 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArch-LLM: Taming LLMs for Neural Architecture Generation via Unsupervised Discrete Representation Learning
Mar 28, 2025Unsupervised representation learning has been widely explored across various modalities, including neural architectures, where it plays a key role in downstream applications like Neural Architecture Search (NAS). These methods typically learn an unsupervised representation space before generating/ sampling architectures for the downstream search. A common approach involves the use of Variational Autoencoders (VAEs) to map discrete architectures onto a continuous representation space, however, sampling from these spaces often leads to a high percentage of invalid or duplicate neural architectures. This could be due to the unnatural mapping of inherently discrete architectural space onto a continuous space, which emphasizes the need for a robust discrete representation of these architectures. To address this, we introduce a Vector Quantized Variational Autoencoder (VQ-VAE) to learn a discrete latent space more naturally aligned with the discrete neural architectures. In contrast to VAEs, VQ-VAEs (i) map each architecture into a discrete code sequence and (ii) allow the prior to be learned by any generative model rather than assuming a normal distribution. We then represent these architecture latent codes as numerical sequences and train a text-to-text model leveraging a Large Language Model to learn and generate sequences representing architectures. We experiment our method with Inception/ ResNet-like cell-based search spaces, namely NAS-Bench-101 and NAS-Bench-201. Compared to VAE-based methods, our approach improves the generation of valid and unique architectures by over 80% on NASBench-101 and over 8% on NASBench-201. Finally, we demonstrate the applicability of our method in NAS employing a sequence-modeling-based NAS algorithm.
Semantic Scene Completion with Multi-Feature Data Balancing Network
Dec 02, 2024Semantic Scene Completion (SSC) is a critical task in computer vision, that utilized in applications such as virtual reality (VR). SSC aims to construct detailed 3D models from partial views by transforming a single 2D image into a 3D representation, assigning each voxel a semantic label. The main challenge lies in completing 3D volumes with limited information, compounded by data imbalance, inter-class ambiguity, and intra-class diversity in indoor scenes. To address this, we propose the