 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-c: Continual Improved Visual Instruction Tuning
Jun 10, 2025Multimodal models like LLaVA-1.5 achieve state-of-the-art visual understanding through visual instruction tuning on multitask datasets, enabling strong instruction-following and multimodal performance. However, multitask learning faces challenges such as task balancing, requiring careful adjustment of data proportions, and expansion costs, where new tasks risk catastrophic forgetting and need costly retraining. Continual learning provides a promising alternative to acquiring new knowledge incrementally while preserving existing capabilities. However, current methods prioritize task-specific performance, neglecting base model degradation from overfitting to specific instructions, which undermines general capabilities. In this work, we propose a simple but effective method with two modifications on LLaVA-1.5: spectral-aware consolidation for improved task balance and unsupervised inquiry regularization to prevent base model degradation. We evaluate both general and task-specific performance across continual pretraining and fine-tuning. Experiments demonstrate that LLaVA-c consistently enhances standard benchmark performance and preserves general capabilities. For the first time, we show that task-by-task continual learning can achieve results that match or surpass multitask joint learning. The code will be publicly released.
MagCache: Fast Video Generation with Magnitude-Aware Cache
Jun 10, 2025Existing acceleration techniques for video diffusion models often rely on uniform heuristics or time-embedding variants to skip timesteps and reuse cached features. These approaches typically require extensive calibration with curated prompts and risk inconsistent outputs due to prompt-specific overfitting. In this paper, we introduce a novel and robust discovery: a unified magnitude law observed across different models and prompts. Specifically, the magnitude ratio of successive residual outputs decreases monotonically and steadily in most timesteps while rapidly in the last several steps. Leveraging this insight, we introduce a Magnitude-aware Cache (MagCache) that adaptively skips unimportant timesteps using an error modeling mechanism and adaptive caching strategy. Unlike existing methods requiring dozens of curated samples for calibration, MagCache only requires a single sample for calibration. Experimental results show that MagCache achieves 2.1x and 2.68x speedups on Open-Sora and Wan 2.1, respectively, while preserving superior visual fidelity. It significantly outperforms existing methods in LPIPS, SSIM, and PSNR, under comparable computational budgets.
Mixpert: Mitigating Multimodal Learning Conflicts with Efficient Mixture-of-Vision-Experts
May 30, 2025Multimodal large language models (MLLMs) require a nuanced interpretation of complex image information, typically leveraging a vision encoder to perceive various visual scenarios. However, relying solely on a single vision encoder to handle diverse task domains proves difficult and inevitably leads to conflicts. Recent work enhances data perception by directly integrating multiple domain-specific vision encoders, yet this structure adds complexity and limits the potential for joint optimization. In this paper, we introduce Mixpert, an efficient mixture-of-vision-experts architecture that inherits the joint learning advantages from a single vision encoder while being restructured into a multi-expert paradigm for task-specific fine-tuning across different visual tasks. Additionally, we design a dynamic routing mechanism that allocates input images to the most suitable visual expert. Mixpert effectively alleviates domain conflicts encountered by a single vision encoder in multi-task learning with minimal additional computational cost, making it more efficient than multiple encoders. Furthermore, Mixpert integrates seamlessly into any MLLM, with experimental results demonstrating substantial performance gains across various tasks.
Efficient Multi-modal Long Context Learning for Training-free Adaptation
May 26, 2025Traditional approaches to adapting multi-modal large language models (MLLMs) to new tasks have relied heavily on fine-tuning. This paper introduces Efficient Multi-Modal Long Context Learning (EMLoC), a novel training-free alternative that embeds demonstration examples directly into the model input. EMLoC offers a more efficient, flexible, and scalable solution for task adaptation. Because extremely lengthy inputs introduce prohibitive computational and memory overhead, EMLoC contributes a chunk-wise compression mechanism combined with layer-wise adaptive pruning. It condenses long-context multimodal inputs into compact, task-specific memory representations. By adaptively pruning tokens at each layer under a Jensen-Shannon divergence constraint, our method achieves a dramatic reduction in inference complexity without sacrificing performance. This approach is the first to seamlessly integrate compression and pruning techniques for multi-modal long-context learning, offering a scalable and efficient solution for real-world applications. Extensive experiments on diverse vision-language benchmarks demonstrate that EMLoC achieves performance on par with or superior to naive long-context approaches. Our results highlight the potential of EMLoC as a groundbreaking framework for efficient and flexible adaptation of multi-modal models in resource-constrained environments. Codes are publicly available at https://github.com/Zehong-Ma/EMLoC.
ViMoE: An Empirical Study of Designing Vision Mixture-of-Experts
Oct 21, 2024



