 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Meet Virtual Cell: A Survey
Oct 09, 2025Large language models (LLMs) are transforming cellular biology by enabling the development of "virtual cells"--computational systems that represent, predict, and reason about cellular states and behaviors. This work provides a comprehensive review of LLMs for virtual cell modeling. We propose a unified taxonomy that organizes existing methods into two paradigms: LLMs as Oracles, for direct cellular modeling, and LLMs as Agents, for orchestrating complex scientific tasks. We identify three core tasks--cellular representation, perturbation prediction, and gene regulation inference--and review their associated models, datasets, evaluation benchmarks, as well as the critical challenges in scalability, generalizability, and interpretability.
Document Set Expansion with Positive-Unlabelled Learning Using Intractable Density Estimation
Mar 26, 2024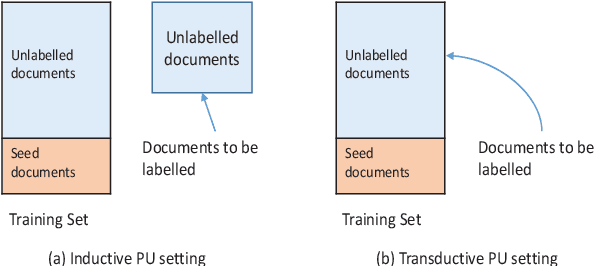
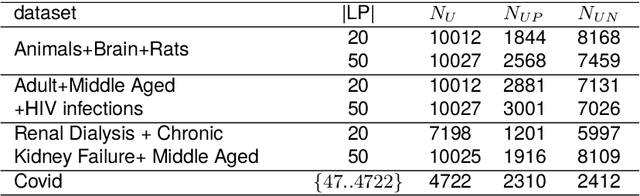
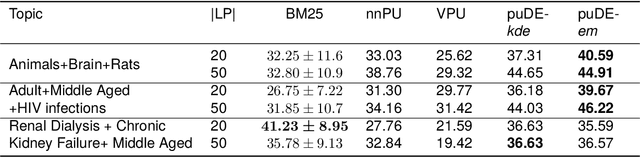
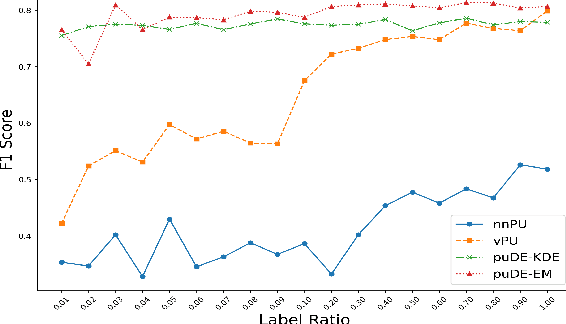
The Document Set Expansion (DSE) task involves identifying relevant documents from large collections based on a limited set of example documents. Previous research has highlighted Positive and Unlabeled (PU) learning as a promising approach for this task. However, most PU methods rely on the unrealistic assumption of knowing the class prior for positive samples in the collection. To address this limitation, this paper introduces a novel PU learning framework that utilizes intractable density estimation models. Experiments conducted on PubMed and Covid datasets in a transductive setting showcase the effectiveness of the proposed method for DSE. Code is available from https://github.com/Beautifuldog01/Document-set-expansion-puDE.
Document Set Expansion with Positive-Unlabeled Learning: A Density Estimation-based Approach
Jan 20, 2024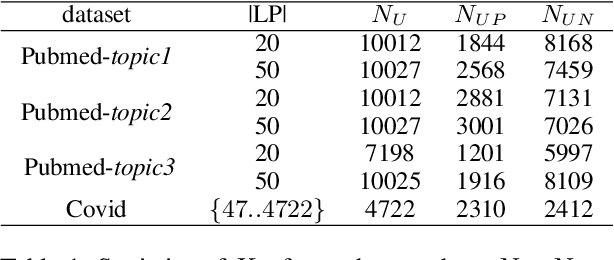
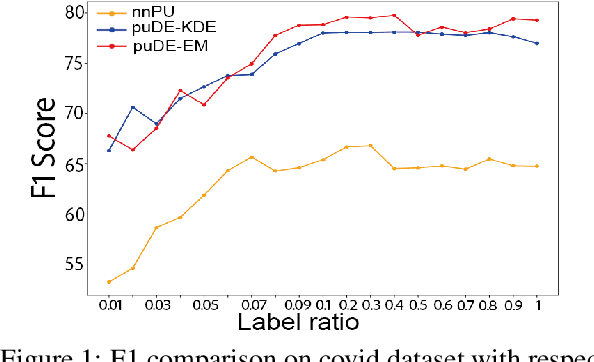
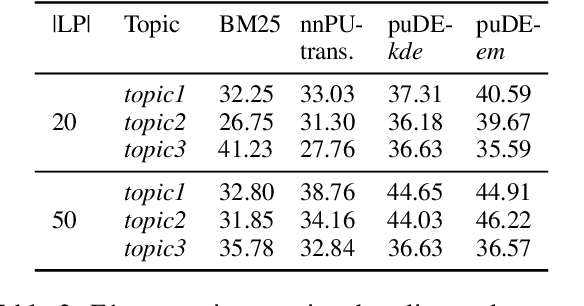
Document set expansion aims to identify relevant documents from a large collection based on a small set of documents that are on a fine-grained topic. Previous work shows that PU learning is a promising method for this task. However, some serious issues remain unresolved, i.e. typical challenges that PU methods suffer such as unknown class prior and imbalanced data, and the need for transductive experimental settings. In this paper, we propose a novel PU learning framework based on density estimation, called puDE, that can handle the above issues. The advantage of puDE is that it neither constrained to the SCAR assumption and nor require any class prior knowledge. We demonstrate the effectiveness of the proposed method using a series of real-world datasets and conclude that our method is a better alternative for the DSE task.