Multi-Feature Data Balancing Network (MDBNet), a dual-head model for RGB and depth data (F-TSDF) inputs. Our hybrid encoder-decoder architecture with identity transformation in a pre-activation residual module (ITRM) effectively manages diverse signals within F-TSDF. We evaluate RGB feature fusion strategies and use a combined loss function cross entropy for 2D RGB features and weighted cross-entropy for 3D SSC predictions. MDBNet results surpass comparable state-of-the-art (SOTA) methods on NYU datasets, demonstrating the effectiveness of our approach.
Discrepancy-based Diffusion Models for Lesion Detection in Brain MRI
May 08, 2024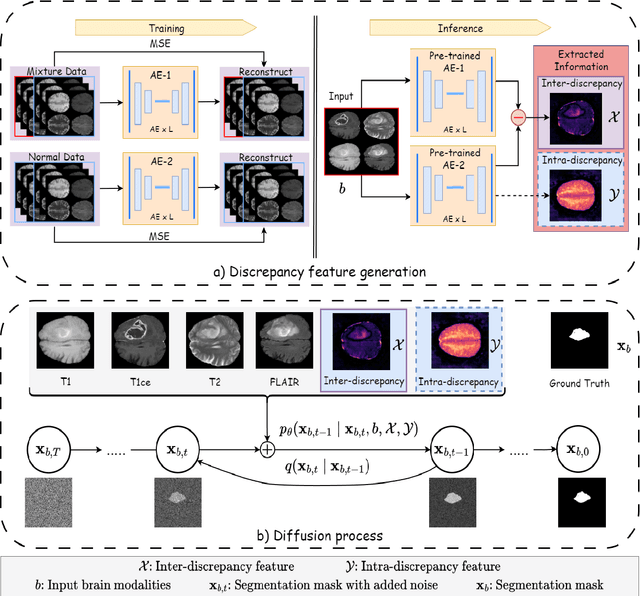
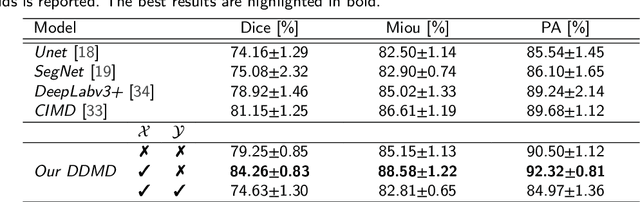
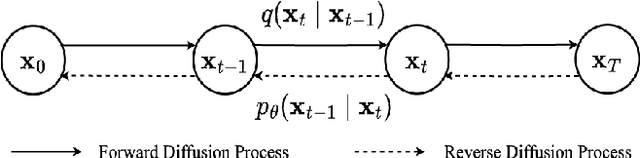
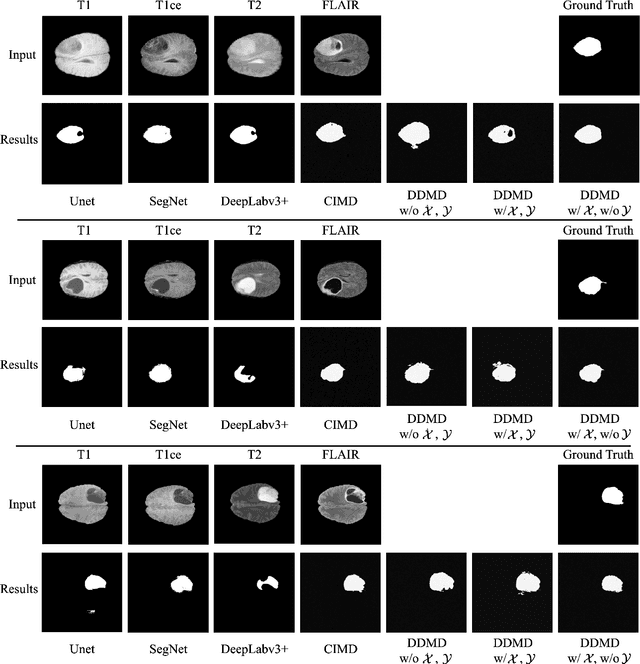
Diffusion probabilistic models (DPMs) have exhibited significant effectiveness in computer vision tasks, particularly in image generation. However, their notable performance heavily relies on labelled datasets, which limits their application in medical images due to the associated high-cost annotations. Current DPM-related methods for lesion detection in medical imaging, which can be categorized into two distinct approaches, primarily rely on image-level annotations. The first approach, based on anomaly detection, involves learning reference healthy brain representations and identifying anomalies based on the difference in inference results. In contrast, the second approach, resembling a segmentation task, employs only the original brain multi-modalities as prior information for generating pixel-level annotations. In this paper, our proposed model - discrepancy distribution medical diffusion (DDMD) - for lesion detection in brain MRI introduces a novel framework by incorporating distinctive discrepancy features, deviating from the conventional direct reliance on image-level annotations or the original brain modalities. In our method, the inconsistency in image-level annotations is translated into distribution discrepancies among heterogeneous samples while preserving information within homogeneous samples. This property retains pixel-wise uncertainty and facilitates an implicit ensemble of segmentation, ultimately enhancing the overall detection performance. Thorough experiments conducted on the BRATS2020 benchmark dataset containing multimodal MRI scans for brain tumour detection demonstrate the great performance of our approach in comparison to state-of-the-art methods.
