 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021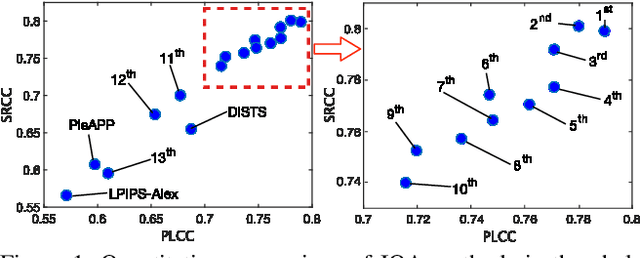
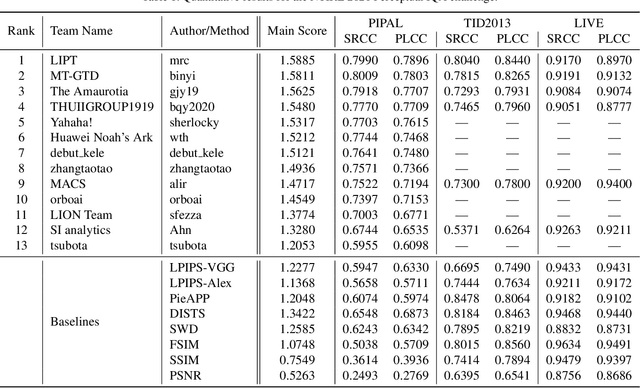

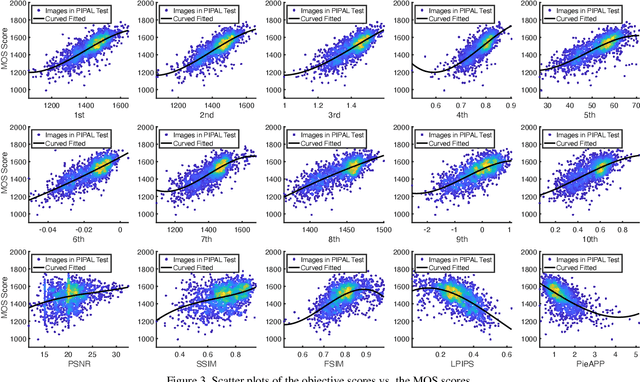
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Perceptual Image Quality Assessment with Transformers
May 05, 2021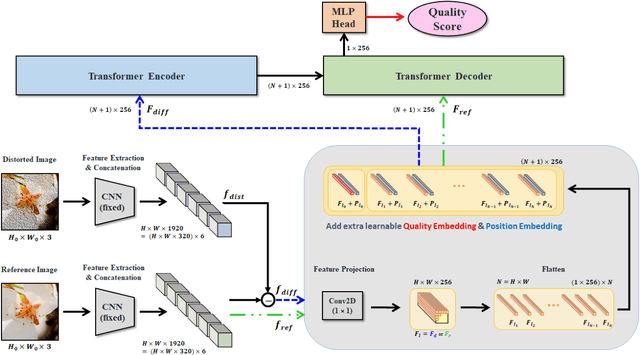

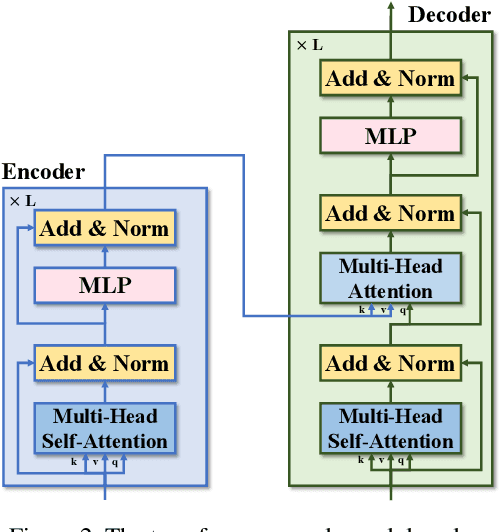
In this paper, we propose an image quality transformer (IQT) that successfully applies a transformer architecture to a perceptual full-reference image quality assessment (IQA) task. Perceptual representation becomes more important in image quality assessment. In this context, we extract the perceptual feature representations from each of input images using a convolutional neural network (CNN) backbone. The extracted feature maps are fed into the transformer encoder and decoder in order to compare a reference and distorted images. Following an approach of the transformer-based vision models, we use extra learnable quality embedding and position embedding. The output of the transformer is passed to a prediction head in order to predict a final quality score. The experimental results show that our proposed model has an outstanding performance for the standard IQA datasets. For a large-scale IQA dataset containing output images of generative model, our model also shows the promising results. The proposed IQT was ranked first among 13 participants in the NTIRE 2021 perceptual image quality assessment challenge. Our work will be an opportunity to further expand the approach for the perceptual IQA task.
