 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Theoretic Stopping Rules for Document Screening
Jun 05, 2026Deciding when to stop reviewing the results of a search is a common problem with multiple applications. Existing stopping rules developed within Technology-Assisted Review (TAR) aim to achieve a pre-specified recall target and do not take into account the reason for examining the results, potentially leading to sub-optimal recommendations. This paper applies decision theory to the problem and uses it to derive three practical stopping policies based on the Expected Value of Perfect Information. The approach is applied to two professional search tasks: patent examining and systematic reviewing. Experiments on CLEF-IP and medical systematic review datasets show that the proposed approach generally produces more appropriate stopping decisions than existing methods, as demonstrated by higher net utility under the evaluated cost and payoff settings.
Generating Search Explanations using Large Language Models
Jul 22, 2025Aspect-oriented explanations in search results are typically concise text snippets placed alongside retrieved documents to serve as explanations that assist users in efficiently locating relevant information. While Large Language Models (LLMs) have demonstrated exceptional performance for a range of problems, their potential to generate explanations for search results has not been explored. This study addresses that gap by leveraging both encoder-decoder and decoder-only LLMs to generate explanations for search results. The explanations generated are consistently more accurate and plausible explanations than those produced by a range of baseline models.
The Next Phase of Scientific Fact-Checking: Advanced Evidence Retrieval from Complex Structured Academic Papers
Jun 25, 2025


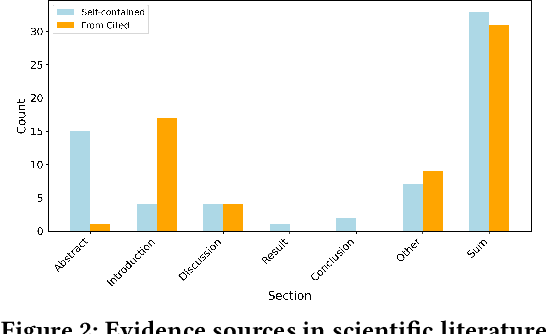
Scientific fact-checking aims to determine the veracity of scientific claims by retrieving and analysing evidence from research literature. The problem is inherently more complex than general fact-checking since it must accommodate the evolving nature of scientific knowledge, the structural complexity of academic literature and the challenges posed by long-form, multimodal scientific expression. However, existing approaches focus on simplified versions of the problem based on small-scale datasets consisting of abstracts rather than full papers, thereby avoiding the distinct challenges associated with processing complete documents. This paper examines the limitations of current scientific fact-checking systems and reveals the many potential features and resources that could be exploited to advance their performance. It identifies key research challenges within evidence retrieval, including (1) evidence-driven retrieval that addresses semantic limitations and topic imbalance (2) time-aware evidence retrieval with citation tracking to mitigate outdated information, (3) structured document parsing to leverage long-range context, (4) handling complex scientific expressions, including tables, figures, and domain-specific terminology and (5) assessing the credibility of scientific literature. Preliminary experiments were conducted to substantiate these challenges and identify potential solutions. This perspective paper aims to advance scientific fact-checking with a specialised IR system tailored for real-world applications.
A Generalised and Adaptable Reinforcement Learning Stopping Method
May 03, 2025This paper presents a Technology Assisted Review (TAR) stopping approach based on Reinforcement Learning (RL). Previous such approaches offered limited control over stopping behaviour, such as fixing the target recall and tradeoff between preferring to maximise recall or cost. These limitations are overcome by introducing a novel RL environment, GRLStop, that allows a single model to be applied to multiple target recalls, balances the recall/cost tradeoff and integrates a classifier. Experiments were carried out on six benchmark datasets (CLEF e-Health datasets 2017-9, TREC Total Recall, TREC Legal and Reuters RCV1) at multiple target recall levels. Results showed that the proposed approach to be effective compared to multiple baselines in addition to offering greater flexibility.
