 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Structured Sparse Bayesian Learning for Near-Field Non-Stationary Channel Estimation in XL-MIMO Systems
Apr 13, 2026Extremely large-scale multiple-input multiple-output (XL-MIMO) is a key enabler for sixth-generation (6G) communications. However, near-field channel estimation is particularly challenging due to spherical-wave propagation and spatial non-stationarity. To tackle this challenge, we propose a structured sparse Bayesian learning framework with adaptive dictionary updating for near-field non-stationary channel estimation. Specifically, the proposed method iteratively updates the distance parameters within an adaptive dictionary, thereby enhancing the representation capability without increasing the dictionary size. Moreover, we develop a hierarchical prior model that jointly captures polar-domain sparsity and structured dependency, enabling efficient Bayesian inference. Simulation results demonstrate that the proposed approach outperforms existing polar-domain dictionary-based methods while achieving low dictionary overhead.
JSSAnet: Theory-Guided Subchannel Partitioning and Joint Spatial Attention for Near-Field Channel Estimation
Mar 25, 2026The deployment of extremely large-scale antenna array (ELAA) in sixth-generation (6G) communication systems introduces unique challenges for efficient near-field channel estimation. To tackle these issues, this paper presents a theory-guided approach that incorporates angular information into an attention-based estimation framework. A piecewise Fourier representation is proposed to implicitly encode the near-field channel's inherent nonlinearity, enabling the entire channel to be segmented into multiple subchannels, each mapped to the angular domain via the discrete Fourier transform (DFT). Then, we develop a joint subchannel-spatial-attention network (JSSAnet) to extract the spatial features of both intra- and inter-subchannels. To guide theoretically the design of the joint attention mechanism, we derive upper and lower bounds based on approximation criteria and DFT quantization loss mitigation, respectively. Following by both bounds, a JSSA layer of an attention block is constructed to assign independent and adaptive spatial attention weights to each subchannel in parallel. Subsequently, a feed-forward network (FFN) of an attention block further captures and refines the residual nonlinear dependencies across subchannels. Moreover, the proposed JSSA map is linearly computed via element-wise product combining large-kernel convolutions (DLKC), maintaining strong contextual learning capability. Numerical results verify the effectiveness of embedding sparsity information into the attention network and demonstrate JSSAnet achieves superior estimation performance compared with existing methods.
U-Net-Based Generative Joint Source-Channel Coding for Wireless Image Transmission
Feb 26, 2026Deep learning (DL)-based joint source-channel coding (JSCC) methods have achieved remarkable success in wireless image transmission. However, these methods either focus on conventional distortion metrics that do not necessarily yield high perceptual quality or incur high computational complexity. In this paper, we propose two DL-based JSCC (DeepJSCC) methods that leverage deep generative architectures for wireless image transmission. Specifically, we propose G-UNet-JSCC, a scheme comprising an encoder and a U-Net-based generator serving as the decoder. Its skip connections enable multi-scale feature fusion to improve both pixel-level fidelity and perceptual quality of reconstructed images by integrating low- and high-level features. To further enhance pixel-level fidelity, the encoder and the U-Net-based decoder are jointly optimized using a weighted sum of structural similarity and mean-squared error (MSE) losses. Building upon G-UNet-JSCC, we further develop a DeepJSCC method called cGAN-JSCC, where the decoder is enhanced through adversarial training. In this scheme, we retain the encoder of G-UNet-JSCC and adversarially train the decoder's generator against a patch-based discriminator. cGAN-JSCC employs a two-stage training procedure. The outer stage trains the encoder and the decoder end-to-end using an MSE loss, while the inner stage adversarially trains the decoder's generator and the discriminator by minimizing a joint loss combining adversarial and distortion losses. Simulation results demonstrate that the proposed methods achieve superior pixel-level fidelity and perceptual quality on both high- and low-resolution images. For low-resolution images, cGAN-JSCC achieves better reconstruction performance and greater robustness to channel variations than G-UNet-JSCC.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
A Multi-Scale Spatial Attention Network for Near-field MIMO Channel Estimation
Jul 30, 2025



The deployment of extremely large-scale array (ELAA) brings higher spectral efficiency and spatial degree of freedom, but triggers issues on near-field channel estimation. Existing near-field channel estimation schemes primarily exploit sparsity in the transform domain. However, these schemes are sensitive to the transform matrix selection and the stopping criteria. Inspired by the success of deep learning (DL) in far-field channel estimation, this paper proposes a novel spatial-attention-based method for reconstructing extremely large-scale MIMO (XL-MIMO) channel. Initially, the spatial antenna correlations of near-field channels are analyzed as an expectation over the angle-distance space, which demonstrate correlation range of an antenna element varies with its position. Due to the strong correlation between adjacent antenna elements, interactions of inter-subchannel are applied to describe inherent correlation of near-field channels instead of inter-element. Subsequently, a multi-scale spatial attention network (MsSAN) with the inter-subchannel correlation learning capabilities is proposed tailed to near-field MIMO channel estimation. We employ the multi-scale architecture to refine the subchannel size in MsSAN. Specially, we inventively introduce the sum of dot products as spatial attention (SA) instead of cross-covariance to weight subchannel features at different scales in the SA module. Simulation results are presented to validate the proposed MsSAN achieves remarkable the inter-subchannel correlation learning capabilities and outperforms others in terms of near-field channel reconstruction.
