 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAC: Maximum Entropy RL via Kinetic Energy Regularized Bridge Matching
Feb 13, 2026Iterative generative policies, such as diffusion models and flow matching, offer superior expressivity for continuous control but complicate Maximum Entropy Reinforcement Learning because their action log-densities are not directly accessible. To address this, we propose Field Least-Energy Actor-Critic (FLAC), a likelihood-free framework that regulates policy stochasticity by penalizing the kinetic energy of the velocity field. Our key insight is to formulate policy optimization as a Generalized Schrödinger Bridge (GSB) problem relative to a high-entropy reference process (e.g., uniform). Under this view, the maximum-entropy principle emerges naturally as staying close to a high-entropy reference while optimizing return, without requiring explicit action densities. In this framework, kinetic energy serves as a physically grounded proxy for divergence from the reference: minimizing path-space energy bounds the deviation of the induced terminal action distribution. Building on this view, we derive an energy-regularized policy iteration scheme and a practical off-policy algorithm that automatically tunes the kinetic energy via a Lagrangian dual mechanism. Empirically, FLAC achieves superior or comparable performance on high-dimensional benchmarks relative to strong baselines, while avoiding explicit density estimation.
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Whole-Body Control With Terrain Estimation of A 6-DoF Wheeled Bipedal Robot
Nov 09, 2025
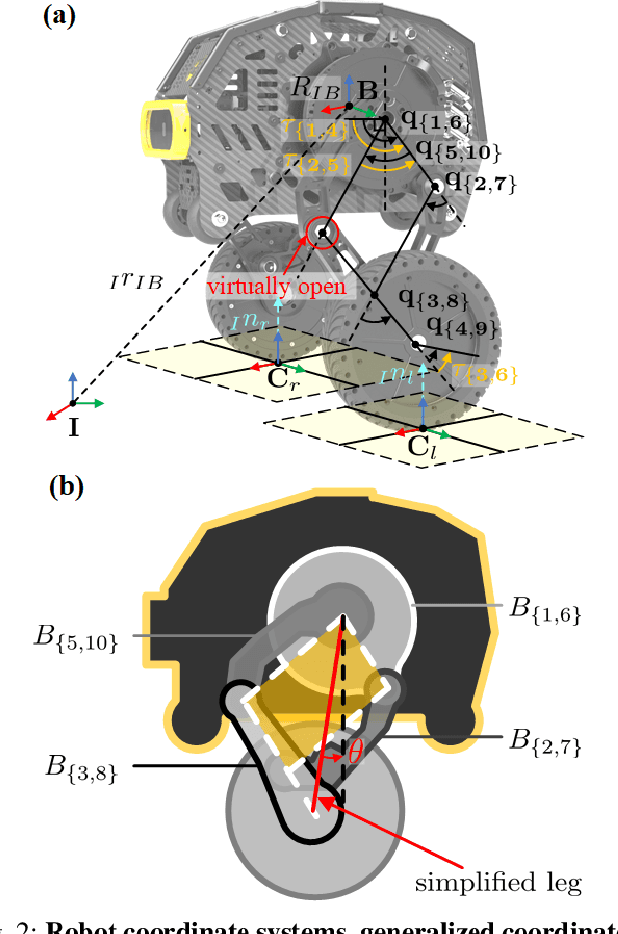
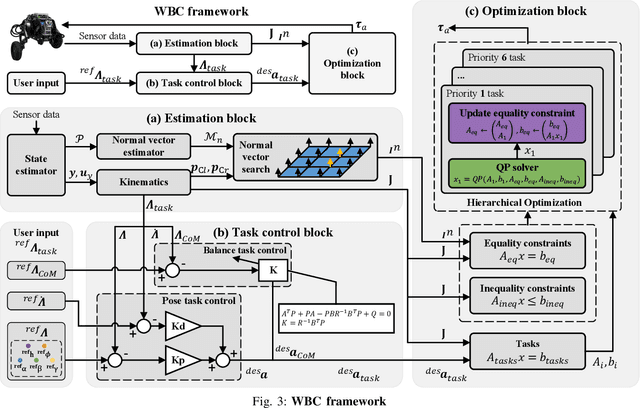
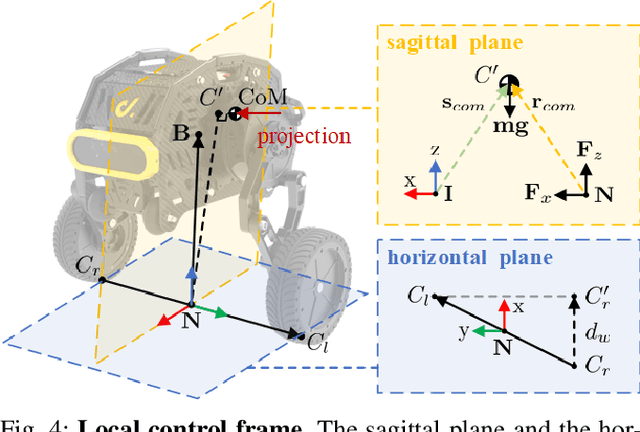
Wheeled bipedal robots have garnered increasing attention in exploration and inspection. However, most research simplifies calculations by ignoring leg dynamics, thereby restricting the robot's full motion potential. Additionally, robots face challenges when traversing uneven terrain. To address the aforementioned issue, we develop a complete dynamics model and design a whole-body control framework with terrain estimation for a novel 6 degrees of freedom wheeled bipedal robot. This model incorporates the closed-loop dynamics of the robot and a ground contact model based on the estimated ground normal vector. We use a LiDAR inertial odometry framework and improved Principal Component Analysis for terrain estimation. Task controllers, including PD control law and LQR, are employed for pose control and centroidal dynamics-based balance control, respectively. Furthermore, a hierarchical optimization approach is used to solve the whole-body control problem. We validate the performance of the terrain estimation algorithm and demonstrate the algorithm's robustness and ability to traverse uneven terrain through both simulation and real-world experiments.