Non-negative Subspace Feature Representation for Few-shot Learning in Medical Imaging
Apr 04, 2024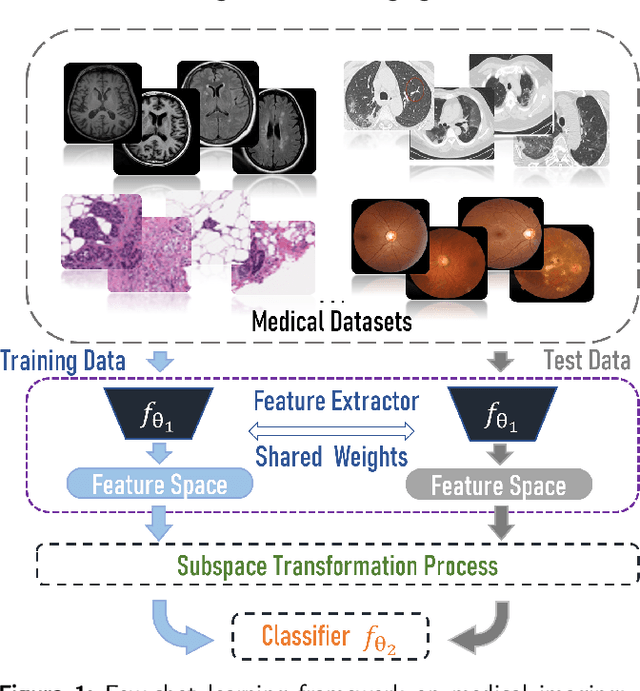
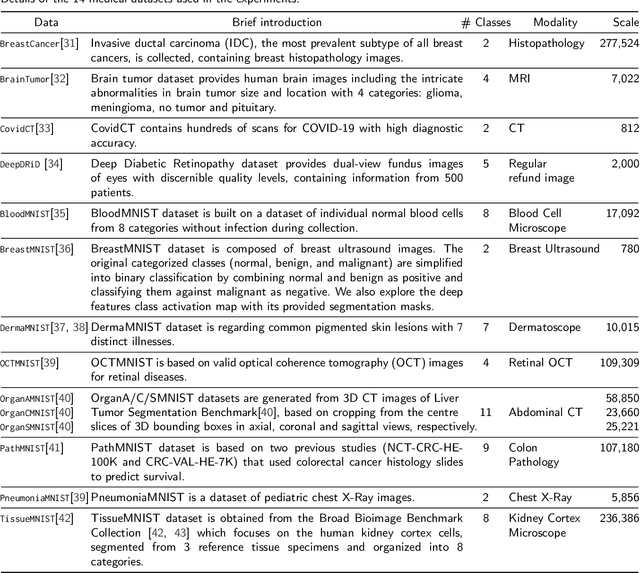
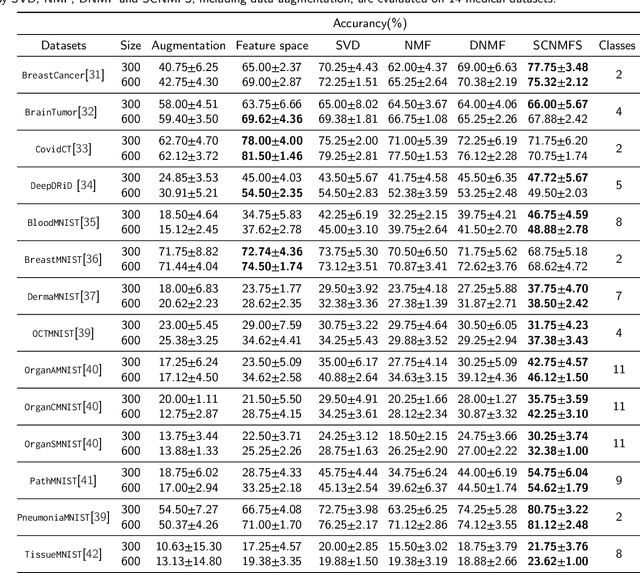
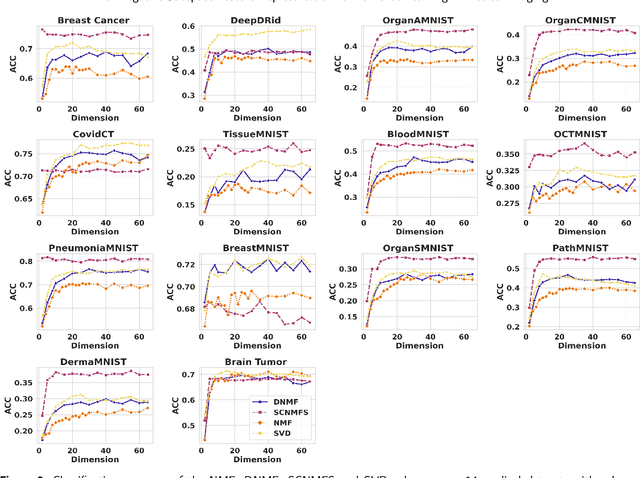
Unlike typical visual scene recognition domains, in which massive datasets are accessible to deep neural networks, medical image interpretations are often obstructed by the paucity of data. In this paper, we investigate the effectiveness of data-based few-shot learning in medical imaging by exploring different data attribute representations in a low-dimensional space. We introduce different types of non-negative matrix factorization (NMF) in few-shot learning, addressing the data scarcity issue in medical image classification. Extensive empirical studies are conducted in terms of validating the effectiveness of NMF, especially its supervised variants (e.g., discriminative NMF, and supervised and constrained NMF with sparseness), and the comparison with principal component analysis (PCA), i.e., the collaborative representation-based dimensionality reduction technique derived from eigenvectors. With 14 different datasets covering 11 distinct illness categories, thorough experimental results and comparison with related techniques demonstrate that NMF is a competitive alternative to PCA for few-shot learning in medical imaging, and the supervised NMF algorithms are more discriminative in the subspace with greater effectiveness. Furthermore, we show that the part-based representation of NMF, especially its supervised variants, is dramatically impactful in detecting lesion areas in medical imaging with limited samples.
