 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Inclusive Adaptive Physics-Informed Neural Network for Microbial Interaction Modelling
Jun 05, 2026Physics-Informed Neural Network (PINN) is a way of including knowledge in the form of equations in Machine Learning methods. Beyond equations, knowledge exists in other forms, such as text and network structure. While existing PINN-based approaches discover equation parameters from data, they rely solely on experimental measurements. We propose a new PINN framework that enriches parameter discovery by incorporating auxiliary knowledge sources. We instantiate our framework for microbiology, where generalised Lotka-Volterra (gLV) serves as a biological foundation for modelling microbial communities. We demonstrate that incorporating knowledge improves microbial community modelling. Our framework enriches the gLV parameters using peer-reviewed metagenomics literature, as text provides biological context on external influences that gLV alone cannot capture. We combine this knowledge with experimental measurements of microbial abundance using a data-driven integration approach. We integrate network-based structural knowledge by explicitly modelling microbial interactions. Our knowledge-inclusive framework infers microbial networks, revealing ecological insights. We validate these findings against ecological roles documented in the literature. We evaluate on real and simulated datasets spanning human- and plant-associated microbial communities. Our framework improves over the state-of-the-art by up to 53%, even without knowledge. Knowledge addition yields gains of up to 23% in Bray-Curtis Dissimilarity-based accuracy and 47% in $\mathrm{R}^2$.
Parameter-efficient Prompt Tuning and Hierarchical Textual Guidance for Few-shot Whole Slide Image Classification
Mar 23, 2026Whole Slide Images (WSIs) are giga-pixel in scale and are typically partitioned into small instances in WSI classification pipelines for computational feasibility. However, obtaining extensive instance level annotations is costly, making few-shot weakly supervised WSI classification (FSWC) crucial for learning from limited slide-level labels. Recently, pre-trained vision-language models (VLMs) have been adopted in FSWC, yet they exhibit several limitations. Existing prompt tuning methods in FSWC substantially increase both the number of trainable parameters and inference overhead. Moreover, current methods discard instances with low alignment to text embeddings from VLMs, potentially leading to information loss. To address these challenges, we propose two key contributions. First, we introduce a new parameter efficient prompt tuning method by scaling and shifting features in text encoder, which significantly reduces the computational cost. Second, to leverage not only the pre-trained knowledge of VLMs, but also the inherent hierarchical structure of WSIs, we introduce a WSI representation learning approach with a soft hierarchical textual guidance strategy without utilizing hard instance filtering. Comprehensive evaluations on pathology datasets covering breast, lung, and ovarian cancer types demonstrate consistent improvements up-to 10.9%, 7.8%, and 13.8% respectively, over the state-of-the-art methods in FSWC. Our method reduces the number of trainable parameters by 18.1% on both breast and lung cancer datasets, and 5.8% on the ovarian cancer dataset, while also excelling at weakly-supervised tumor localization. Code at https://github.com/Jayanie/HIPSS.
MSRAMIE: Multimodal Structured Reasoning Agent for Multi-instruction Image Editing
Mar 17, 2026Existing instruction-based image editing models perform well with simple, single-step instructions but degrade in realistic scenarios that involve multiple, lengthy, and interdependent directives. A main cause is the scarcity of training data with complex multi-instruction annotations. However, it is costly to collect such data and retrain these models. To address this challenge, we propose MSRAMIE, a training-free agent framework built on Multimodal Large Language Model (MLLM). MSRAMIE takes existing editing models as plug-in components and handle multi-instruction tasks via structured multimodal reasoning. It orchestrates iterative interactions between an MLLM-based Instructor and an image editing Actor, introducing a novel reasoning topology that comprises the proposed Tree-of-States and Graph-of-References. During inference, complex instructions are decomposed into multiple editing steps which enable state transitions, cross-step information aggregation, and original input recall, which enables systematic exploration of the image editing space and flexible progressive output refinement. The visualizable inference topology further provides interpretable and controllable decision pathways. Experiments show that as the instruction complexity increases, MSRAMIE can improve instruction following over 15% and increases the probability of finishing all modifications in a single run over 100%, while preserving perceptual quality and maintaining visual consistency.