Ambiguity of Objective Image Quality Metrics: A New Methodology for Performance Evaluation
Jan 19, 2021
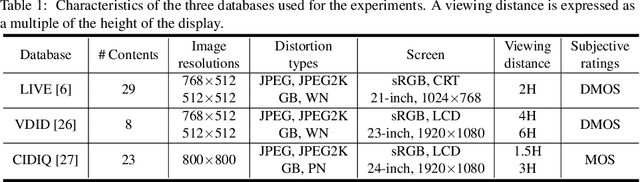
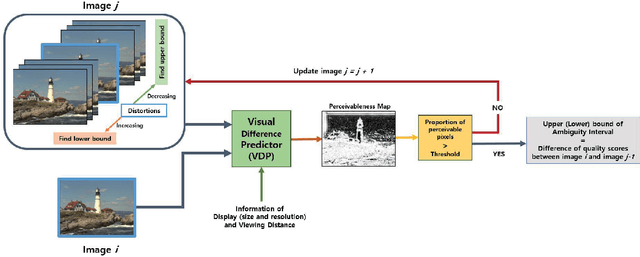
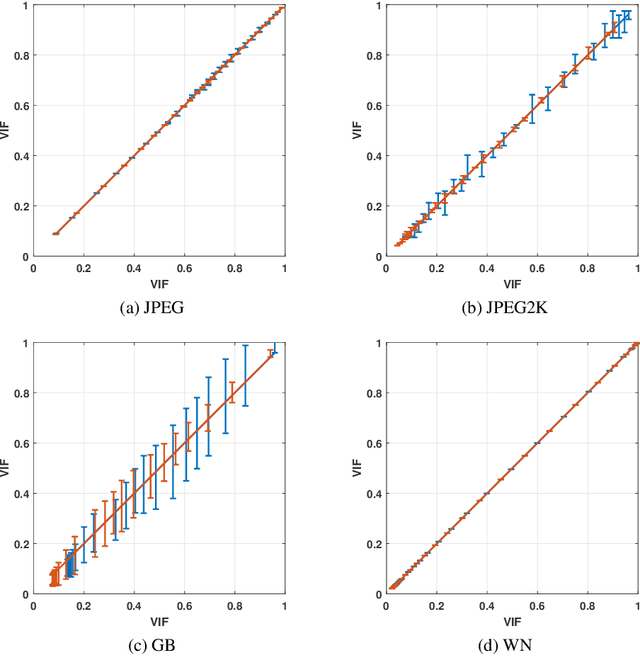
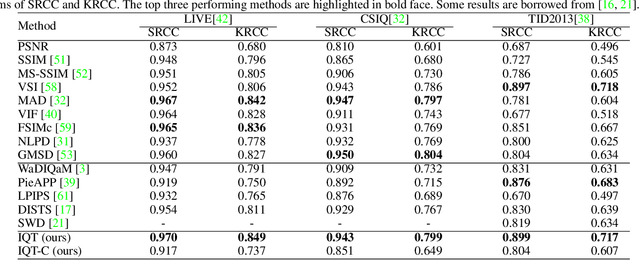
Objective image quality metrics try to estimate the perceptual quality of the given image by considering the characteristics of the human visual system. However, it is possible that the metrics produce different quality scores even for two images that are perceptually indistinguishable by human viewers, which have not been considered in the existing studies related to objective quality assessment. In this paper, we address the issue of ambiguity of objective image quality assessment. We propose an approach to obtain an ambiguity interval of an objective metric, within which the quality score difference is not perceptually significant. In particular, we use the visual difference predictor, which can consider viewing conditions that are important for visual quality perception. In order to demonstrate the usefulness of the proposed approach, we conduct experiments with 33 state-of-the-art image quality metrics in the viewpoint of their accuracy and ambiguity for three image quality databases. The results show that the ambiguity intervals can be applied as an additional figure of merit when conventional performance measurement does not determine superiority between the metrics. The effect of the viewing distance on the ambiguity interval is also shown.
