 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCITlib: Multimodal Continual Instruction Tuning Library and Benchmark
Aug 10, 2025Continual learning aims to equip AI systems with the ability to continuously acquire and adapt to new knowledge without forgetting previously learned information, similar to human learning. While traditional continual learning methods focusing on unimodal tasks have achieved notable success, the emergence of Multimodal Large Language Models has brought increasing attention to Multimodal Continual Learning tasks involving multiple modalities, such as vision and language. In this setting, models are expected to not only mitigate catastrophic forgetting but also handle the challenges posed by cross-modal interactions and coordination. To facilitate research in this direction, we introduce MCITlib, a comprehensive and constantly evolving code library for continual instruction tuning of Multimodal Large Language Models. In MCITlib, we have currently implemented 8 representative algorithms for Multimodal Continual Instruction Tuning and systematically evaluated them on 2 carefully selected benchmarks. MCITlib will be continuously updated to reflect advances in the Multimodal Continual Learning field. The codebase is released at https://github.com/Ghy0501/MCITlib.
A Comprehensive Survey on Continual Learning in Generative Models
Jun 16, 2025The rapid advancement of generative models has enabled modern AI systems to comprehend and produce highly sophisticated content, even achieving human-level performance in specific domains. However, these models remain fundamentally constrained by catastrophic forgetting - a persistent challenge where adapting to new tasks typically leads to significant degradation in performance on previously learned tasks. To address this practical limitation, numerous approaches have been proposed to enhance the adaptability and scalability of generative models in real-world applications. In this work, we present a comprehensive survey of continual learning methods for mainstream generative models, including large language models, multimodal large language models, vision language action models, and diffusion models. Drawing inspiration from the memory mechanisms of the human brain, we systematically categorize these approaches into three paradigms: architecture-based, regularization-based, and replay-based methods, while elucidating their underlying methodologies and motivations. We further analyze continual learning setups for different generative models, including training objectives, benchmarks, and core backbones, offering deeper insights into the field. The project page of this paper is available at https://github.com/Ghy0501/Awesome-Continual-Learning-in-Generative-Models.
LLaVA-c: Continual Improved Visual Instruction Tuning
Jun 10, 2025Multimodal models like LLaVA-1.5 achieve state-of-the-art visual understanding through visual instruction tuning on multitask datasets, enabling strong instruction-following and multimodal performance. However, multitask learning faces challenges such as task balancing, requiring careful adjustment of data proportions, and expansion costs, where new tasks risk catastrophic forgetting and need costly retraining. Continual learning provides a promising alternative to acquiring new knowledge incrementally while preserving existing capabilities. However, current methods prioritize task-specific performance, neglecting base model degradation from overfitting to specific instructions, which undermines general capabilities. In this work, we propose a simple but effective method with two modifications on LLaVA-1.5: spectral-aware consolidation for improved task balance and unsupervised inquiry regularization to prevent base model degradation. We evaluate both general and task-specific performance across continual pretraining and fine-tuning. Experiments demonstrate that LLaVA-c consistently enhances standard benchmark performance and preserves general capabilities. For the first time, we show that task-by-task continual learning can achieve results that match or surpass multitask joint learning. The code will be publicly released.
Federated Continual Instruction Tuning
Mar 17, 2025A vast amount of instruction tuning data is crucial for the impressive performance of Large Multimodal Models (LMMs), but the associated computational costs and data collection demands during supervised fine-tuning make it impractical for most researchers. Federated learning (FL) has the potential to leverage all distributed data and training resources to reduce the overhead of joint training. However, most existing methods assume a fixed number of tasks, while in real-world scenarios, clients continuously encounter new knowledge and often struggle to retain old tasks due to memory constraints. In this work, we introduce the Federated Continual Instruction Tuning (FCIT) benchmark to model this real-world challenge. Our benchmark includes two realistic scenarios, encompassing four different settings and twelve carefully curated instruction tuning datasets. To address the challenges posed by FCIT, we propose dynamic knowledge organization to effectively integrate updates from different tasks during training and subspace selective activation to allocate task-specific output during inference. Extensive experimental results demonstrate that our proposed method significantly enhances model performance across varying levels of data heterogeneity and catastrophic forgetting. Our source code and dataset will be made publicly available.
HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
Mar 17, 2025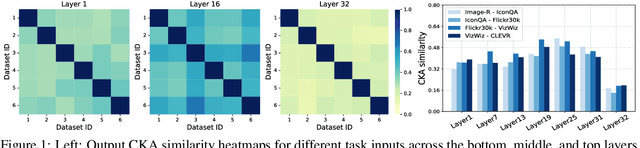
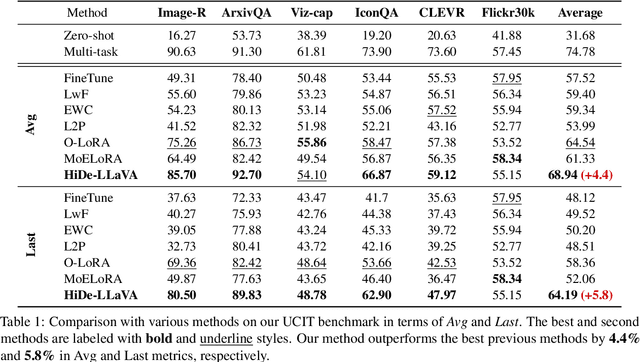
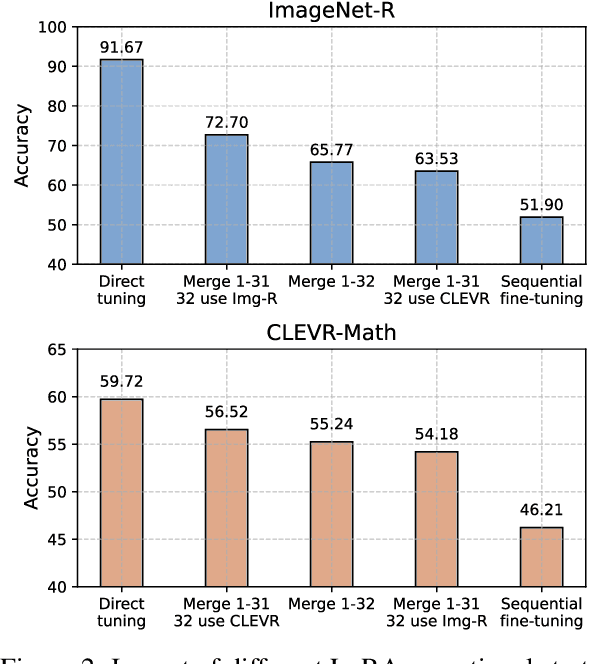
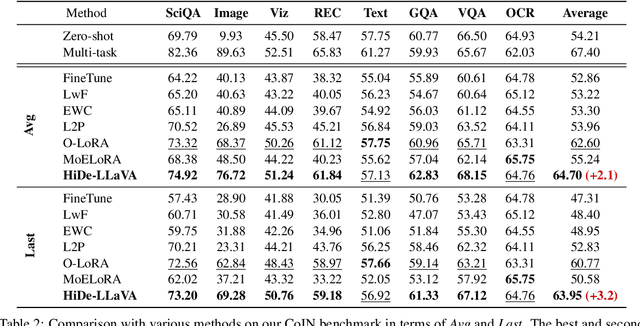
Instruction tuning is widely used to improve a pre-trained Multimodal Large Language Model (MLLM) by training it on curated task-specific datasets, enabling better comprehension of human instructions. However, it is infeasible to collect all possible instruction datasets simultaneously in real-world scenarios. Thus, enabling MLLM with continual instruction tuning is essential for maintaining their adaptability. However, existing methods often trade off memory efficiency for performance gains, significantly compromising overall efficiency. In this paper, we propose a task-specific expansion and task-general fusion framework based on the variations in Centered Kernel Alignment (CKA) similarity across different model layers when trained on diverse datasets. Furthermore, we analyze the information leakage present in the existing benchmark and propose a new and more challenging benchmark to rationally evaluate the performance of different methods. Comprehensive experiments showcase a significant performance improvement of our method compared to existing state-of-the-art methods. Our code will be public available.
Parameter Efficient Merging for Multimodal Large Language Models with Complementary Parameter Adaptation
Feb 24, 2025Fine-tuning pre-trained models with custom data leads to numerous expert models on specific tasks. Merging models into one universal model to empower multi-task ability refraining from data leakage has gained popularity. With the expansion in data and model size, parameter efficient tuning becomes the common practice for obtaining task-specific models efficiently. However, we observe that existing methods designed for full fine-tuning merging fail under efficient tuning. To address the issues, we analyze from low-rank decomposition and reveal that maintaining direction and compensating for gap between singular values are crucial for efficient model merging. Consequently, we propose CoPA-Merging, a training-free parameter efficient merging method with complementary parameter adaptation. Specifically, we (1) prune parameters and construct scaling coefficients from inter-parameter relation to compensate for performance drop from task interference and (2) perform cross-task normalization to enhance unseen task generalization. We establish a benchmark consisting of diverse multimodal tasks, on which we conduct experiments to certificate the outstanding performance and generalizability of our method. Additional study and extensive analyses further showcase the effectiveness.
DESIRE: Dynamic Knowledge Consolidation for Rehearsal-Free Continual Learning
Nov 28, 2024Continual learning aims to equip models with the ability to retain previously learned knowledge like a human. Recent work incorporating Parameter-Efficient Fine-Tuning has revitalized the field by introducing lightweight extension modules. However, existing methods usually overlook the issue of information leakage caused by the fact that the experiment data have been used in pre-trained models. Once these duplicate data are removed in the pre-training phase, their performance can be severely affected. In this paper, we propose a new LoRA-based rehearsal-free method named DESIRE. Our method avoids imposing additional constraints during training to mitigate catastrophic forgetting, thereby maximizing the learning of new classes. To integrate knowledge from old and new tasks, we propose two efficient post-processing modules. On the one hand, we retain only two sets of LoRA parameters for merging and propose dynamic representation consolidation to calibrate the merged feature representation. On the other hand, we propose decision boundary refinement to address classifier bias when training solely on new class data. Extensive experiments demonstrate that our method achieves state-of-the-art performance on multiple datasets and strikes an effective balance between stability and plasticity. Our code will be publicly available.
