 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplementary Text-Guided Attention for Zero-Shot Adversarial Robustness
Mar 19, 2026Due to the impressive zero-shot capabilities, pre-trained vision-language models (e.g., CLIP), have attracted widespread attention and adoption across various domains. Nonetheless, CLIP has been observed to be susceptible to adversarial examples. Through experimental analysis, we have observed a phenomenon wherein adversarial perturbations induce shifts in text-guided attention. Building upon this observation, we propose a simple yet effective strategy: Text-Guided Attention for Zero-Shot Robustness (TGA-ZSR). This framework incorporates two components: Local Attention Refinement Module and Global Attention Constraint Module. Our goal is to maintain the generalization of the CLIP model and enhance its adversarial robustness. Additionally, the Global Attention Constraint Module acquires text-guided attention from both the target and original models using clean examples. Its objective is to maintain model performance on clean samples while enhancing overall robustness. However, we observe that the method occasionally focuses on irrelevant or spurious features, which can lead to suboptimal performance and undermine its robustness in certain scenarios. To overcome this limitation, we further propose a novel approach called Complementary Text-Guided Attention (Comp-TGA). This method integrates two types of foreground attention: attention guided by the class prompt and reversed attention driven by the non-class prompt. These complementary attention mechanisms allow the model to capture a more comprehensive and accurate representation of the foreground. The experiments validate that TGA-ZSR and Comp-TGA yield 9.58% and 11.95% improvements respectively, in zero-shot robust accuracy over the current state-of-the-art techniques across 16 datasets.
Near-Field Wideband Localization using TTD-Based Terahertz Extremely Large-Scale Arrays
Mar 17, 2026The synergy between extremely large-scale antenna arrays and terahertz technology in sixth-generation networks establishes a near-field wideband transmission environment, enabling the generation of highly focused beams. To leverage this capability for multi-source localization, we propose a direct localization method based on the curvature-of-arrival of spherical wavefronts for estimating the positions of multiple near-field users from wideband signals. Furthermore, to overcome the spatial-wideband effect, we introduce a hybrid analog/digital array architecture with true-timedelayers (TTDs). We derive a closed-form position error bound to characterize the fundamental estimation performance and optimize the analog coefficients of array by maximizing the trace of the Fisher information matrix to minimize this bound. Furthermore, we extend this method to a sub-optimal iterative method that jointly optimizes beam focusing and localization, without requiring prior knowledge of the source positions for array design. Simulation results show that the proposed array configuration design significantly enhances the performance of near-field wideband localization, while the presence of TTDs effectively mitigates the localization performance degradation caused by spatial-wideband effects.
Ultra-Massive MIMO with Orthogonal Chirp Division Multiplexing for Near-Field Sensing and Communication Integration
Dec 29, 2025This paper integrates the emerging ultra-massive multiple-input multiple-output (UM-MIMO) technique with orthogonal chirp division multiplexing (OCDM) waveform to tackle the challenging near-field integrated sensing and communication (ISAC) problem. Specifically, we conceive a comprehensive ISAC architecture, where an UM-MIMO base station adopts OCDM waveform for communications and a co-located sensing receiver adopts the frequency-modulated continuous wave (FMCW) detection principle to simplify the associated hardware. For sensing tasks, several OCDM subcarriers, namely, dedicated sensing subcarriers (DSSs), are each transmitted through a dedicated sensing antenna (DSA) within the transmit antenna array. By judiciously designing the DSS selection scheme and optimizing receiver parameters, the FMCW-based sensing receiver can decouple the echo signals from different DSAs with significantly reduced hardware complexity. This setup enables the estimation of ranges and velocities of near-field targets in an antenna-pairwise manner. Moreover, by leveraging the spatial diversity of UM-MIMO, we introduce the concept of virtual bistatic sensing (VIBS), which incorporates the estimates from multiple antenna pairs to achieve high-accuracy target positioning and three-dimensional velocity measurement. The VIBS paradigm is immune to hostile channel environments characterized by spatial non-stationarity and uncorrelated multipath environment. Furthermore, the channel estimation of UM-MIMO OCDM systems enhanced by the sensing results is investigated. Simulation results demonstrate that the proposed ISAC scheme enhances sensing accuracy, and also benefits communication performance.