Texture Transform Attention for Realistic Image Inpainting
Dec 08, 2020

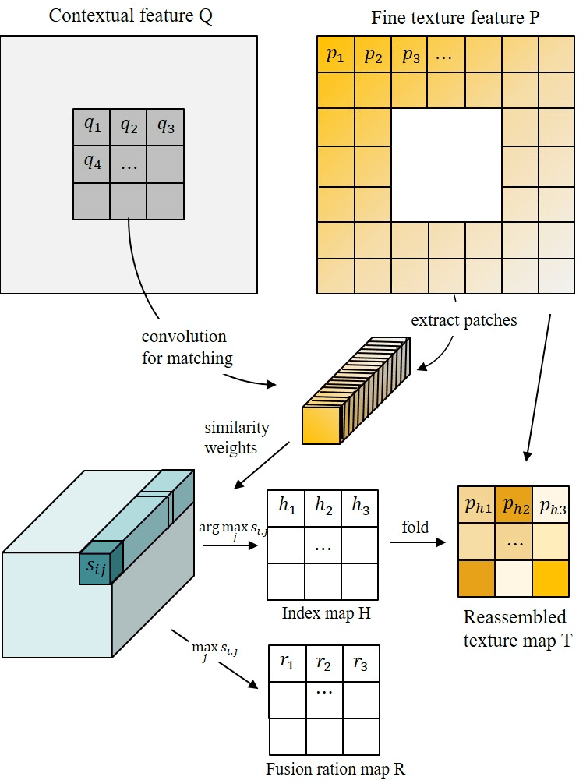

Over the last few years, the performance of inpainting to fill missing regions has shown significant improvements by using deep neural networks. Most of inpainting work create a visually plausible structure and texture, however, due to them often generating a blurry result, final outcomes appear unrealistic and make feel heterogeneity. In order to solve this problem, the existing methods have used a patch based solution with deep neural network, however, these methods also cannot transfer the texture properly. Motivated by these observation, we propose a patch based method. Texture Transform Attention network(TTA-Net) that better produces the missing region inpainting with fine details. The task is a single refinement network and takes the form of U-Net architecture that transfers fine texture features of encoder to coarse semantic features of decoder through skip-connection. Texture Transform Attention is used to create a new reassembled texture map using fine textures and coarse semantics that can efficiently transfer texture information as a result. To stabilize training process, we use a VGG feature layer of ground truth and patch discriminator. We evaluate our model end-to-end with the publicly available datasets CelebA-HQ and Places2 and demonstrate that images of higher quality can be obtained to the existing state-of-the-art approaches.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
