 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Real-Time Omnidirectional 3D Multi-Person Human Pose Estimation with People Matching and Unsupervised 2D-3D Lifting
Mar 14, 2024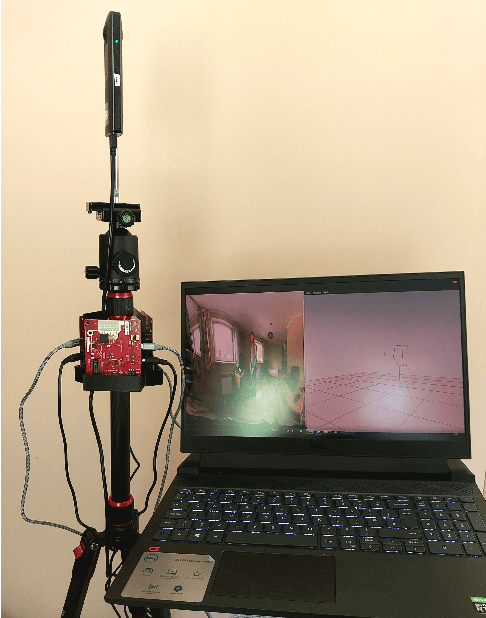
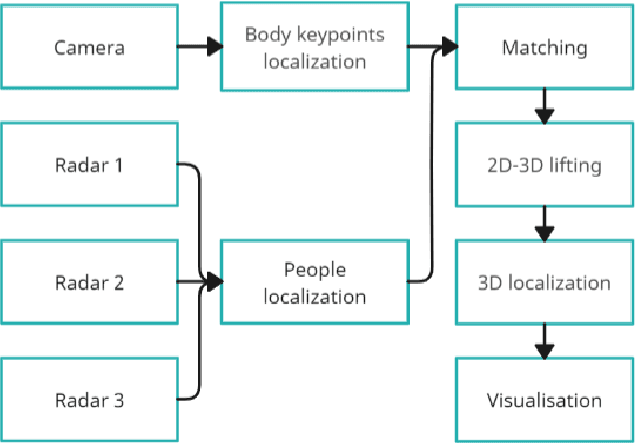
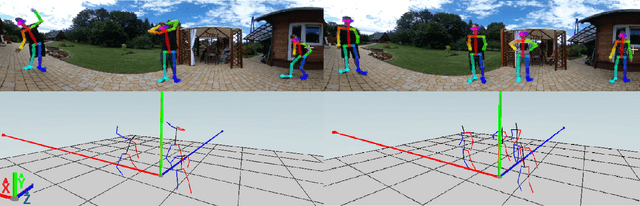
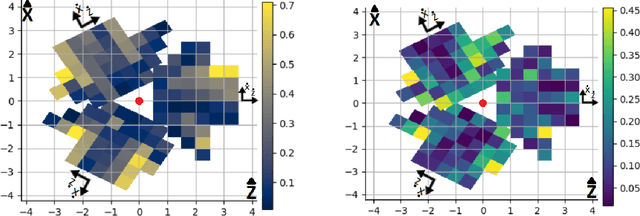
Current human pose estimation systems focus on retrieving an accurate 3D global estimate of a single person. Therefore, this paper presents one of the first 3D multi-person human pose estimation systems that is able to work in real-time and is also able to handle basic forms of occlusion. First, we adjust an off-the-shelf 2D detector and an unsupervised 2D-3D lifting model for use with a 360$^\circ$ panoramic camera and mmWave radar sensors. We then introduce several contributions, including camera and radar calibrations, and the improved matching of people within the image and radar space. The system addresses both the depth and scale ambiguity problems by employing a lightweight 2D-3D pose lifting algorithm that is able to work in real-time while exhibiting accurate performance in both indoor and outdoor environments which offers both an affordable and scalable solution. Notably, our system's time complexity remains nearly constant irrespective of the number of detected individuals, achieving a frame rate of approximately 7-8 fps on a laptop with a commercial-grade GPU.
Shrinking unit: a Graph Convolution-Based Unit for CNN-like 3D Point Cloud Feature Extractors
Sep 26, 2022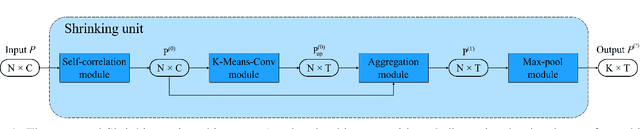



3D point clouds have attracted increasing attention in architecture, engineering, and construction due to their high-quality object representation and efficient acquisition methods. Consequently, many point cloud feature detection methods have been proposed in the literature to automate some workflows, such as their classification or part segmentation. Nevertheless, the performance of point cloud automated systems significantly lags behind their image counterparts. While part of this failure stems from the irregularity, unstructuredness, and disorder of point clouds, which makes the task of point cloud feature detection significantly more challenging than the image one, we argue that a lack of inspiration from the image domain might be the primary cause of such a gap. Indeed, given the overwhelming success of Convolutional Neural Networks (CNNs) in image feature detection, it seems reasonable to design their point cloud counterparts, but none of the proposed approaches closely resembles them. Specifically, even though many approaches generalise the convolution operation in point clouds, they fail to emulate the CNNs multiple-feature detection and pooling operations. For this reason, we propose a graph convolution-based unit, dubbed Shrinking unit, that can be stacked vertically and horizontally for the design of CNN-like 3D point cloud feature extractors. Given that self, local and global correlations between points in a point cloud convey crucial spatial geometric information, we also leverage them during the feature extraction process. We evaluate our proposal by designing a feature extractor model for the ModelNet-10 benchmark dataset and achieve 90.64% classification accuracy, demonstrating that our innovative idea is effective. Our code is available at github.com/albertotamajo/Shrinking-unit.