You Never Know a Person, You Only Know Their Defenses: Detecting Levels of Psychological Defense Mechanisms in Supportive Conversations
Dec 17, 2025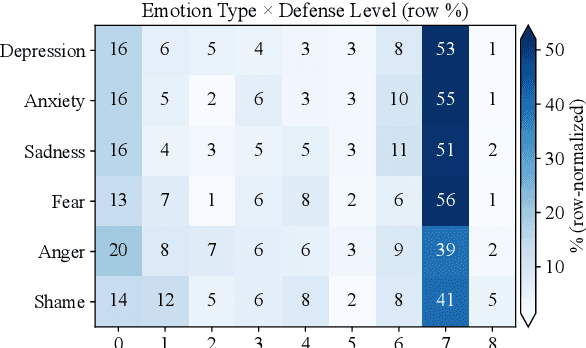
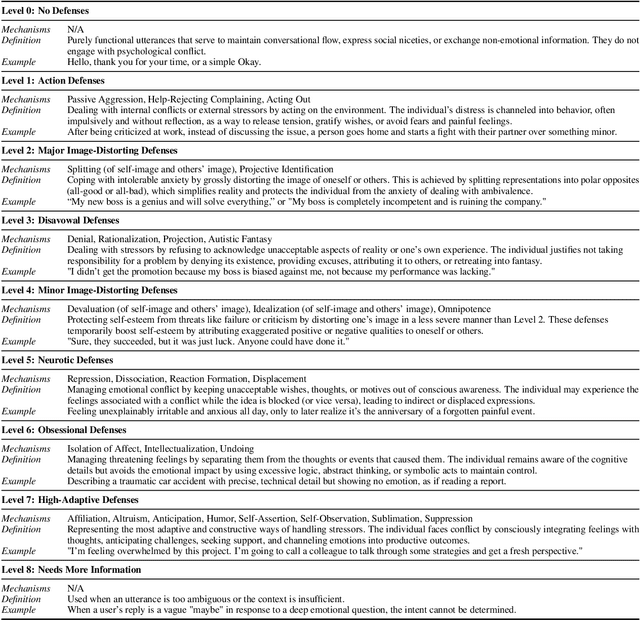
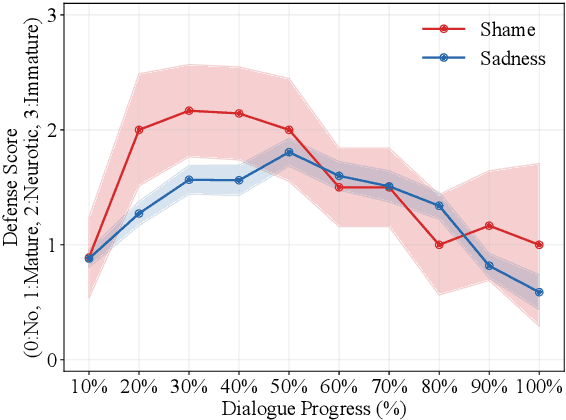
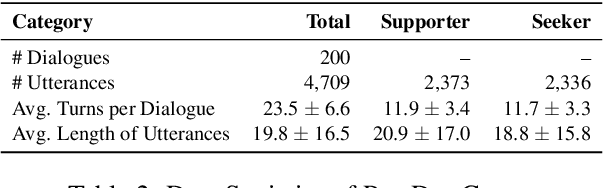
Psychological defenses are strategies, often automatic, that people use to manage distress. Rigid or overuse of defenses is negatively linked to mental health and shapes what speakers disclose and how they accept or resist help. However, defenses are complex and difficult to reliably measure, particularly in clinical dialogues. We introduce PsyDefConv, a dialogue corpus with help seeker utterances labeled for defense level, and DMRS Co-Pilot, a four-stage pipeline that provides evidence-based pre-annotations. The corpus contains 200 dialogues and 4709 utterances, including 2336 help seeker turns, with labeling and Cohen's kappa 0.639. In a counterbalanced study, the co-pilot reduced average annotation time by 22.4%. In expert review, it averaged 4.62 for evidence, 4.44 for clinical plausibility, and 4.40 for insight on a seven-point scale. Benchmarks with strong language models in zero-shot and fine-tuning settings demonstrate clear headroom, with the best macro F1-score around 30% and a tendency to overpredict mature defenses. Corpus analyses confirm that mature defenses are most common and reveal emotion-specific deviations. We will release the corpus, annotations, code, and prompts to support research on defensive functioning in language.