Illumination Design for Joint Imaging and Wireless Power Transfer Systems
Aug 01, 2024



This paper presents a novel concept termed Integrated Imaging and Wireless Power Transfer (IWPT), wherein the integration of imaging and wireless power transfer functionalities is achieved on a unified hardware platform. IWPT leverages a transmitting array to efficiently illuminate a specific Region of Interest (ROI), enabling the extraction of ROI's scattering coefficients while concurrently providing wireless power to nearby users. The integration of IWPT offers compelling advantages, including notable reductions in power consumption and spectrum utilization, pivotal for the optimization of future 6G wireless networks. As an initial investigation, we explore two antenna architectures: a fully digital array and a digital/analog hybrid array. Our goal is to characterize the fundamental trade-off between imaging and wireless power transfer by optimizing the illumination signal. With imaging operating in the near-field, we formulate the illumination signal design as an optimization problem that minimizes the condition number of the equivalent channel. To address this optimization problem, we propose an semi-definite relaxation-based approach for the fully digital array and an alternating optimization algorithm for the hybrid array. Finally, numerical results verify the effectiveness of our proposed solutions and demonstrate the trade-off between imaging and wireless power transfer.
Intelligent Reflecting Surface Aided Target Localization With Unknown Transceiver-IRS Channel State Information
Apr 08, 2024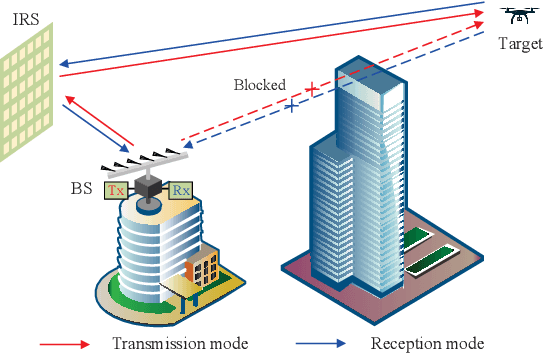
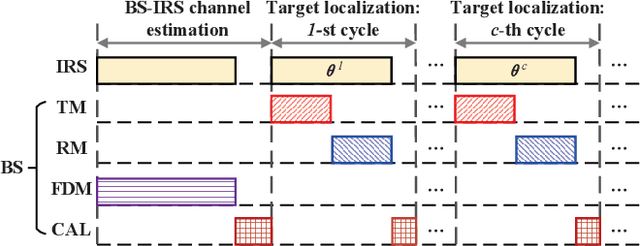
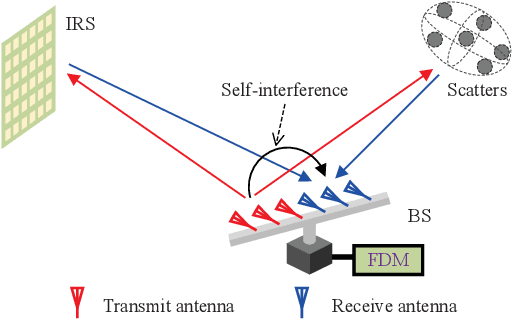
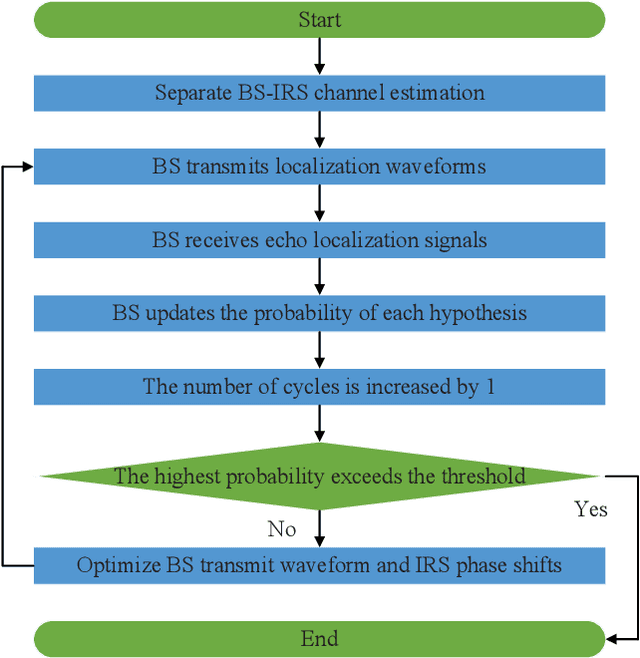
Integrating wireless sensing capabilities into base stations (BSs) has become a widespread trend in the future beyond fifth-generation (B5G)/sixth-generation (6G) wireless networks. In this paper, we investigate intelligent reflecting surface (IRS) enabled wireless localization, in which an IRS is deployed to assist a BS in locating a target in its non-line-of-sight (NLoS) region. In particular, we consider the case where the BS-IRS channel state information (CSI) is unknown. Specifically, we first propose a separate BS-IRS channel estimation scheme in which the BS operates in full-duplex mode (FDM), i.e., a portion of the BS antennas send downlink pilot signals to the IRS, while the remaining BS antennas receive the uplink pilot signals reflected by the IRS. However, we can only obtain an incomplete BS-IRS channel matrix based on our developed iterative coordinate descent-based channel estimation algorithm due to the "sign ambiguity issue". Then, we employ the multiple hypotheses testing framework to perform target localization based on