General algorithm of assigning raster features to vector maps at any resolution or scale
Jul 15, 2024
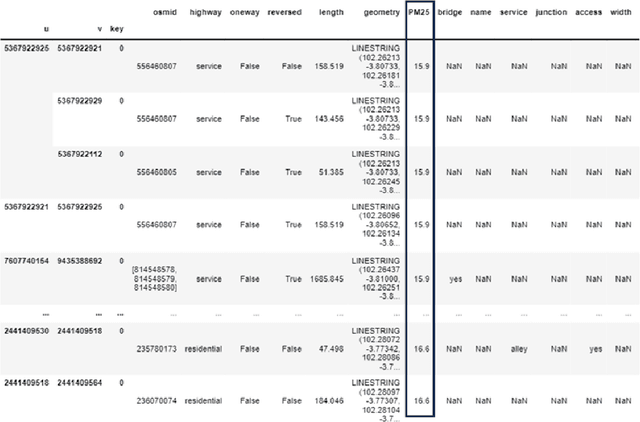
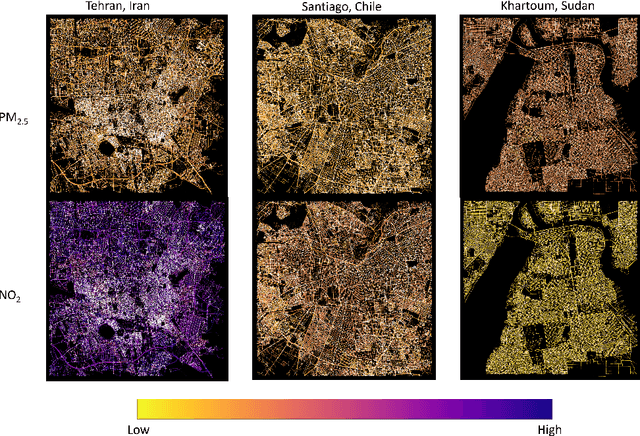
The fusion of multi-source data is essential for a comprehensive analysis of geographic applications. Due to distinct data structures, the fusion process tends to encounter technical difficulties in terms of preservation of the intactness of each source data. Furthermore, a lack of generalized methods is a problem when the method is expected to be applicable in multiple resolutions, sizes, or scales of raster and vector data, to what is being processed. In this study, we propose a general algorithm of assigning features from raster data (concentrations of air pollutants) to vector components (roads represented by edges) in city maps through the iterative construction of virtual layers to expand geolocation from a city centre to boundaries in a 2D projected map. The construction follows the rule of perfect squares with a slight difference depending on the oddness or evenness of the ratio of city size to raster resolution. We demonstrate the algorithm by applying it to assign accurate PM$_{2.5}$ and NO$_{2}$ concentrations to roads in 1692 cities globally for a potential graph-based pollution analysis. This method could pave the way for agile studies on urgent climate issues by providing a generic and efficient method to accurately fuse multiple datasets of varying scales and compositions.
Challenges and Opportunities of NLP for HR Applications: A Discussion Paper
May 13, 2024
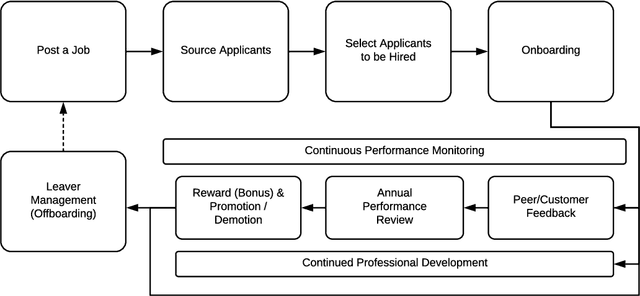
Over the course of the recent decade, tremendous progress has been made in the areas of machine learning and natural language processing, which opened up vast areas of potential application use cases, including hiring and human resource management. We review the use cases for text analytics in the realm of human resources/personnel management, including actually realized as well as potential but not yet implemented ones, and we analyze the opportunities and risks of these.