From Specification to Architecture: A Theory Compiler for Knowledge-Guided Machine Learning
Mar 15, 2026Theory-guided machine learning has demonstrated that including authentic domain knowledge directly into model design improves performance, sample efficiency and out-of-distribution generalisation. Yet the process by which a formal domain theory is translated into architectural constraints remains entirely manual, specific to each domain formalism, and devoid of any formal correctness guarantee. This translation is non-transferable between domains, not verified, and does not scale. We propose the Theory Compiler: a system that accepts a typed, machine-readable domain theory as input and automatically produces an architecture whose function space is provably constrained to be consistent with that theory by construction, not by regularisation. We identify three foundational open problems whose resolution defines our research agenda: (1) designing a universal theory formalisation language with decidable type-checking; (2) constructing a compositionally correct compilation algorithm from theory primitives to architectural modules; and (3) establishing soundness and completeness criteria for formal verification. We further conjecture that compiled architectures match or exceed manually-designed counterparts in generalisation performance while requiring substantially less training data, a claim we ground in classical statistical learning theory. We argue that recent advances in formal machine learning theory, large language models, and the growth of an interdisciplinary research community have made this paradigm achievable for the first time.
Flood-LDM: Generalizable Latent Diffusion Models for rapid and accurate zero-shot High-Resolution Flood Mapping
Nov 18, 2025



Flood prediction is critical for emergency planning and response to mitigate human and economic losses. Traditional physics-based hydrodynamic models generate high-resolution flood maps using numerical methods requiring fine-grid discretization; which are computationally intensive and impractical for real-time large-scale applications. While recent studies have applied convolutional neural networks for flood map super-resolution with good accuracy and speed, they suffer from limited generalizability to unseen areas. In this paper, we propose a novel approach that leverages latent diffusion models to perform super-resolution on coarse-grid flood maps, with the objective of achieving the accuracy of fine-grid flood maps while significantly reducing inference time. Experimental results demonstrate that latent diffusion models substantially decrease the computational time required to produce high-fidelity flood maps without compromising on accuracy, enabling their use in real-time flood risk management. Moreover, diffusion models exhibit superior generalizability across different physical locations, with transfer learning further accelerating adaptation to new geographic regions. Our approach also incorporates physics-informed inputs, addressing the common limitation of black-box behavior in machine learning, thereby enhancing interpretability. Code is available at https://github.com/neosunhan/flood-diff.
Arch-LLM: Taming LLMs for Neural Architecture Generation via Unsupervised Discrete Representation Learning
Mar 28, 2025Unsupervised representation learning has been widely explored across various modalities, including neural architectures, where it plays a key role in downstream applications like Neural Architecture Search (NAS). These methods typically learn an unsupervised representation space before generating/ sampling architectures for the downstream search. A common approach involves the use of Variational Autoencoders (VAEs) to map discrete architectures onto a continuous representation space, however, sampling from these spaces often leads to a high percentage of invalid or duplicate neural architectures. This could be due to the unnatural mapping of inherently discrete architectural space onto a continuous space, which emphasizes the need for a robust discrete representation of these architectures. To address this, we introduce a Vector Quantized Variational Autoencoder (VQ-VAE) to learn a discrete latent space more naturally aligned with the discrete neural architectures. In contrast to VAEs, VQ-VAEs (i) map each architecture into a discrete code sequence and (ii) allow the prior to be learned by any generative model rather than assuming a normal distribution. We then represent these architecture latent codes as numerical sequences and train a text-to-text model leveraging a Large Language Model to learn and generate sequences representing architectures. We experiment our method with Inception/ ResNet-like cell-based search spaces, namely NAS-Bench-101 and NAS-Bench-201. Compared to VAE-based methods, our approach improves the generation of valid and unique architectures by over 80% on NASBench-101 and over 8% on NASBench-201. Finally, we demonstrate the applicability of our method in NAS employing a sequence-modeling-based NAS algorithm.
SphOR: A Representation Learning Perspective on Open-set Recognition for Identifying Unknown Classes in Deep Learning Models
Mar 11, 2025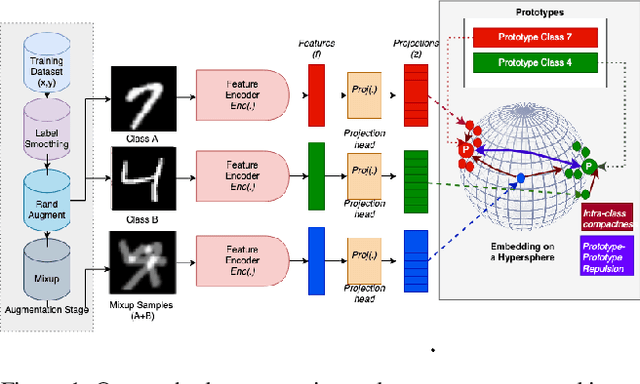



The widespread use of deep learning classifiers necessitates Open-set recognition (OSR), which enables the identification of input data not only from classes known during training but also from unknown classes that might be present in test data. Many existing OSR methods are computationally expensive due to the reliance on complex generative models or suffer from high training costs. We investigate OSR from a representation-learning perspective, specifically through spherical embeddings. We introduce SphOR, a computationally efficient representation learning method that models the feature space as a mixture of von Mises-Fisher distributions. This approach enables the use of semantically ambiguous samples during training, to improve the detection of samples from unknown classes. We further explore the relationship between OSR performance and key representation learning properties which influence how well features are structured in high-dimensional space. Extensive experiments on multiple OSR benchmarks demonstrate the effectiveness of our method, producing state-of-the-art results, with improvements up-to 6% that validate its performance.