Benchmarking and Improving LVLMs on Event Extraction from Multimedia Documents
Sep 16, 2025The proliferation of multimedia content necessitates the development of effective Multimedia Event Extraction (M2E2) systems. Though Large Vision-Language Models (LVLMs) have shown strong cross-modal capabilities, their utility in the M2E2 task remains underexplored. In this paper, we present the first systematic evaluation of representative LVLMs, including DeepSeek-VL2 and the Qwen-VL series, on the M2E2 dataset. Our evaluations cover text-only, image-only, and cross-media subtasks, assessed under both few-shot prompting and fine-tuning settings. Our key findings highlight the following valuable insights: (1) Few-shot LVLMs perform notably better on visual tasks but struggle significantly with textual tasks; (2) Fine-tuning LVLMs with LoRA substantially enhances model performance; and (3) LVLMs exhibit strong synergy when combining modalities, achieving superior performance in cross-modal settings. We further provide a detailed error analysis to reveal persistent challenges in areas such as semantic precision, localization, and cross-modal grounding, which remain critical obstacles for advancing M2E2 capabilities.
Attribute Guidance With Inherent Pseudo-label For Occluded Person Re-identification
Aug 07, 2025Person re-identification (Re-ID) aims to match person images across different camera views, with occluded Re-ID addressing scenarios where pedestrians are partially visible. While pre-trained vision-language models have shown effectiveness in Re-ID tasks, they face significant challenges in occluded scenarios by focusing on holistic image semantics while neglecting fine-grained attribute information. This limitation becomes particularly evident when dealing with partially occluded pedestrians or when distinguishing between individuals with subtle appearance differences. To address this limitation, we propose Attribute-Guide ReID (AG-ReID), a novel framework that leverages pre-trained models' inherent capabilities to extract fine-grained semantic attributes without additional data or annotations. Our framework operates through a two-stage process: first generating attribute pseudo-labels that capture subtle visual characteristics, then introducing a dual-guidance mechanism that combines holistic and fine-grained attribute information to enhance image feature extraction. Extensive experiments demonstrate that AG-ReID achieves state-of-the-art results on multiple widely-used Re-ID datasets, showing significant improvements in handling occlusions and subtle attribute differences while maintaining competitive performance on standard Re-ID scenarios.
Hybrid RISs for Simultaneous Tunable Reflections and Sensing
Jul 22, 2025The concept of smart wireless environments envisions dynamic programmable propagation of information-bearing signals through the deployment of Reconfigurable Intelligent Surfaces (RISs). Typical RIS implementations include metasurfaces with passive unit elements capable to reflect their incident waves in controllable ways. However, this solely reflective operation induces significant challenges in the RIS orchestration from the wireless network. For example, channel estimation, which is essential for coherent RIS-empowered wireless communications, is quite challenging with the available solely reflecting RIS designs. This chapter reviews the emerging concept of Hybrid Reflecting and Sensing RISs (HRISs), which enables metasurfaces to reflect the impinging signal in a controllable manner, while simultaneously sensing a portion of it. The sensing capability of HRISs facilitates various network management functionalities, including channel parameter estimation and localization, while, most importantly, giving rise to computationally autonomous and self-configuring RISs. The implementation details of HRISs are first presented, which are then followed by a convenient mathematical model for characterizing their dual functionality. Then, two indicative applications of HRISs are discussed, one for simultaneous communications and sensing and another that showcases their usefulness for estimating the individual channels in the uplink of a multi-user HRIS-empowered communication system. For both of these applications, performance evaluation results are included validating the role of HRISs for sensing as well as integrated sensing and communications.
