Interactions From 2D Poses Alone
Sep 26, 2023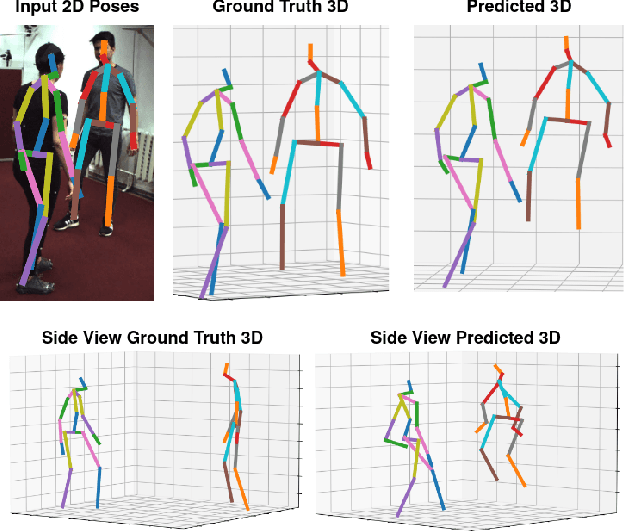


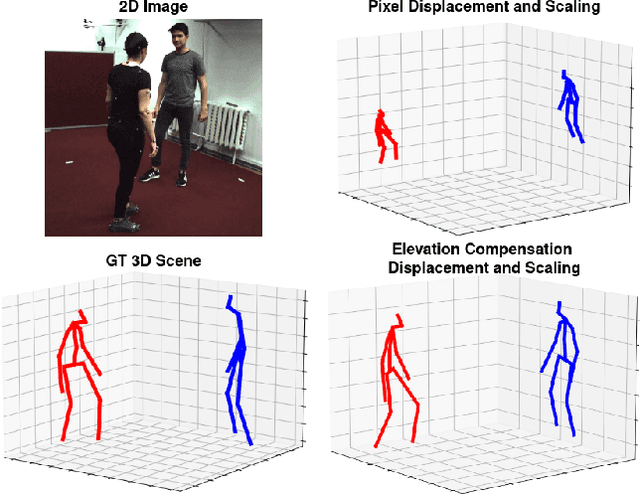
Current unsupervised 2D-3D human pose estimation (HPE) methods do not work in multi-person scenarios due to perspective ambiguity in monocular images. Therefore, we present one of the first studies investigating the feasibility of unsupervised multi-person 2D-3D HPE from just 2D poses alone, focusing on reconstructing human interactions. To address the issue of perspective ambiguity, we expand upon prior work by predicting the cameras' elevation angle relative to the subjects' pelvis. This allows us to rotate the predicted poses to be level with the ground plane, while obtaining an estimate for the vertical offset in 3D between individuals. Our method involves independently lifting each subject's 2D pose to 3D, before combining them in a shared 3D coordinate system. The poses are then rotated and offset by the predicted elevation angle before being scaled. This by itself enables us to retrieve an accurate 3D reconstruction of their poses. We present our results on the CHI3D dataset, introducing its use for unsupervised 2D-3D pose estimation with three new quantitative metrics, and establishing a benchmark for future research.
LInKs "Lifting Independent Keypoints" -- Partial Pose Lifting for Occlusion Handling with Improved Accuracy in 2D-3D Human Pose Estimation
Sep 13, 2023



We present LInKs, a novel unsupervised learning method to recover 3D human poses from 2D kinematic skeletons obtained from a single image, even when occlusions are present. Our approach follows a unique two-step process, which involves first lifting the occluded 2D pose to the 3D domain, followed by filling in the occluded parts using the partially reconstructed 3D coordinates. This lift-then-fill approach leads to significantly more accurate results compared to models that complete the pose in 2D space alone. Additionally, we improve the stability and likelihood estimation of normalising flows through a custom sampling function replacing PCA dimensionality reduction previously used in prior work. Furthermore, we are the first to investigate if different parts of the 2D kinematic skeleton can be lifted independently which we find by itself reduces the error of current lifting approaches. We attribute this to the reduction of long-range keypoint correlations. In our detailed evaluation, we quantify the error under various realistic occlusion scenarios, showcasing the versatility and applicability of our model. Our results consistently demonstrate the superiority of handling all types of occlusions in 3D space when compared to others that complete the pose in 2D space. Our approach also exhibits consistent accuracy in scenarios without occlusion, as evidenced by a 7.9% reduction in reconstruction error compared to prior works on the Human3.6M dataset. Furthermore, our method excels in accurately retrieving complete 3D poses even in the presence of occlusions, making it highly applicable in situations where complete 2D pose information is unavailable.