Thinking Outside the Box: Orthogonal Approach to Equalizing Protected Attributes
Nov 21, 2023There is growing concern that the potential of black box AI may exacerbate health-related disparities and biases such as gender and ethnicity in clinical decision-making. Biased decisions can arise from data availability and collection processes, as well as from the underlying confounding effects of the protected attributes themselves. This work proposes a machine learning-based orthogonal approach aiming to analyze and suppress the effect of the confounder through discriminant dimensionality reduction and orthogonalization of the protected attributes against the primary attribute information. By doing so, the impact of the protected attributes on disease diagnosis can be realized, undesirable feature correlations can be mitigated, and the model prediction performance can be enhanced.
Depth Insight -- Contribution of Different Features to Indoor Single-image Depth Estimation
Nov 16, 2023Depth estimation from a single image is a challenging problem in computer vision because binocular disparity or motion information is absent. Whereas impressive performances have been reported in this area recently using end-to-end trained deep neural architectures, as to what cues in the images that are being exploited by these black box systems is hard to know. To this end, in this work, we quantify the relative contributions of the known cues of depth in a monocular depth estimation setting using an indoor scene data set. Our work uses feature extraction techniques to relate the single features of shape, texture, colour and saturation, taken in isolation, to predict depth. We find that the shape of objects extracted by edge detection substantially contributes more than others in the indoor setting considered, while the other features also have contributions in varying degrees. These insights will help optimise depth estimation models, boosting their accuracy and robustness. They promise to broaden the practical applications of vision-based depth estimation. The project code is attached to the supplementary material and will be published on GitHub.
IIHT: Medical Report Generation with Image-to-Indicator Hierarchical Transformer
Aug 10, 2023



Automated medical report generation has become increasingly important in medical analysis. It can produce computer-aided diagnosis descriptions and thus significantly alleviate the doctors' work. Inspired by the huge success of neural machine translation and image captioning, various deep learning methods have been proposed for medical report generation. However, due to the inherent properties of medical data, including data imbalance and the length and correlation between report sequences, the generated reports by existing methods may exhibit linguistic fluency but lack adequate clinical accuracy. In this work, we propose an image-to-indicator hierarchical transformer (IIHT) framework for medical report generation. It consists of three modules, i.e., a classifier module, an indicator expansion module and a generator module. The classifier module first extracts image features from the input medical images and produces disease-related indicators with their corresponding states. The disease-related indicators are subsequently utilised as input for the indicator expansion module, incorporating the "data-text-data" strategy. The transformer-based generator then leverages these extracted features along with image features as auxiliary information to generate final reports. Furthermore, the proposed IIHT method is feasible for radiologists to modify disease indicators in real-world scenarios and integrate the operations into the indicator expansion module for fluent and accurate medical report generation. Extensive experiments and comparisons with state-of-the-art methods under various evaluation metrics demonstrate the great performance of the proposed method.
