Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Set Expansion with Positive-Unlabelled Learning Using Intractable Density Estimation
Paper and Code
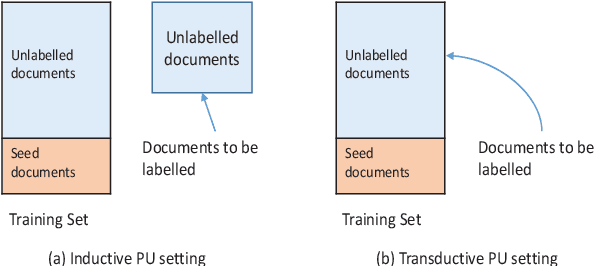
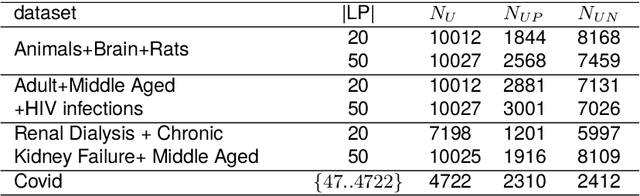
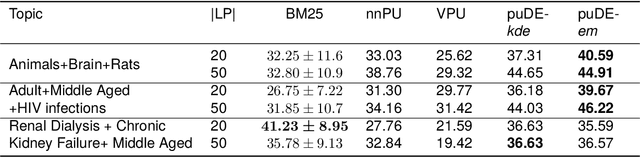
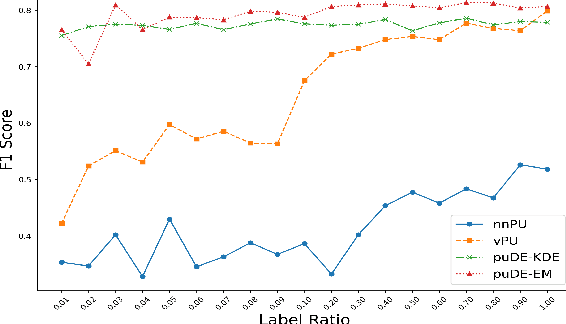
The Document Set Expansion (DSE) task involves identifying relevant documents from large collections based on a limited set of example documents. Previous research has highlighted Positive and Unlabeled (PU) learning as a promising approach for this task. However, most PU methods rely on the unrealistic assumption of knowing the class prior for positive samples in the collection. To address this limitation, this paper introduces a novel PU learning framework that utilizes intractable density estimation models. Experiments conducted on PubMed and Covid datasets in a transductive setting showcase the effectiveness of the proposed method for DSE. Code is available from https://github.com/Beautifuldog01/Document-set-expansion-puDE.
* Accepted at LREC-COLING 2024. arXiv admin note: text overlap with
arXiv:2401.11145
View paper on