 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-Guided Diffusion Model for Accurate Foot X-ray Synthesis in Hallux Valgus Diagnosis
May 13, 2025Medical image synthesis plays a crucial role in providing anatomically accurate images for diagnosis and treatment. Hallux valgus, which affects approximately 19% of the global population, requires frequent weight-bearing X-rays for assessment, placing additional strain on both patients and healthcare providers. Existing X-ray models often struggle to balance image fidelity, skeletal consistency, and physical constraints, particularly in diffusion-based methods that lack skeletal guidance. We propose the Skeletal-Constrained Conditional Diffusion Model (SCCDM) and introduce KCC, a foot evaluation method utilizing skeletal landmarks. SCCDM incorporates multi-scale feature extraction and attention mechanisms, improving the Structural Similarity Index (SSIM) by 5.72% (0.794) and Peak Signal-to-Noise Ratio (PSNR) by 18.34% (21.40 dB). When combined with KCC, the model achieves an average score of 0.85, demonstrating strong clinical applicability. The code is available at https://github.com/midisec/SCCDM.
Back to Fundamentals: Low-Level Visual Features Guided Progressive Token Pruning
Apr 25, 2025Vision Transformers (ViTs) excel in semantic segmentation but demand significant computation, posing challenges for deployment on resource-constrained devices. Existing token pruning methods often overlook fundamental visual data characteristics. This study introduces 'LVTP', a progressive token pruning framework guided by multi-scale Tsallis entropy and low-level visual features with twice clustering. It integrates high-level semantics and basic visual attributes for precise segmentation. A novel dynamic scoring mechanism using multi-scale Tsallis entropy weighting overcomes limitations of traditional single-parameter entropy. The framework also incorporates low-level feature analysis to preserve critical edge information while optimizing computational cost. As a plug-and-play module, it requires no architectural changes or additional training. Evaluations across multiple datasets show 20%-45% computational reductions with negligible performance loss, outperforming existing methods in balancing cost and accuracy, especially in complex edge regions.
A Dual Adaptive Assignment Approach for Robust Graph-Based Clustering
Oct 29, 2024



Graph clustering is an essential aspect of network analysis that involves grouping nodes into separate clusters. Recent developments in deep learning have resulted in advanced deep graph clustering techniques, which have proven effective in many applications. Nonetheless, these methods often encounter difficulties when dealing with the complexities of real-world graphs, particularly in the presence of noisy edges. Additionally, many denoising graph clustering strategies tend to suffer from lower performance compared to their non-denoised counterparts, training instability, and challenges in scaling to large datasets. To tackle these issues, we introduce a new framework called the Dual Adaptive Assignment Approach for Robust Graph-Based Clustering (RDSA). RDSA consists of three key components: (i) a node embedding module that effectively integrates the graph's topological features and node attributes; (ii) a structure-based soft assignment module that improves graph modularity by utilizing an affinity matrix for node assignments; and (iii) a node-based soft assignment module that identifies community landmarks and refines node assignments to enhance the model's robustness. We assess RDSA on various real-world datasets, demonstrating its superior performance relative to existing state-of-the-art methods. Our findings indicate that RDSA provides robust clustering across different graph types, excelling in clustering effectiveness and robustness, including adaptability to noise, stability, and scalability.