ModalPrompt:Dual-Modality Guided Prompt for Continual Learning of Large Multimodal Models
Oct 08, 2024



Large Multimodal Models (LMMs) exhibit remarkable multi-tasking ability by learning mixed datasets jointly. However, novel tasks would be encountered sequentially in dynamic world, and continually fine-tuning LMMs often leads to performance degrades. To handle the challenges of catastrophic forgetting, existing methods leverage data replay or model expansion, both of which are not specially developed for LMMs and have their inherent limitations. In this paper, we propose a novel dual-modality guided prompt learning framework (ModalPrompt) tailored for multimodal continual learning to effectively learn new tasks while alleviating forgetting of previous knowledge. Concretely, we learn prototype prompts for each task and exploit efficient prompt selection for task identifiers and prompt fusion for knowledge transfer based on image-text supervision. Extensive experiments demonstrate the superiority of our approach, e.g., ModalPrompt achieves +20% performance gain on LMMs continual learning benchmarks with $\times$ 1.42 inference speed refraining from growing training cost in proportion to the number of tasks. The code will be made publically available.
Federated Class-Incremental Learning with Prototype Guided Transformer
Jan 04, 2024Existing federated learning methods have effectively addressed decentralized learning in scenarios involving data privacy and non-IID data. However, in real-world situations, each client dynamically learns new classes, requiring the global model to maintain discriminative capabilities for both new and old classes. To effectively mitigate the effects of catastrophic forgetting and data heterogeneity under low communication costs, we designed a simple and effective method named PLoRA. On the one hand, we adopt prototype learning to learn better feature representations and leverage the heuristic information between prototypes and class features to design a prototype re-weight module to solve the classifier bias caused by data heterogeneity without retraining the classification layer. On the other hand, our approach utilizes a pre-trained model as the backbone and utilizes LoRA to fine-tune with a tiny amount of parameters when learning new classes. Moreover, PLoRA does not rely on similarity-based module selection strategies, thereby further reducing communication overhead. Experimental results on standard datasets indicate that our method outperforms the state-of-the-art approaches significantly. More importantly, our method exhibits strong robustness and superiority in various scenarios and degrees of data heterogeneity. Our code will be publicly available.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021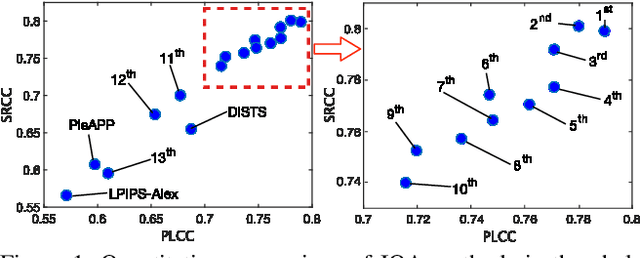
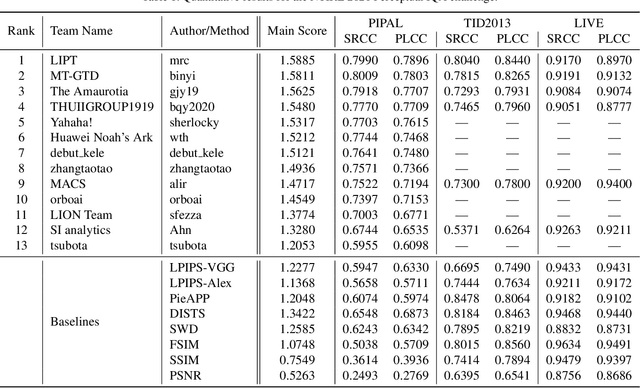

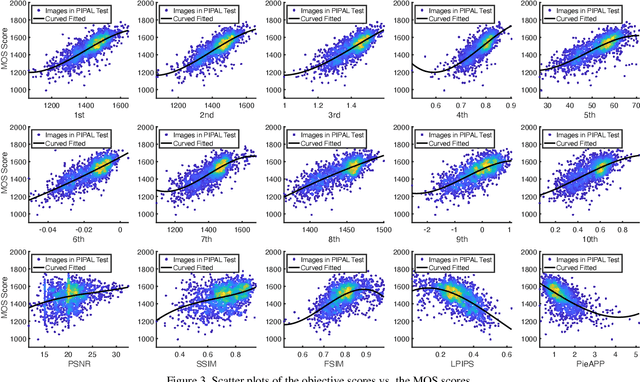
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.