Flow-Based Policy for Online Reinforcement Learning
Jun 15, 2025



We present \textbf{FlowRL}, a novel framework for online reinforcement learning that integrates flow-based policy representation with Wasserstein-2-regularized optimization. We argue that in addition to training signals, enhancing the expressiveness of the policy class is crucial for the performance gains in RL. Flow-based generative models offer such potential, excelling at capturing complex, multimodal action distributions. However, their direct application in online RL is challenging due to a fundamental objective mismatch: standard flow training optimizes for static data imitation, while RL requires value-based policy optimization through a dynamic buffer, leading to difficult optimization landscapes. FlowRL first models policies via a state-dependent velocity field, generating actions through deterministic ODE integration from noise. We derive a constrained policy search objective that jointly maximizes Q through the flow policy while bounding the Wasserstein-2 distance to a behavior-optimal policy implicitly derived from the replay buffer. This formulation effectively aligns the flow optimization with the RL objective, enabling efficient and value-aware policy learning despite the complexity of the policy class. Empirical evaluations on DMControl and Humanoidbench demonstrate that FlowRL achieves competitive performance in online reinforcement learning benchmarks.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
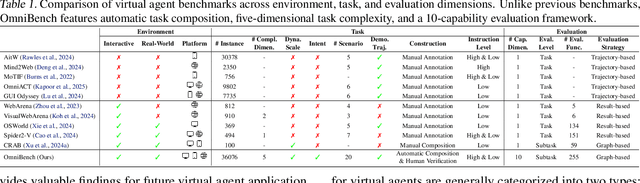

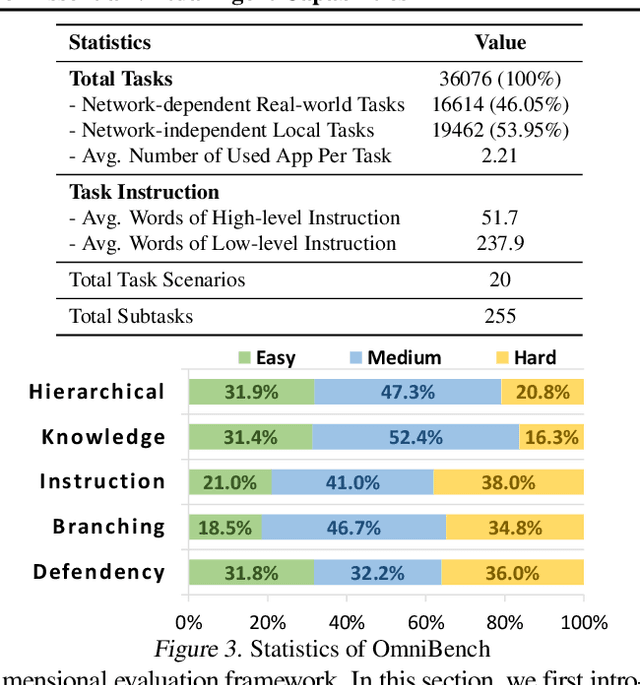
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Jun 05, 2025Recent studies extend the autoregression paradigm to text-to-image generation, achieving performance comparable to diffusion models. However, our new PairComp benchmark -- featuring test cases of paired prompts with similar syntax but different fine-grained semantics -- reveals that existing models struggle with fine-grained text-image alignment thus failing to realize precise control over visual tokens. To address this, we propose FocusDiff, which enhances fine-grained text-image semantic alignment by focusing on subtle differences between similar text-image pairs. We construct a new dataset of paired texts and images with similar overall expressions but distinct local semantics, further introducing a novel reinforcement learning algorithm to emphasize such fine-grained semantic differences for desired image generation. Our approach achieves state-of-the-art performance on existing text-to-image benchmarks and significantly outperforms prior methods on PairComp.