Unmasking the Unknown: Facial Deepfake Detection in the Open-Set Paradigm
Mar 11, 2025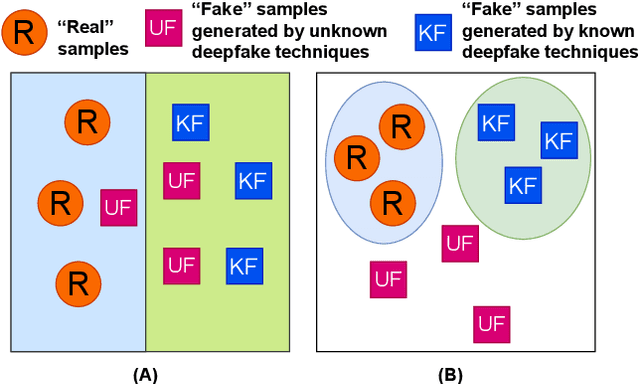
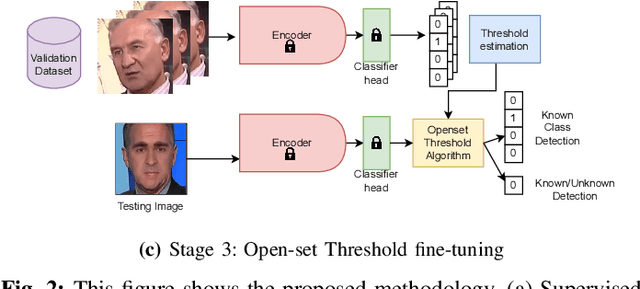
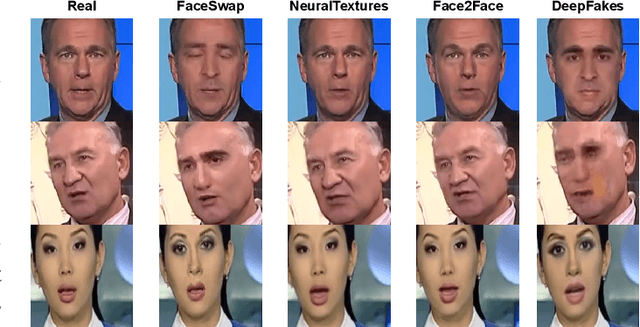
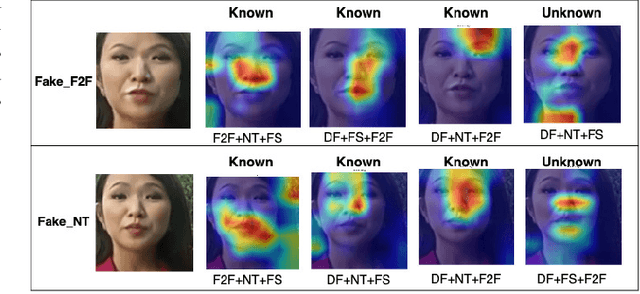
Facial forgery methods such as deepfakes can be misused for identity manipulation and spreading misinformation. They have evolved alongside advancements in generative AI, leading to new and more sophisticated forgery techniques that diverge from existing 'known' methods. Conventional deepfake detection methods use the closedset paradigm, thus limiting their applicability to detecting forgeries created using methods that are not part of the training dataset. In this paper, we propose a shift from the closed-set paradigm for deepfake detection. In the open-set paradigm, models are designed not only to identify images created by known facial forgery methods but also to identify and flag those produced by previously unknown methods as 'unknown' and not as unforged/real/unmanipulated. In this paper, we propose an open-set deepfake classification algorithm based on supervised contrastive learning. The open-set paradigm used in our model allows it to function as a more robust tool capable of handling emerging and unseen deepfake techniques, enhancing reliability and confidence, and complementing forensic analysis. In open-set paradigm, we identify three groups including the "unknown group that is neither considered known deepfake nor real. We investigate deepfake open-set classification across three scenarios, classifying deepfakes from unknown methods not as real, distinguishing real images from deepfakes, and classifying deepfakes from known methods, using the FaceForensics++ dataset as a benchmark. Our method achieves state of the art results in the first two tasks and competitive results in the third task.