Lightweight and Efficient Image Super-Resolution with Block State-based Recursive Network
Nov 30, 2018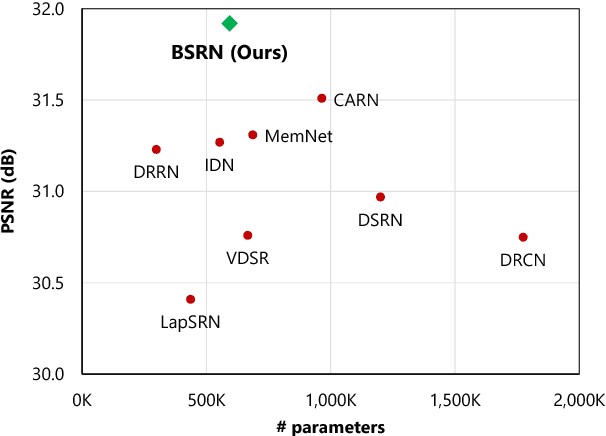
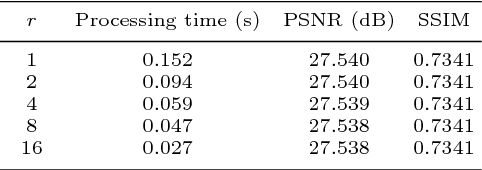
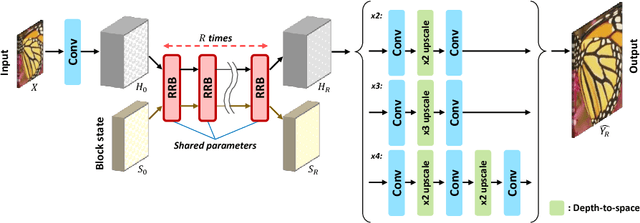
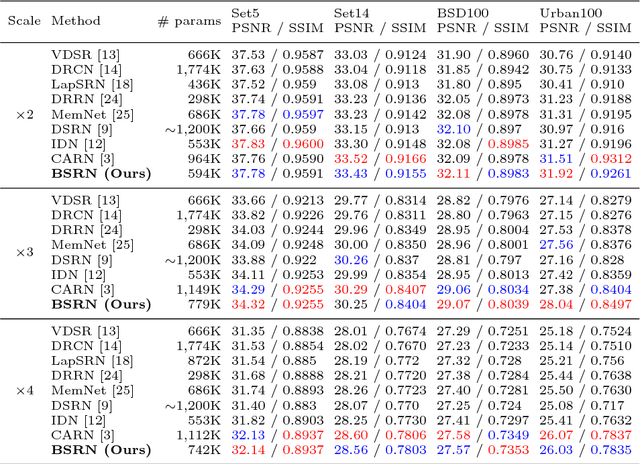
Recently, several deep learning-based image super-resolution methods have been developed by stacking massive numbers of layers. However, this leads too large model sizes and high computational complexities, thus some recursive parameter-sharing methods have been also proposed. Nevertheless, their designs do not properly utilize the potential of the recursive operation. In this paper, we propose a novel, lightweight, and efficient super-resolution method to maximize the usefulness of the recursive architecture, by introducing block state-based recursive network. By taking advantage of utilizing the block state, the recursive part of our model can easily track the status of the current image features. We show the benefits of the proposed method in terms of model size, speed, and efficiency. In addition, we show that our method outperforms the other state-of-the-art methods.
