 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
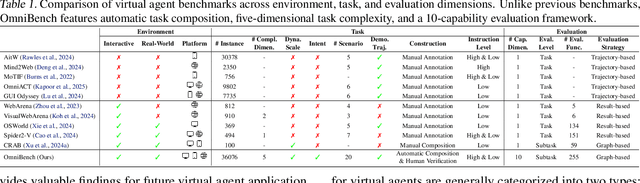

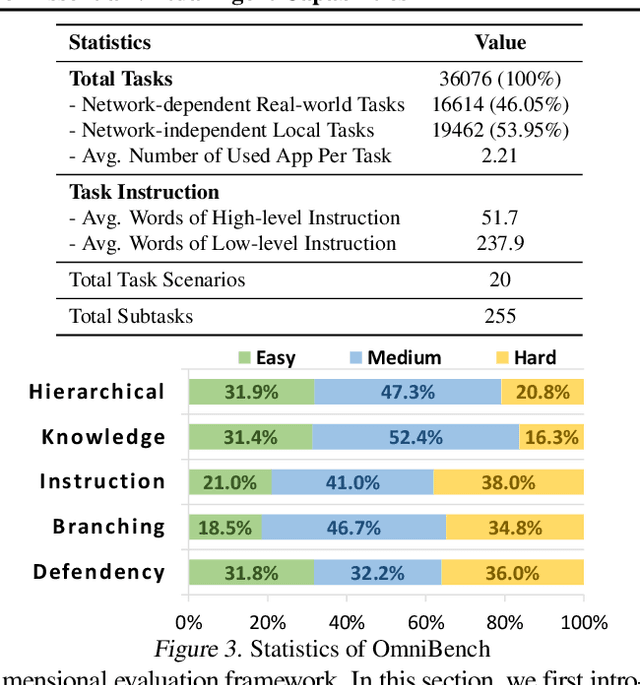
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
Benchmarking Multimodal CoT Reward Model Stepwise by Visual Program
Apr 09, 2025