TT-MPD: Test Time Model Pruning and Distillation
Dec 10, 2024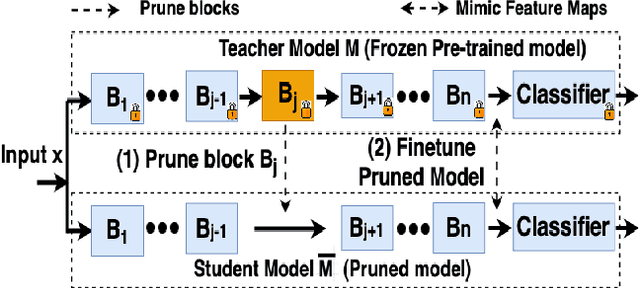

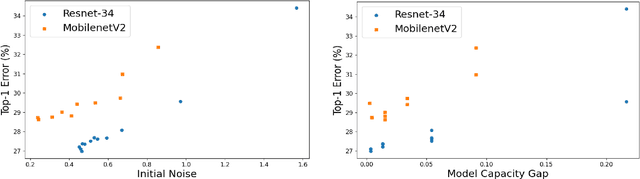
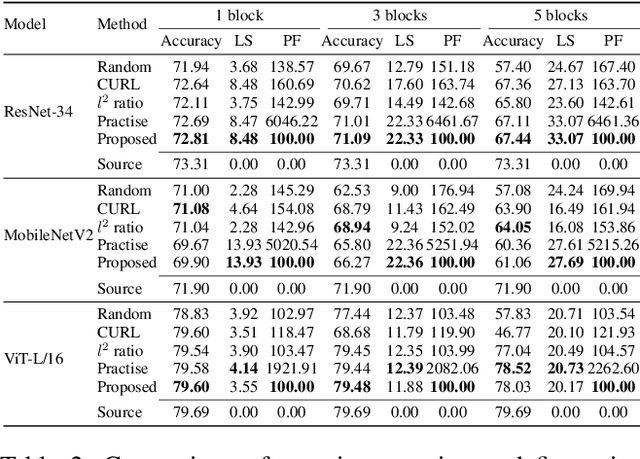
Pruning can be an effective method of compressing large pre-trained models for inference speed acceleration. Previous pruning approaches rely on access to the original training dataset for both pruning and subsequent fine-tuning. However, access to the training data can be limited due to concerns such as data privacy and commercial confidentiality. Furthermore, with covariate shift (disparities between test and training data distributions), pruning and finetuning with training datasets can hinder the generalization of the pruned model to test data. To address these issues, pruning and finetuning the model with test time samples becomes essential. However, test-time model pruning and fine-tuning incur additional computation costs and slow down the model's prediction speed, thus posing efficiency issues. Existing pruning methods are not efficient enough for test time model pruning setting, since finetuning the pruned model is needed to evaluate the importance of removable components. To address this, we propose two variables to approximate the fine-tuned accuracy. We then introduce an efficient pruning method that considers the approximated finetuned accuracy and potential inference latency saving. To enhance fine-tuning efficiency, we propose an efficient knowledge distillation method that only needs to generate pseudo labels for a small set of finetuning samples one time, thereby reducing the expensive pseudo-label generation cost. Experimental results demonstrate that our method achieves a comparable or superior tradeoff between test accuracy and inference latency, with a 32% relative reduction in pruning and finetuning time compared to the best existing method.
Rethinking Time Series Forecasting with LLMs via Nearest Neighbor Contrastive Learning
Dec 06, 2024



Adapting Large Language Models (LLMs) that are extensively trained on abundant text data, and customizing the input prompt to enable time series forecasting has received considerable attention. While recent work has shown great potential for adapting the learned prior of LLMs, the formulation of the prompt to finetune LLMs remains challenging as prompt should be aligned with time series data. Additionally, current approaches do not effectively leverage word token embeddings which embody the rich representation space learned by LLMs. This emphasizes the need for a robust approach to formulate the prompt which utilizes the word token embeddings while effectively representing the characteristics of the time series. To address these challenges, we propose NNCL-TLLM: Nearest Neighbor Contrastive Learning for Time series forecasting via LLMs. First, we generate time series compatible text prototypes such that each text prototype represents both word token embeddings in its neighborhood and time series characteristics via end-to-end finetuning. Next, we draw inspiration from Nearest Neighbor Contrastive Learning to formulate the prompt while obtaining the top-$k$ nearest neighbor time series compatible text prototypes. We then fine-tune the layer normalization and positional embeddings of the LLM, keeping the other layers intact, reducing the trainable parameters and decreasing the computational cost. Our comprehensive experiments demonstrate that NNCL-TLLM outperforms in few-shot forecasting while achieving competitive or superior performance over the state-of-the-art methods in long-term and short-term forecasting tasks.