Optimising 2D Pose Representation: Improve Accuracy, Stability and Generalisability Within Unsupervised 2D-3D Human Pose Estimation
Sep 01, 2022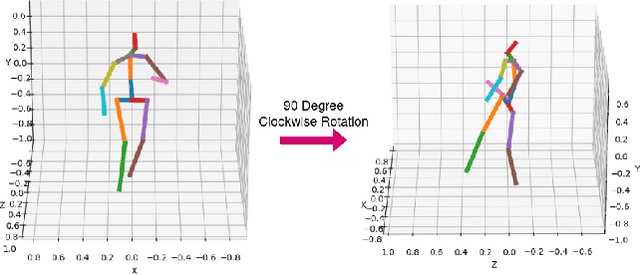
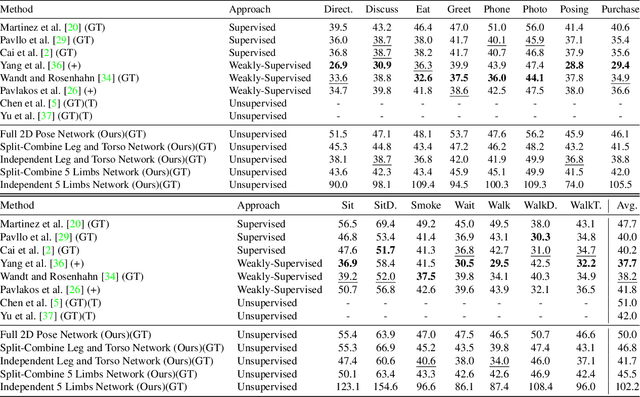
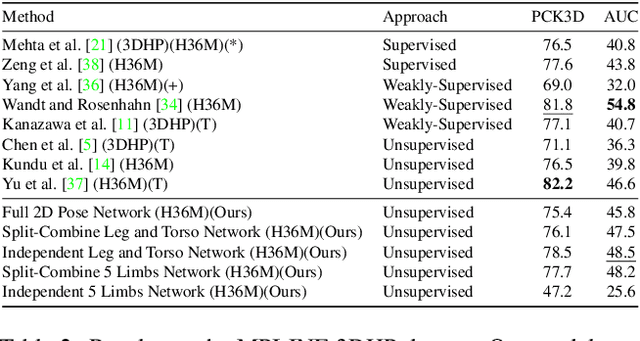
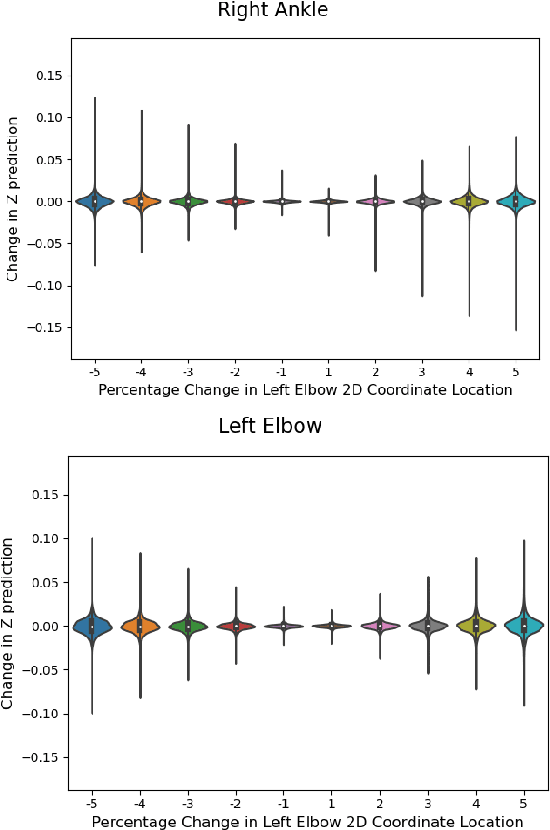
This paper addresses the problem of 2D pose representation during unsupervised 2D to 3D pose lifting to improve the accuracy, stability and generalisability of 3D human pose estimation (HPE) models. All unsupervised 2D-3D HPE approaches provide the entire 2D kinematic skeleton to a model during training. We argue that this is sub-optimal and disruptive as long-range correlations are induced between independent 2D key points and predicted 3D ordinates during training. To this end, we conduct the following study. With a maximum architecture capacity of 6 residual blocks, we evaluate the performance of 5 models which each represent a 2D pose differently during the adversarial unsupervised 2D-3D HPE process. Additionally, we show the correlations between 2D key points which are learned during the training process, highlighting the unintuitive correlations induced when an entire 2D pose is provided to a lifting model. Our results show that the most optimal representation of a 2D pose is that of two independent segments, the torso and legs, with no shared features between each lifting network. This approach decreased the average error by 20\% on the Human3.6M dataset when compared to a model with a near identical parameter count trained on the entire 2D kinematic skeleton. Furthermore, due to the complex nature of adversarial learning, we show how this representation can also improve convergence during training allowing for an optimum result to be obtained more often.