Recent advancements in reward signal usage for Large Language Models (LLMs) are remarkable. However, significant challenges exist when transitioning reward signal to the multimodal domain, including labor-intensive annotations, over-reliance on one-step rewards, and inadequate evaluation. To address these issues, we propose SVIP, a novel approach to train a step-level multi-dimensional Chain-of-Thought~(CoT) reward model automatically. It generates code for solving visual tasks and transforms the analysis of code blocks into the evaluation of CoT step as training samples. Then, we train SVIP-Reward model using a multi-head attention mechanism called TriAtt-CoT. The advantages of SVIP-Reward are evident throughout the entire process of MLLM. We also introduce a benchmark for CoT reward model training and testing. Experimental results demonstrate that SVIP-Reward improves MLLM performance across training and inference-time scaling, yielding better results on benchmarks while reducing hallucinations and enhancing reasoning ability.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
Iris: Breaking GUI Complexity with Adaptive Focus and Self-Refining
Dec 13, 2024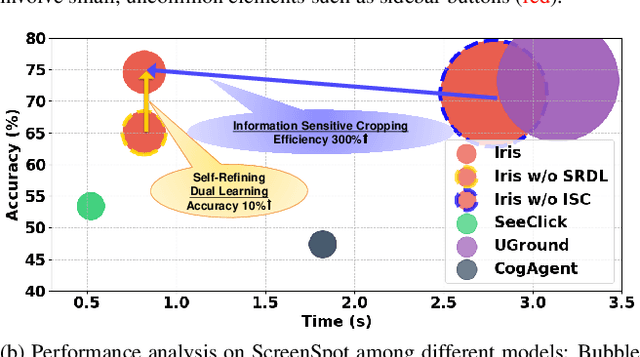
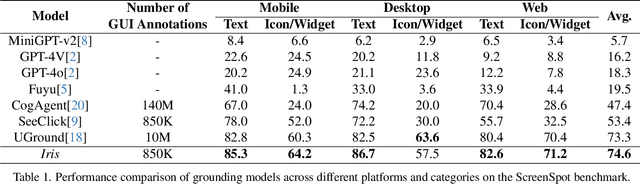
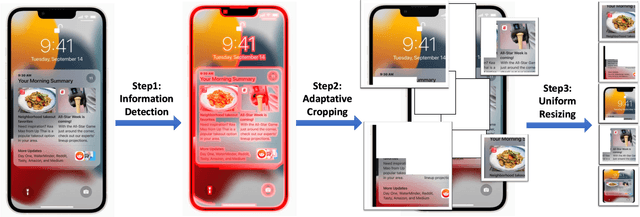
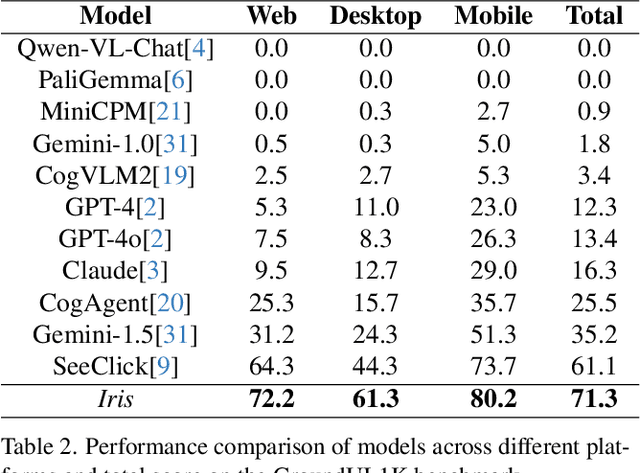
Digital agents are increasingly employed to automate tasks in interactive digital environments such as web pages, software applications, and operating systems. While text-based agents built on Large Language Models (LLMs) often require frequent updates due to platform-specific APIs, visual agents leveraging Multimodal Large Language Models (MLLMs) offer enhanced adaptability by interacting directly with Graphical User Interfaces (GUIs). However, these agents face significant challenges in visual perception, particularly when handling high-resolution, visually complex digital environments. This paper introduces Iris, a foundational visual agent that addresses these challenges through two key innovations: Information-Sensitive Cropping (ISC) and Self-Refining Dual Learning (SRDL). ISC dynamically identifies and prioritizes visually dense regions using a edge detection algorithm, enabling efficient processing by allocating more computational resources to areas with higher information density. SRDL enhances the agent's ability to handle complex tasks by leveraging a dual-learning loop, where improvements in referring (describing UI elements) reinforce grounding (locating elements) and vice versa, all without requiring additional annotated data. Empirical evaluations demonstrate that Iris achieves state-of-the-art performance across multiple benchmarks with only 850K GUI annotations, outperforming methods using 10x more training data. These improvements further translate to significant gains in both web and OS agent downstream tasks.
STEP: Enhancing Video-LLMs' Compositional Reasoning by Spatio-Temporal Graph-guided Self-Training
Nov 29, 2024Video Large Language Models (Video-LLMs) have recently shown strong performance in basic video understanding tasks, such as captioning and coarse-grained question answering, but struggle with compositional reasoning that requires multi-step spatio-temporal inference across object relations, interactions, and events. The hurdles to enhancing this capability include extensive manual labor, the lack of spatio-temporal compositionality in existing data and the absence of explicit reasoning supervision. In this paper, we propose STEP, a novel graph-guided self-training method that enables Video-LLMs to generate reasoning-rich fine-tuning data from any raw videos to improve itself. Specifically, we first induce Spatio-Temporal Scene Graph (STSG) representation of diverse videos to capture fine-grained, multi-granular video semantics. Then, the STSGs guide the derivation of multi-step reasoning Question-Answer (QA) data with Chain-of-Thought (CoT) rationales. Both answers and rationales are integrated as training objective, aiming to enhance model's reasoning abilities by supervision over explicit reasoning steps. Experimental results demonstrate the effectiveness of STEP across models of varying scales, with a significant 21.3\% improvement in tasks requiring three or more reasoning steps. Furthermore, it achieves superior performance with a minimal amount of self-generated rationale-enriched training samples in both compositional reasoning and comprehensive understanding benchmarks, highlighting the broad applicability and vast potential.
Fact :Teaching MLLMs with Faithful, Concise and Transferable Rationales
Apr 17, 2024