GO-LDA: Generalised Optimal Linear Discriminant Analysis
May 23, 2023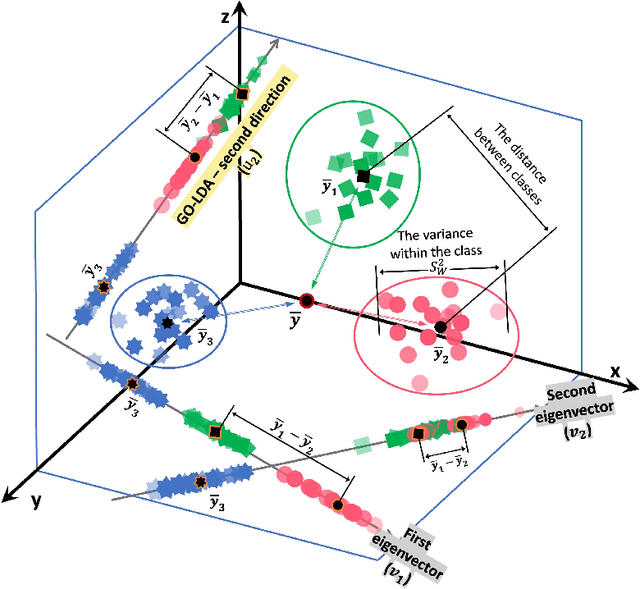
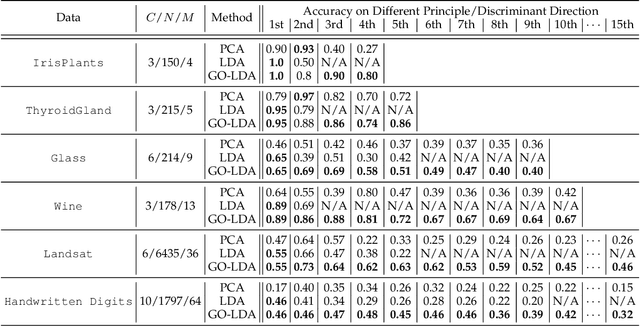
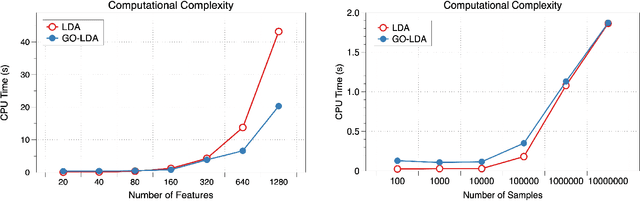
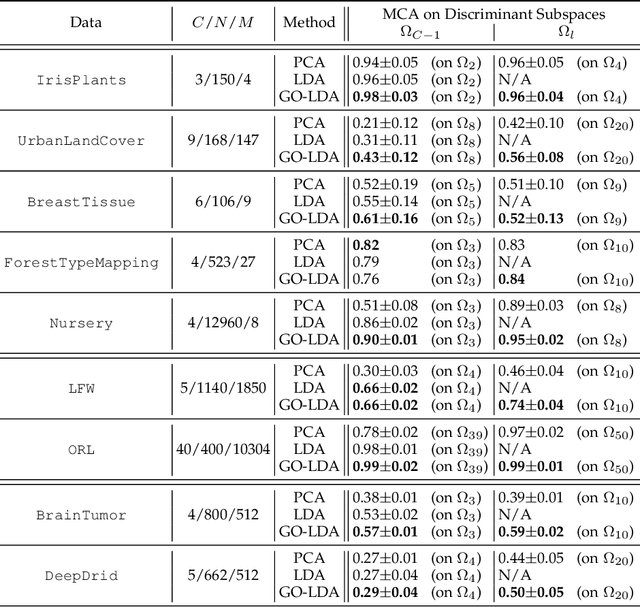
Linear discriminant analysis (LDA) has been a useful tool in pattern recognition and data analysis research and practice. While linearity of class boundaries cannot always be expected, nonlinear projections through pre-trained deep neural networks have served to map complex data onto feature spaces in which linear discrimination has served well. The solution to binary LDA is obtained by eigenvalue analysis of within-class and between-class scatter matrices. It is well known that the multiclass LDA is solved by an extension to the binary LDA, a generalised eigenvalue problem, from which the largest subspace that can be extracted is of dimension one lower than the number of classes in the given problem. In this paper, we show that, apart from the first of the discriminant directions, the generalised eigenanalysis solution to multiclass LDA does neither yield orthogonal discriminant directions nor maximise discrimination of projected data along them. Surprisingly, to the best of our knowledge, this has not been noted in decades of literature on LDA. To overcome this drawback, we present a derivation with a strict theoretical support for sequentially obtaining discriminant directions that are orthogonal to previously computed ones and maximise in each step the Fisher criterion. We show distributions of projections along these axes and demonstrate that discrimination of data projected onto these discriminant directions has optimal separation, which is much higher than those from the generalised eigenvectors of the multiclass LDA. Using a wide range of benchmark tasks, we present a comprehensive empirical demonstration that on a number of pattern recognition and classification problems, the optimal discriminant subspaces obtained by the proposed method, referred to as GO-LDA (Generalised Optimal LDA), can offer superior accuracy.