Document Set Expansion with Positive-Unlabelled Learning Using Intractable Density Estimation
Mar 26, 2024
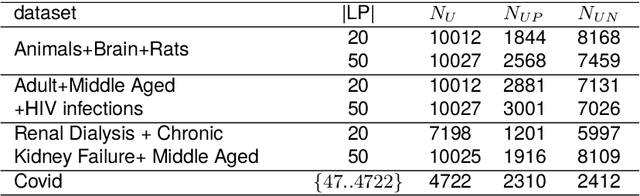
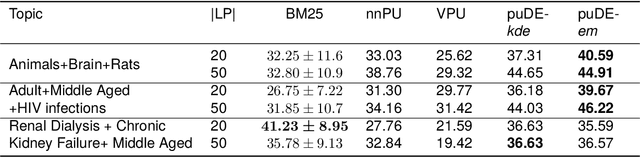
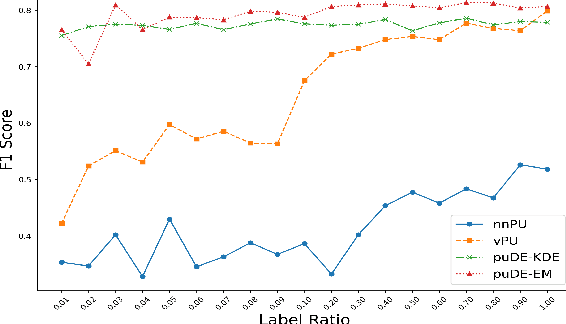
The Document Set Expansion (DSE) task involves identifying relevant documents from large collections based on a limited set of example documents. Previous research has highlighted Positive and Unlabeled (PU) learning as a promising approach for this task. However, most PU methods rely on the unrealistic assumption of knowing the class prior for positive samples in the collection. To address this limitation, this paper introduces a novel PU learning framework that utilizes intractable density estimation models. Experiments conducted on PubMed and Covid datasets in a transductive setting showcase the effectiveness of the proposed method for DSE. Code is available from https://github.com/Beautifuldog01/Document-set-expansion-puDE.
LB-KBQA: Large-language-model and BERT based Knowledge-Based Question and Answering System
Feb 09, 2024

Generative Artificial Intelligence (AI), because of its emergent abilities, has empowered various fields, one typical of which is large language models (LLMs). One of the typical application fields of Generative AI is large language models (LLMs), and the natural language understanding capability of LLM is dramatically improved when compared with conventional AI-based methods. The natural language understanding capability has always been a barrier to the intent recognition performance of the Knowledge-Based-Question-and-Answer (KBQA) system, which arises from linguistic diversity and the newly appeared intent. Conventional AI-based methods for intent recognition can be divided into semantic parsing-based and model-based approaches. However, both of the methods suffer from limited resources in intent recognition. To address this issue, we propose a novel KBQA system based on a Large Language Model(LLM) and BERT (LB-KBQA). With the help of generative AI, our proposed method could detect newly appeared intent and acquire new knowledge. In experiments on financial domain question answering, our model has demonstrated superior effectiveness.
Document Set Expansion with Positive-Unlabeled Learning: A Density Estimation-based Approach
Jan 20, 2024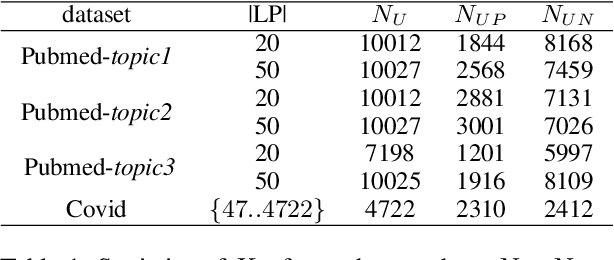
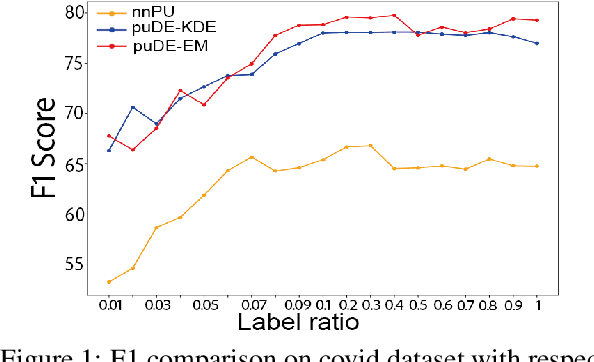
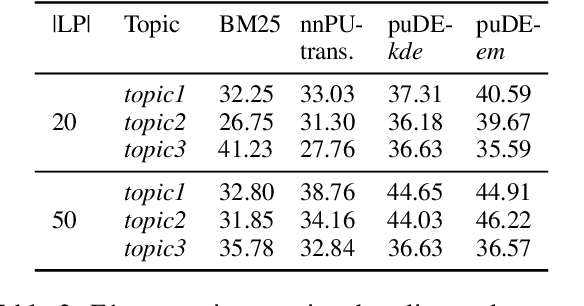
Document set expansion aims to identify relevant documents from a large collection based on a small set of documents that are on a fine-grained topic. Previous work shows that PU learning is a promising method for this task. However, some serious issues remain unresolved, i.e. typical challenges that PU methods suffer such as unknown class prior and imbalanced data, and the need for transductive experimental settings. In this paper, we propose a novel PU learning framework based on density estimation, called puDE, that can handle the above issues. The advantage of puDE is that it neither constrained to the SCAR assumption and nor require any class prior knowledge. We demonstrate the effectiveness of the proposed method using a series of real-world datasets and conclude that our method is a better alternative for the DSE task.