Mixture-of-Experts (MoE) models embody the divide-and-conquer concept and are a promising approach for increasing model capacity, demonstrating excellent scalability across multiple domains. In this paper, we integrate the MoE structure into the classic Vision Transformer (ViT), naming it ViMoE, and explore the potential of applying MoE to vision through a comprehensive study on image classification. However, we observe that the performance is sensitive to the configuration of MoE layers, making it challenging to obtain optimal results without careful design. The underlying cause is that inappropriate MoE layers lead to unreliable routing and hinder experts from effectively acquiring helpful knowledge. To address this, we introduce a shared expert to learn and capture common information, serving as an effective way to construct stable ViMoE. Furthermore, we demonstrate how to analyze expert routing behavior, revealing which MoE layers are capable of specializing in handling specific information and which are not. This provides guidance for retaining the critical layers while removing redundancies, thereby advancing ViMoE to be more efficient without sacrificing accuracy. We aspire for this work to offer new insights into the design of vision MoE models and provide valuable empirical guidance for future research.
OVMR: Open-Vocabulary Recognition with Multi-Modal References
Jun 07, 2024



The challenge of open-vocabulary recognition lies in the model has no clue of new categories it is applied to. Existing works have proposed different methods to embed category cues into the model, \eg, through few-shot fine-tuning, providing category names or textual descriptions to Vision-Language Models. Fine-tuning is time-consuming and degrades the generalization capability. Textual descriptions could be ambiguous and fail to depict visual details. This paper tackles open-vocabulary recognition from a different perspective by referring to multi-modal clues composed of textual descriptions and exemplar images. Our method, named OVMR, adopts two innovative components to pursue a more robust category cues embedding. A multi-modal classifier is first generated by dynamically complementing textual descriptions with image exemplars. A preference-based refinement module is hence applied to fuse uni-modal and multi-modal classifiers, with the aim to alleviate issues of low-quality exemplar images or textual descriptions. The proposed OVMR is a plug-and-play module, and works well with exemplar images randomly crawled from the Internet. Extensive experiments have demonstrated the promising performance of OVMR, \eg, it outperforms existing methods across various scenarios and setups. Codes are publicly available at \href{https://github.com/Zehong-Ma/OVMR}{https://github.com/Zehong-Ma/OVMR}.
Enhance Image Classification via Inter-Class Image Mixup with Diffusion Model
Mar 28, 2024