Prompt position really matters in few-shot and zero-shot NLU tasks
May 23, 2023Prompt-based models have made remarkable advancements in the fields of zero-shot and few-shot learning, attracting a lot of attention from researchers. Developing an effective prompt template plays a critical role. However, prior studies have mainly focused on prompt vocabulary selection or embedding initialization with the reserved prompt position fixed. In this empirical study, we conduct the most comprehensive analysis to date of prompt position option for natural language understanding tasks. Our findings quantify the substantial impact prompt position has on model performance. We observe that the prompt position used in prior studies is often sub-optimal for both zero-shot and few-shot settings. These findings suggest prompt position optimisation as an interesting research direction alongside the existing focus on prompt engineering.
Long short-term memory networks and laglasso for bond yield forecasting: Peeping inside the black box
May 05, 2020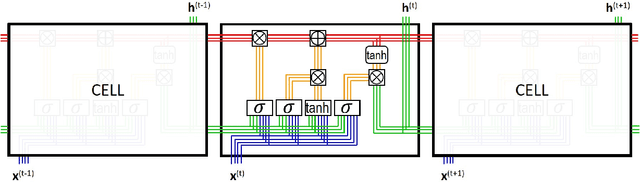

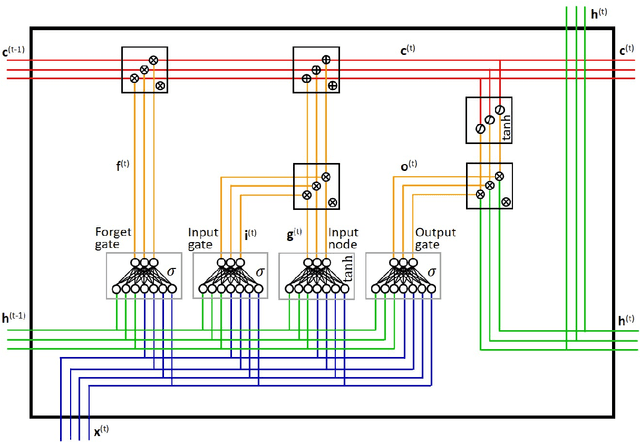
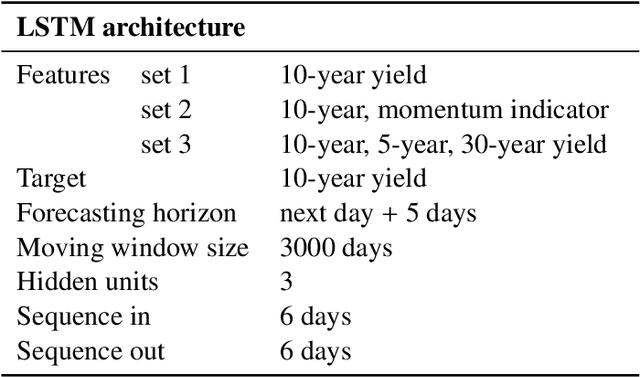
Modern decision-making in fixed income asset management benefits from intelligent systems, which involve the use of state-of-the-art machine learning models and appropriate methodologies. We conduct the first study of bond yield forecasting using long short-term memory (LSTM) networks, validating its potential and identifying its memory advantage. Specifically, we model the 10-year bond yield using univariate LSTMs with three input sequences and five forecasting horizons. We compare those with multilayer perceptrons (MLP), univariate and with the most relevant features. To demystify the notion of black box associated with LSTMs, we conduct the first internal study of the model. To this end, we calculate the LSTM signals through time, at selected locations in the memory cell, using sequence-to-sequence architectures, uni and multivariate. We then proceed to explain the states' signals using exogenous information, for what we develop the LSTM-LagLasso methodology. The results show that the univariate LSTM model with additional memory is capable of achieving similar results as the multivariate MLP using macroeconomic and market information. Furthermore, shorter forecasting horizons require smaller input sequences and vice-versa. The most remarkable property found consistently in the LSTM signals, is the activation/deactivation of units through time, and the specialisation of units by yield range or feature. Those signals are complex but can be explained by exogenous variables. Additionally, some of the relevant features identified via LSTM-LagLasso are not commonly used in forecasting models. In conclusion, our work validates the potential of LSTMs and methodologies for bonds, providing additional tools for financial practitioners.