The remarkable performance of Multimodal Large Language Models (MLLMs) has unequivocally demonstrated their proficient understanding capabilities in handling a wide array of visual tasks. Nevertheless, the opaque nature of their black-box reasoning processes persists as an enigma, rendering them uninterpretable and struggling with hallucination. Their ability to execute intricate compositional reasoning tasks is also constrained, culminating in a stagnation of learning progression for these models. In this work, we introduce Fact, a novel paradigm designed to generate multimodal rationales that are faithful, concise, and transferable for teaching MLLMs. This paradigm utilizes verifiable visual programming to generate executable code guaranteeing faithfulness and precision. Subsequently, through a series of operations including pruning, merging, and bridging, the rationale enhances its conciseness. Furthermore, we filter rationales that can be transferred to end-to-end paradigms from programming paradigms to guarantee transferability. Empirical evidence from experiments demonstrates the superiority of our method across models of varying parameter sizes, significantly enhancing their compositional reasoning and generalization ability. Our approach also reduces hallucinations owing to its high correlation between images and text.
De-fine: Decomposing and Refining Visual Programs with Auto-Feedback
Nov 25, 2023



Visual programming, a modular and generalizable paradigm, integrates different modules and Python operators to solve various vision-language tasks. Unlike end-to-end models that need task-specific data, it advances in performing visual processing and reasoning in an unsupervised manner. Current visual programming methods generate programs in a single pass for each task where the ability to evaluate and optimize based on feedback, unfortunately, is lacking, which consequentially limits their effectiveness for complex, multi-step problems. Drawing inspiration from benders decomposition, we introduce De-fine, a general framework that automatically decomposes complex tasks into simpler subtasks and refines programs through auto-feedback. This model-agnostic approach can improve logical reasoning performance by integrating the strengths of multiple models. Our experiments across various visual tasks show that De-fine creates more accurate and robust programs, setting new benchmarks in the field.
Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
Aug 10, 2023



Multimodal Large Language Models (MLLMs) have recently sparked significant interest, which demonstrates emergent capabilities to serve as a general-purpose model for various vision-language tasks. However, existing methods mainly focus on limited types of instructions with a single image as visual context, which hinders the widespread availability of MLLMs. In this paper, we introduce the I4 benchmark to comprehensively evaluate the instruction following ability on complicated interleaved vision-language instructions, which involve intricate image-text sequential context, covering a diverse range of scenarios (e.g., visually-rich webpages/textbooks, lecture slides, embodied dialogue). Systematic evaluation on our I4 benchmark reveals a common defect of existing methods: the Visual Prompt Generator (VPG) trained on image-captioning alignment objective tends to attend to common foreground information for captioning but struggles to extract specific information required by particular tasks. To address this issue, we propose a generic and lightweight controllable knowledge re-injection module, which utilizes the sophisticated reasoning ability of LLMs to control the VPG to conditionally extract instruction-specific visual information and re-inject it into the LLM. Further, we introduce an annotation-free cross-attention guided counterfactual image training strategy to methodically learn the proposed module by collaborating a cascade of foundation models. Enhanced by the proposed module and training strategy, we present Cheetor, a Transformer-based MLLM that can effectively handle a wide variety of interleaved vision-language instructions and achieves state-of-the-art zero-shot performance across all tasks of I4, without high-quality multimodal instruction tuning data. Cheetor also exhibits competitive performance compared with state-of-the-art instruction tuned models on MME benchmark.
Gradient-Regulated Meta-Prompt Learning for Generalizable Vision-Language Models
Mar 12, 2023



Prompt tuning, a recently emerging paradigm, enables the powerful vision-language pre-training models to adapt to downstream tasks in a parameter -- and data -- efficient way, by learning the ``soft prompts'' to condition frozen pre-training models. Though effective, it is particularly problematic in the few-shot scenario, where prompt tuning performance is sensitive to the initialization and requires a time-consuming process to find a good initialization, thus restricting the fast adaptation ability of the pre-training models. In addition, prompt tuning could undermine the generalizability of the pre-training models, because the learnable prompt tokens are easy to overfit to the limited training samples. To address these issues, we introduce a novel Gradient-RegulAted Meta-prompt learning (GRAM) framework that jointly meta-learns an efficient soft prompt initialization for better adaptation and a lightweight gradient regulating function for strong cross-domain generalizability in a meta-learning paradigm using only the unlabeled image-text pre-training data. Rather than designing a specific prompt tuning method, our GRAM can be easily incorporated into various prompt tuning methods in a model-agnostic way, and comprehensive experiments show that GRAM brings about consistent improvement for them in several settings (i.e., few-shot learning, cross-domain generalization, cross-dataset generalization, etc.) over 11 datasets. Further, experiments show that GRAM enables the orthogonal methods of textual and visual prompt tuning to work in a mutually-enhanced way, offering better generalizability beyond the uni-modal prompt tuning methods.