the incomplete estimated channel, in which the probability of each hypothesis is updated using Bayesian inference at each cycle. Moreover, we formulate a joint BS transmit waveform and IRS phase shifts optimization problem to improve the target localization performance by maximizing the weighted sum distance between each two hypotheses. However, the objective function is essentially a quartic function of the IRS phase shift vector, thus motivating us to resort to the penalty-based method to tackle this challenge. Simulation results validate the effectiveness of our proposed target localization scheme and show that the scheme's performance can be further improved by finely designing the BS transmit waveform and IRS phase shifts intending to maximize the weighted sum distance between different hypotheses.
Variational Bayesian Learning based Joint Localization and Channel Estimation with Distance-dependent Noise
Mar 07, 2024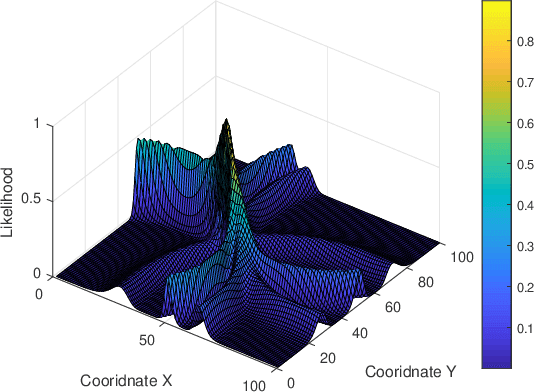
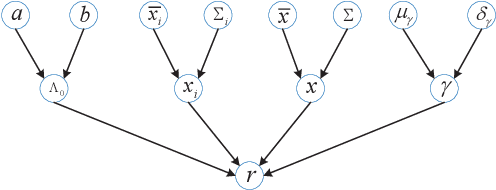
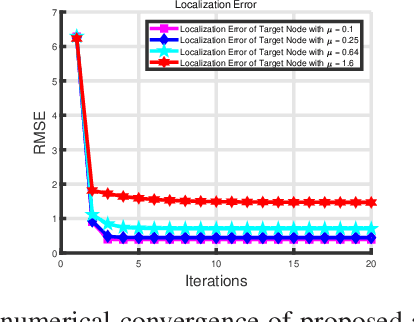
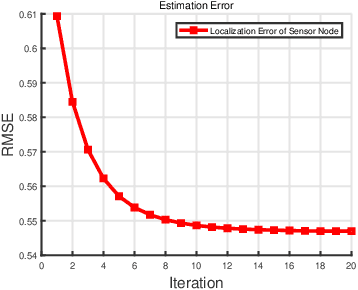
In the Industrial Internet of Things (IIoTs) and Ocean of Things (OoTs), the advent of massive intelligent services has imposed stringent requirements on both communication and localization, particularly emphasizing precise localization and channel information. This paper focuses on the challenge of jointly optimizing localization and communication in IoT networks. Departing from the conventional independent noise model used in localization and channel estimation problems, we consider a more realistic model incorporating distance-dependent noise variance, as revealed in recent theoretical analyses and experimental results. The distance-dependent noise introduces unknown noise power and a complex noise model, resulting in an exceptionally challenging non-convex and nonlinear optimization problem. In this study, we address a joint localization and channel estimation problem encompassing distance-dependent noise, unknown channel parameters, and uncertainties in sensor node locations. To surmount the intractable nonlinear and non-convex objective function inherent in the problem, we introduce a variational Bayesian learning-based framework. This framework enables the joint optimization of localization and channel parameters by leveraging an effective approximation to the true posterior distribution. Furthermore, the proposed joint learning algorithm provides an iterative closed-form solution and exhibits superior performance in terms of computational complexity compared to existing algorithms. Computer simulation results demonstrate that the proposed algorithm approaches the performance of the Bayesian Cramer-Rao bound (BCRB), achieves localization performance comparable to the ML-GMP algorithm, and outperforms the other two comparison algorithms.