Collaborative Remote Control of Unmanned Ground Vehicles in Virtual Reality
Aug 24, 2022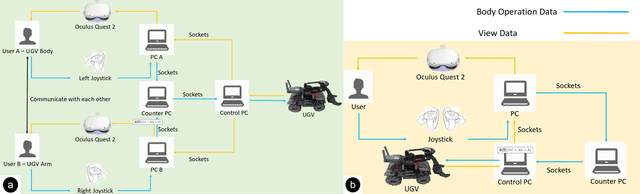
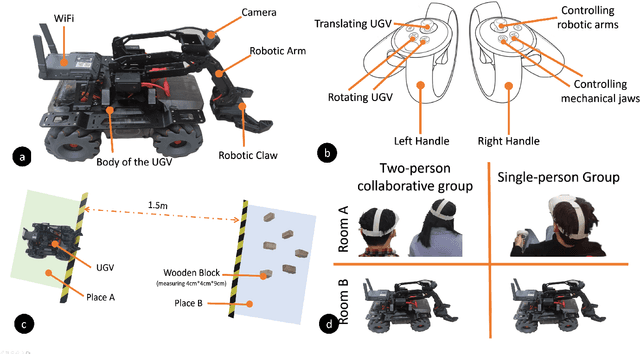
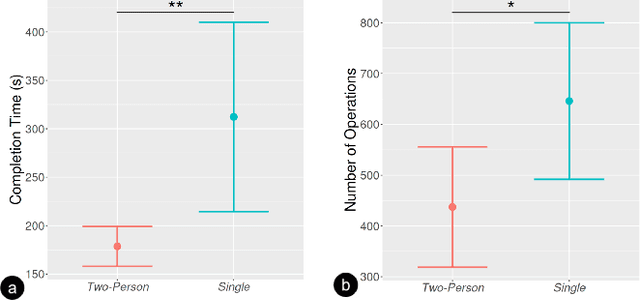
Virtual reality (VR) technology is commonly used in entertainment applications; however, it has also been deployed in practical applications in more serious aspects of our lives, such as safety. To support people working in dangerous industries, VR can ensure operators manipulate standardized tasks and work collaboratively to deal with potential risks. Surprisingly, little research has focused on how people can collaboratively work in VR environments. Few studies have paid attention to the cognitive load of operators in their collaborative tasks. Once task demands become complex, many researchers focus on optimizing the design of the interaction interfaces to reduce the cognitive load on the operator. That approach could be of merit; however, it can actually subject operators to a more significant cognitive load and potentially more errors and a failure of collaboration. In this paper, we propose a new collaborative VR system to support two teleoperators working in the VR environment to remote control an uncrewed ground vehicle. We use a compared experiment to evaluate the collaborative VR systems, focusing on the time spent on tasks and the total number of operations. Our results show that the total number of processes and the cognitive load during operations were significantly lower in the two-person group than in the single-person group. Our study sheds light on designing VR systems to support collaborative work with respect to the flow of work of teleoperators instead of simply optimizing the design outcomes.