RLStop: A Reinforcement Learning Stopping Method for TAR
May 03, 2024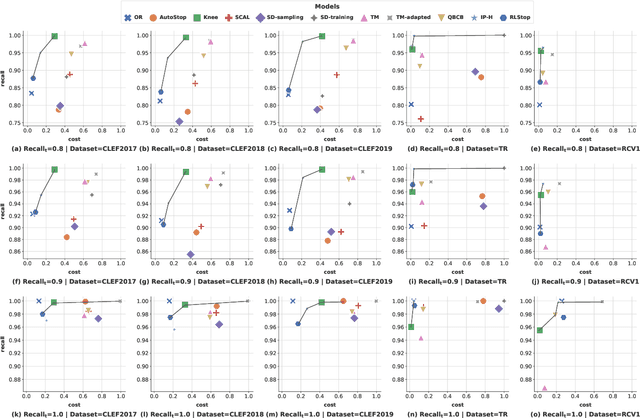
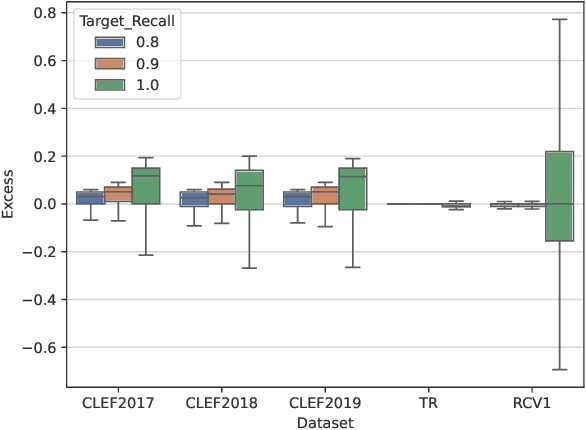
We present RLStop, a novel Technology Assisted Review (TAR) stopping rule based on reinforcement learning that helps minimise the number of documents that need to be manually reviewed within TAR applications. RLStop is trained on example rankings using a reward function to identify the optimal point to stop examining documents. Experiments at a range of target recall levels on multiple benchmark datasets (CLEF e-Health, TREC Total Recall, and Reuters RCV1) demonstrated that RLStop substantially reduces the workload required to screen a document collection for relevance. RLStop outperforms a wide range of alternative approaches, achieving performance close to the maximum possible for the task under some circumstances.
Document Set Expansion with Positive-Unlabelled Learning Using Intractable Density Estimation
Mar 26, 2024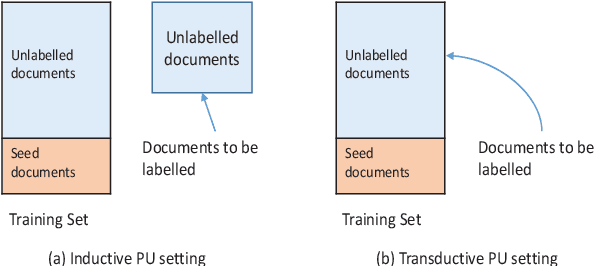
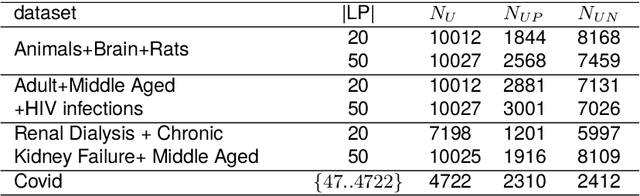
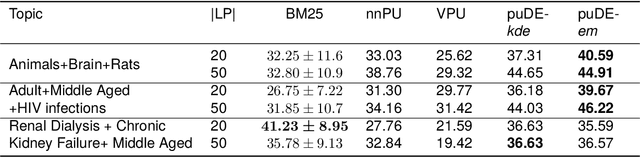
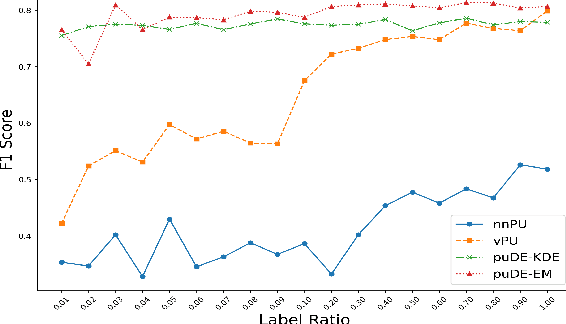
The Document Set Expansion (DSE) task involves identifying relevant documents from large collections based on a limited set of example documents. Previous research has highlighted Positive and Unlabeled (PU) learning as a promising approach for this task. However, most PU methods rely on the unrealistic assumption of knowing the class prior for positive samples in the collection. To address this limitation, this paper introduces a novel PU learning framework that utilizes intractable density estimation models. Experiments conducted on PubMed and Covid datasets in a transductive setting showcase the effectiveness of the proposed method for DSE. Code is available from https://github.com/Beautifuldog01/Document-set-expansion-puDE.