Lost in Pronunciation: Detecting Chinese Offensive Language Disguised by Phonetic Cloaking Replacement
Jul 10, 2025Phonetic Cloaking Replacement (PCR), defined as the deliberate use of homophonic or near-homophonic variants to hide toxic intent, has become a major obstacle to Chinese content moderation. While this problem is well-recognized, existing evaluations predominantly rely on rule-based, synthetic perturbations that ignore the creativity of real users. We organize PCR into a four-way surface-form taxonomy and compile \ours, a dataset of 500 naturally occurring, phonetically cloaked offensive posts gathered from the RedNote platform. Benchmarking state-of-the-art LLMs on this dataset exposes a serious weakness: the best model reaches only an F1-score of 0.672, and zero-shot chain-of-thought prompting pushes performance even lower. Guided by error analysis, we revisit a Pinyin-based prompting strategy that earlier studies judged ineffective and show that it recovers much of the lost accuracy. This study offers the first comprehensive taxonomy of Chinese PCR, a realistic benchmark that reveals current detectors' limits, and a lightweight mitigation technique that advances research on robust toxicity detection.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
Language-based Audio Retrieval with Co-Attention Networks
Dec 30, 2024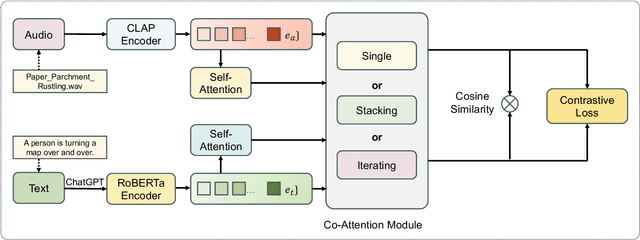
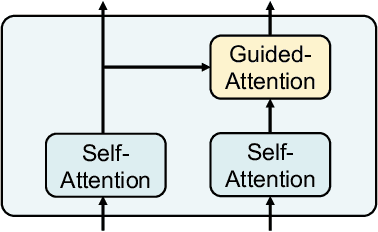
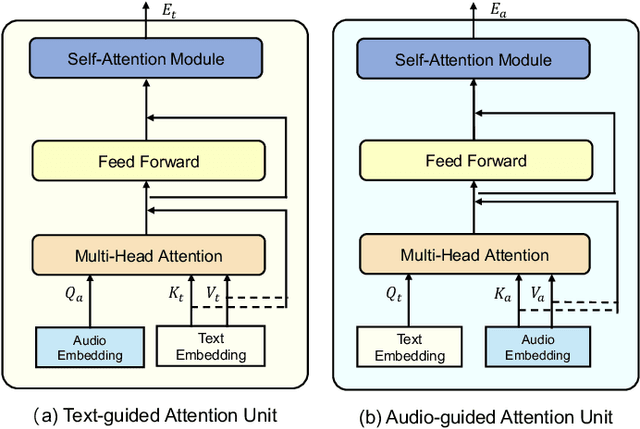
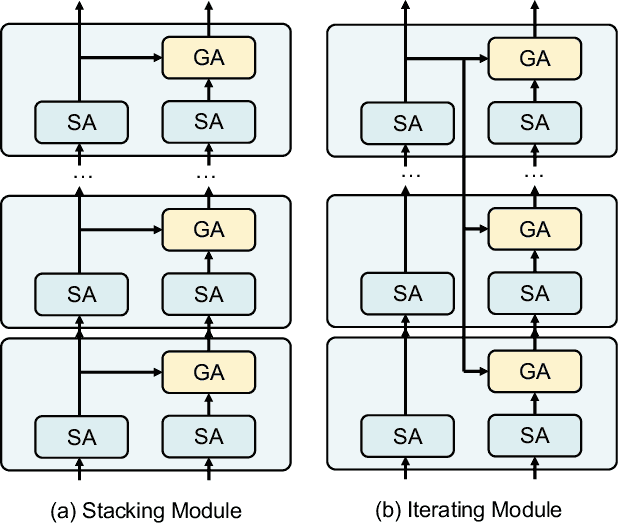
In recent years, user-generated audio content has proliferated across various media platforms, creating a growing need for efficient retrieval methods that allow users to search for audio clips using natural language queries. This task, known as language-based audio retrieval, presents significant challenges due to the complexity of learning semantic representations from heterogeneous data across both text and audio modalities. In this work, we introduce a novel framework for the language-based audio retrieval task that leverages co-attention mechanismto jointly learn meaningful representations from both modalities. To enhance the model's ability to capture fine-grained cross-modal interactions, we propose a cascaded co-attention architecture, where co-attention modules are stacked or iterated to progressively refine the semantic alignment between text and audio. Experiments conducted on two public datasets show that the proposed method can achieve better performance than the state-of-the-art method. Specifically, our best performed co-attention model achieves a 16.6% improvement in mean Average Precision on Clotho dataset, and a 15.1% improvement on AudioCaps.