Toward Real-World Cooperative and Competitive Soccer with Quadrupedal Robot Teams
May 20, 2025Achieving coordinated teamwork among legged robots requires both fine-grained locomotion control and long-horizon strategic decision-making. Robot soccer offers a compelling testbed for this challenge, combining dynamic, competitive, and multi-agent interactions. In this work, we present a hierarchical multi-agent reinforcement learning (MARL) framework that enables fully autonomous and decentralized quadruped robot soccer. First, a set of highly dynamic low-level skills is trained for legged locomotion and ball manipulation, such as walking, dribbling, and kicking. On top of these, a high-level strategic planning policy is trained with Multi-Agent Proximal Policy Optimization (MAPPO) via Fictitious Self-Play (FSP). This learning framework allows agents to adapt to diverse opponent strategies and gives rise to sophisticated team behaviors, including coordinated passing, interception, and dynamic role allocation. With an extensive ablation study, the proposed learning method shows significant advantages in the cooperative and competitive multi-agent soccer game. We deploy the learned policies to real quadruped robots relying solely on onboard proprioception and decentralized localization, with the resulting system supporting autonomous robot-robot and robot-human soccer matches on indoor and outdoor soccer courts.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
Mastering Collaborative Multi-modal Data Selection: A Focus on Informativeness, Uniqueness, and Representativeness
Dec 09, 2024



Instruction tuning fine-tunes pre-trained Multi-modal Large Language Models (MLLMs) to handle real-world tasks. However, the rapid expansion of visual instruction datasets introduces data redundancy, leading to excessive computational costs. We propose a collaborative framework, DataTailor, which leverages three key principles--informativeness, uniqueness, and representativeness--for effective data selection. We argue that a valuable sample should be informative of the task, non-redundant, and represent the sample distribution (i.e., not an outlier). We further propose practical ways to score against each principle, which automatically adapts to a given dataset without tedious hyperparameter tuning. Comprehensive experiments on various benchmarks demonstrate that DataTailor achieves 100.8% of the performance of full-data fine-tuning with only 15% of the data, significantly reducing computational costs while maintaining superior results. This exemplifies the "Less is More" philosophy in MLLM development.
SleepNetZero: Zero-Burden Zero-Shot Reliable Sleep Staging With Neural Networks Based on Ballistocardiograms
Oct 30, 2024Sleep monitoring plays a crucial role in maintaining good health, with sleep staging serving as an essential metric in the monitoring process. Traditional methods, utilizing medical sensors like EEG and ECG, can be effective but often present challenges such as unnatural user experience, complex deployment, and high costs. Ballistocardiography~(BCG), a type of piezoelectric sensor signal, offers a non-invasive, user-friendly, and easily deployable alternative for long-term home monitoring. However, reliable BCG-based sleep staging is challenging due to the limited sleep monitoring data available for BCG. A restricted training dataset prevents the model from generalization across populations. Additionally, transferring to BCG faces difficulty ensuring model robustness when migrating from other data sources. To address these issues, we introduce SleepNetZero, a zero-shot learning based approach for sleep staging. To tackle the generalization challenge, we propose a series of BCG feature extraction methods that align BCG components with corresponding respiratory, cardiac, and movement channels in PSG. This allows models to be trained on large-scale PSG datasets that are diverse in population. For the migration challenge, we employ data augmentation techniques, significantly enhancing generalizability. We conducted extensive training and testing on large datasets~(12393 records from 9637 different subjects), achieving an accuracy of 0.803 and a Cohen's Kappa of 0.718. ZeroSleepNet was also deployed in real prototype~(monitoring pads) and tested in actual hospital settings~(265 users), demonstrating an accuracy of 0.697 and a Cohen's Kappa of 0.589. To the best of our knowledge, this work represents the first known reliable BCG-based sleep staging effort and marks a significant step towards in-home health monitoring.