"Teaching Independent Parts Separately"(TIPSy-GAN) : Improving Accuracy and Stability in Unsupervised Adversarial 2D to 3D Human Pose Estimation
May 16, 2022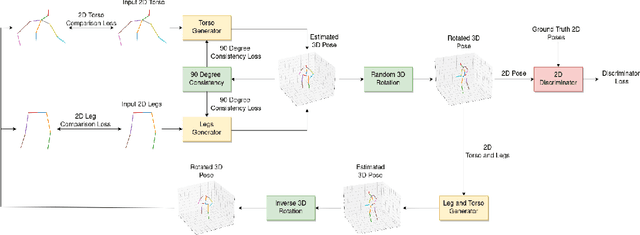
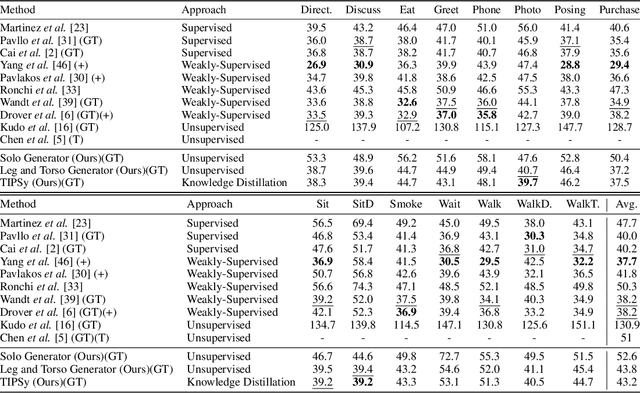
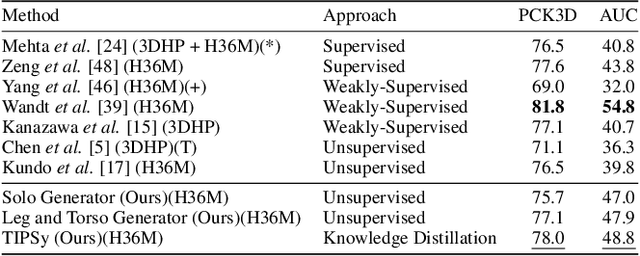
We present TIPSy-GAN, a new approach to improve the accuracy and stability in unsupervised adversarial 2D to 3D human pose estimation. In our work we demonstrate that the human kinematic skeleton should not be assumed as one spatially codependent structure. In fact, we believe when a full 2D pose is provided during training, there is an inherent bias learned where the 3D coordinate of a keypoint is spatially codependent on the 2D locations of all other keypoints. To investigate our theory we follow previous adversarial approaches but train two generators on spatially independent parts of the kinematic skeleton, the torso and the legs. We find that improving the 2D reprojection self-consistency cycle is key to lowering the evaluation error and therefore introduce new consistency constraints during training. A TIPSy is produced model via knowledge distillation from these generators which can predict the 3D coordinates for the entire 2D pose with improved results. Furthermore, we address the question left unanswered in prior work detailing how long to train for a truly unsupervised scenario. We show that two independent generators training adversarially has improved stability than that of a solo generator which will collapse due to the adversarial network becoming unstable. TIPSy decreases the average error by 18% when compared to that of a baseline solo generator. TIPSy improves upon other unsupervised approaches while also performing strongly against supervised and weakly-supervised approaches during evaluation on both the Human3.6M and MPI-INF-3DHP dataset.
Super Resolution in Human Pose Estimation: Pixelated Poses to a Resolution Result?
Jul 05, 2021

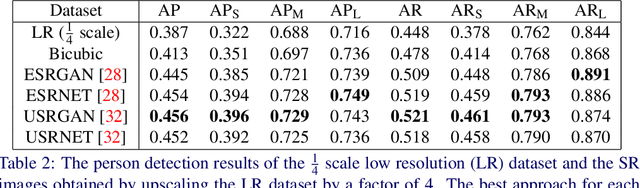
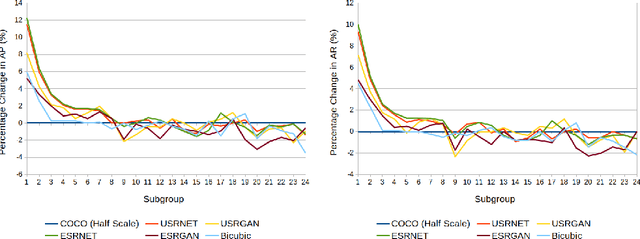
The results obtained from state of the art human pose estimation (HPE) models degrade rapidly when evaluating people of a low resolution, but can super resolution (SR) be used to help mitigate this effect? By using various SR approaches we enhanced two low resolution datasets and evaluated the change in performance of both an object and keypoint detector as well as end-to-end HPE results. We remark the following observations. First we find that for low resolution people their keypoint detection performance improved once SR was applied. Second, the keypoint detection performance gained is dependent on the persons initial resolution (segmentation area in pixels) in the original image; keypoint detection performance was improved when SR was applied to people with a small initial segmentation area, but degrades as this becomes larger. To address this we introduced a novel Mask-RCNN approach, utilising a segmentation area threshold to decide when to use SR during the keypoint detection step. This approach achieved the best results for each of our HPE performance metrics.