Text-to-image (T2I) generative models have recently emerged as a powerful tool, enabling the creation of photo-realistic images and giving rise to a multitude of applications. However, the effective integration of T2I models into fundamental image classification tasks remains an open question. A prevalent strategy to bolster image classification performance is through augmenting the training set with synthetic images generated by T2I models. In this study, we scrutinize the shortcomings of both current generative and conventional data augmentation techniques. Our analysis reveals that these methods struggle to produce images that are both faithful (in terms of foreground objects) and diverse (in terms of background contexts) for domain-specific concepts. To tackle this challenge, we introduce an innovative inter-class data augmentation method known as Diff-Mix (https://github.com/Zhicaiwww/Diff-Mix), which enriches the dataset by performing image translations between classes. Our empirical results demonstrate that Diff-Mix achieves a better balance between faithfulness and diversity, leading to a marked improvement in performance across diverse image classification scenarios, including few-shot, conventional, and long-tail classifications for domain-specific datasets.
Incorporating Visual Experts to Resolve the Information Loss in Multimodal Large Language Models
Jan 13, 2024Multimodal Large Language Models (MLLMs) are experiencing rapid growth, yielding a plethora of noteworthy contributions in recent months. The prevailing trend involves adopting data-driven methodologies, wherein diverse instruction-following datasets are collected. However, a prevailing challenge persists in these approaches, specifically in relation to the limited visual perception ability, as CLIP-like encoders employed for extracting visual information from inputs. Though these encoders are pre-trained on billions of image-text pairs, they still grapple with the information loss dilemma, given that textual captions only partially capture the contents depicted in images. To address this limitation, this paper proposes to improve the visual perception ability of MLLMs through a mixture-of-experts knowledge enhancement mechanism. Specifically, we introduce a novel method that incorporates multi-task encoders and visual tools into the existing MLLMs training and inference pipeline, aiming to provide a more comprehensive and accurate summarization of visual inputs. Extensive experiments have evaluated its effectiveness of advancing MLLMs, showcasing improved visual perception achieved through the integration of visual experts.
Boosting Segment Anything Model Towards Open-Vocabulary Learning
Dec 06, 2023

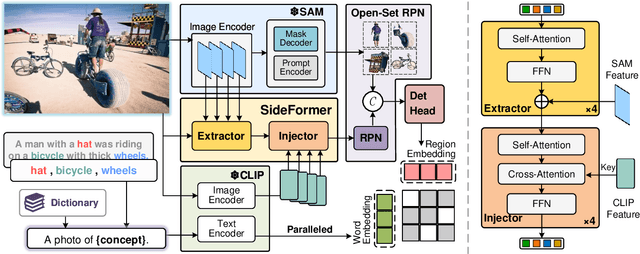

The recent Segment Anything Model (SAM) has emerged as a new paradigmatic vision foundation model, showcasing potent zero-shot generalization and flexible prompting. Despite SAM finding applications and adaptations in various domains, its primary limitation lies in the inability to grasp object semantics. In this paper, we present Sambor to seamlessly integrate SAM with the open-vocabulary object detector in an end-to-end framework. While retaining all the remarkable capabilities inherent to SAM, we enhance it with the capacity to detect arbitrary objects based on human inputs like category names or reference expressions. To accomplish this, we introduce a novel SideFormer module that extracts SAM features to facilitate zero-shot object localization and inject comprehensive semantic information for open-vocabulary recognition. In addition, we devise an open-set region proposal network (Open-set RPN), enabling the detector to acquire the open-set proposals generated by SAM. Sambor demonstrates superior zero-shot performance across benchmarks, including COCO and LVIS, proving highly competitive against previous SoTA methods. We aspire for this work to serve as a meaningful endeavor in endowing SAM to recognize diverse object categories and advancing open-vocabulary learning with the support of vision foundation models.
HalluciDoctor: Mitigating Hallucinatory Toxicity in Visual Instruction Data
Nov 22, 2023



Multi-modal Large Language Models (MLLMs) tuned on machine-generated instruction-following data have demonstrated remarkable performance in various multi-modal understanding and generation tasks. However, the hallucinations inherent in machine-generated data, which could lead to hallucinatory outputs in MLLMs, remain under-explored. This work aims to investigate various hallucinations (i.e., object, relation, attribute hallucinations) and mitigate those hallucinatory toxicities in large-scale machine-generated visual instruction datasets. Drawing on the human ability to identify factual errors, we present a novel hallucination detection and elimination framework, HalluciDoctor, based on the cross-checking paradigm. We use our framework to identify and eliminate hallucinations in the training data automatically. Interestingly, HalluciDoctor also indicates that spurious correlations arising from long-tail object co-occurrences contribute to hallucinations. Based on that, we execute counterfactual visual instruction expansion to balance data distribution, thereby enhancing MLLMs' resistance to hallucinations. Comprehensive experiments on hallucination evaluation benchmarks show that our method successfully mitigates 44.6% hallucinations relatively and maintains competitive performance compared to LLaVA.The source code will be released at \url{https://github.com/Yuqifan1117/HalluciDoctor}.