Document Set Expansion with Positive-Unlabeled Learning: A Density Estimation-based Approach
Jan 20, 2024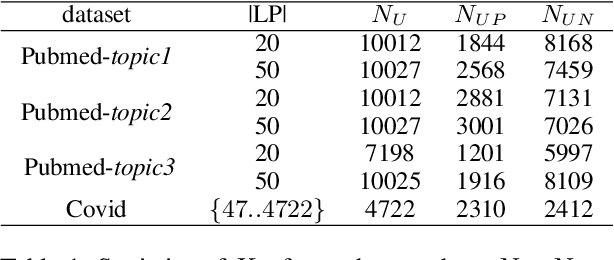
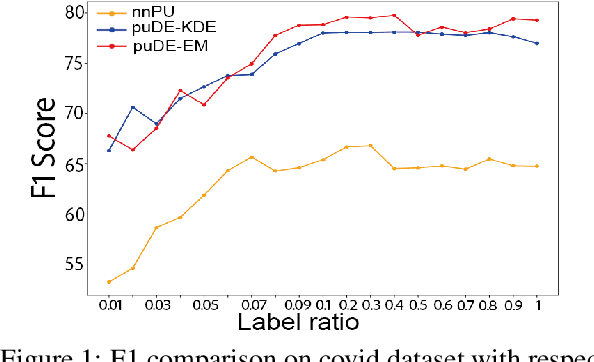
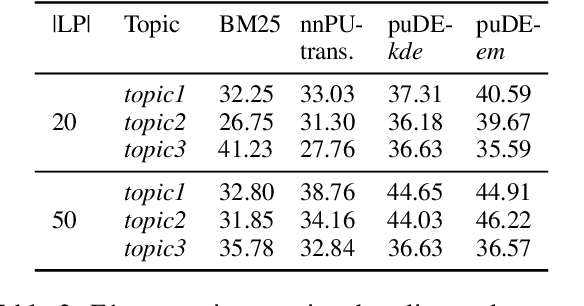
Document set expansion aims to identify relevant documents from a large collection based on a small set of documents that are on a fine-grained topic. Previous work shows that PU learning is a promising method for this task. However, some serious issues remain unresolved, i.e. typical challenges that PU methods suffer such as unknown class prior and imbalanced data, and the need for transductive experimental settings. In this paper, we propose a novel PU learning framework based on density estimation, called puDE, that can handle the above issues. The advantage of puDE is that it neither constrained to the SCAR assumption and nor require any class prior knowledge. We demonstrate the effectiveness of the proposed method using a series of real-world datasets and conclude that our method is a better alternative for the DSE task.
Combining Counting Processes and Classification Improves a Stopping Rule for Technology Assisted Review
Dec 05, 2023Technology Assisted Review (TAR) stopping rules aim to reduce the cost of manually assessing documents for relevance by minimising the number of documents that need to be examined to ensure a desired level of recall. This paper extends an effective stopping rule using information derived from a text classifier that can be trained without the need for any additional annotation. Experiments on multiple data sets (CLEF e-Health, TREC Total Recall, TREC Legal and RCV1) showed that the proposed approach consistently improves performance and outperforms several alternative methods.