GAN Based Near-Field Channel Estimation for Extremely Large-Scale MIMO Systems
Feb 27, 2024Extremely large-scale multiple-input-multiple-output (XL-MIMO) is a promising technique to achieve ultra-high spectral efficiency for future 6G communications. The mixed line-of-sight (LoS) and non-line-of-sight (NLoS) XL-MIMO near-field channel model is adopted to describe the XL-MIMO near-field channel accurately. In this paper, a generative adversarial network (GAN) variant based channel estimation method is proposed for XL-MIMO systems. Specifically, the GAN variant is developed to simultaneously estimate the LoS and NLoS path components of the XL-MIMO channel. The initially estimated channels instead of the received signals are input into the GAN variant as the conditional input to generate the XL-MIMO channels more efficiently. The GAN variant not only learns the mapping from the initially estimated channels to the XL-MIMO channels but also learns an adversarial loss. Moreover, we combine the adversarial loss with a conventional loss function to ensure the correct direction of training the generator. To further enhance the estimation performance, we investigate the impact of the hyper-parameter of the loss function on the performance of our method. Simulation results show that the proposed method outperforms the existing channel estimation approaches in the adopted channel model. In addition, the proposed method surpasses the Cram$\acute{\mathbf{e}}$r-Rao lower bound (CRLB) under low pilot overhead.
Fast Direct Localization for Millimeter Wave MIMO Systems via Deep ADMM Unfolding
Feb 06, 2023


Massive arrays deployed in millimeter-wave systems enable high angular resolution performance, which in turn facilitates sub-meter localization services. Albeit suboptimal, up to now the most popular localization approach has been based on a so-called two-step procedure, where triangulation is applied upon aggregation of the angle-of-arrival (AoA) measurements from the collaborative base stations. This is mainly due to the prohibitive computational cost of the existing direct localization approaches in large-scale systems. To address this issue, we propose a deep unfolding based fast direct localization solver. First, the direct localization is formulated as a joint $l_1$-$l_{2,1}$ norm sparse recovery problem, which is then solved by using alternating direction method of multipliers (ADMM). Next, we develop a deep ADMM unfolding network (DAUN) to learn the ADMM parameter settings from the training data and a position refinement algorithm is proposed for DAUN. Finally, simulation results showcase the superiority of the proposed DAUN over the baseline solvers in terms of better localization accuracy, faster convergence and significantly lower computational complexity.