RAM: Residual Attention Module for Single Image Super-Resolution
Nov 29, 2018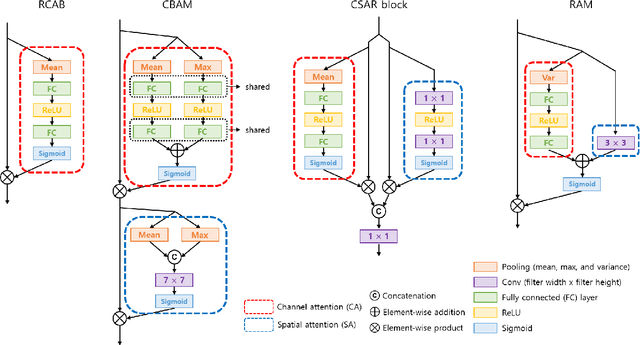



Attention mechanisms are a design trend of deep neural networks that stands out in various computer vision tasks. Recently, some works have attempted to apply attention mechanisms to single image super-resolution (SR) tasks. However, they apply the mechanisms to SR in the same or similar ways used for high-level computer vision problems without much consideration of the different nature between SR and other problems. In this paper, we propose a new attention method, which is composed of new channel-wise and spatial attention mechanisms optimized for SR and a new fused attention to combine them. Based on this, we propose a new residual attention module (RAM) and a SR network using RAM (SRRAM). We provide in-depth experimental analysis of different attention mechanisms in SR. It is shown that the proposed method can construct both deep and lightweight SR networks showing improved performance in comparison to existing state-of-the-art methods.
Generative adversarial network-based image super-resolution using perceptual content losses
Sep 21, 2018
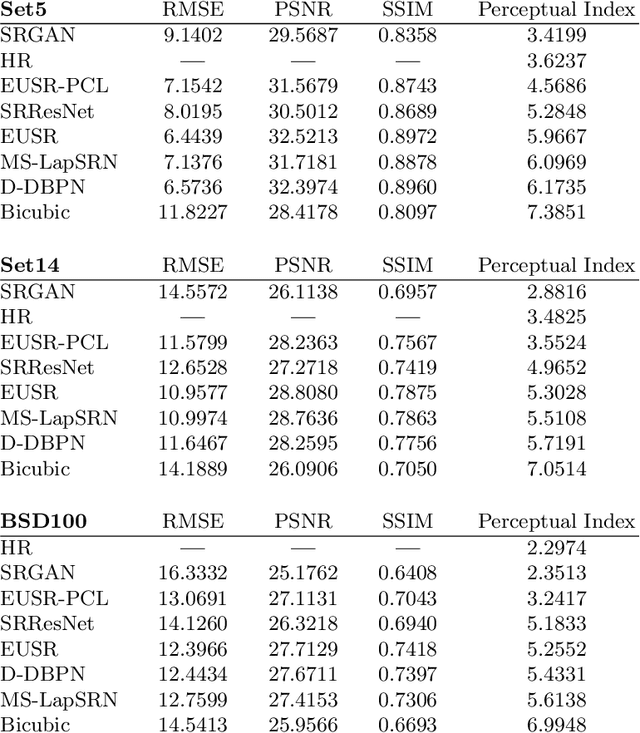

In this paper, we propose a deep generative adversarial network for super-resolution considering the trade-off between perception and distortion. Based on good performance of a recently developed model for super-resolution, i.e., deep residual network using enhanced upscale modules (EUSR), the proposed model is trained to improve perceptual performance with only slight increase of distortion. For this purpose, together with the conventional content loss, i.e., reconstruction loss such as L1 or L2, we consider additional losses in the training phase, which are the discrete cosine transform coefficients loss and differential content loss. These consider perceptual part in the content loss, i.e., consideration of proper high frequency components is helpful for the trade-off problem in super-resolution. The experimental results show that our proposed model has good performance for both perception and distortion, and is effective in perceptual super-resolution applications.
Deep Learning-based Image Super-Resolution Considering Quantitative and Perceptual Quality
Sep 13, 2018
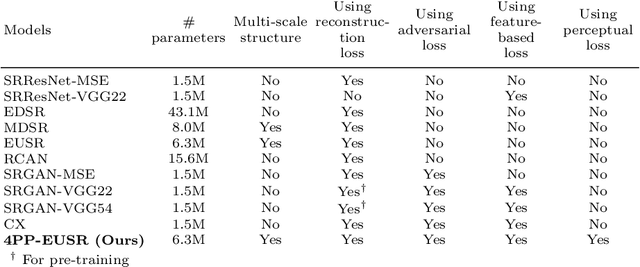
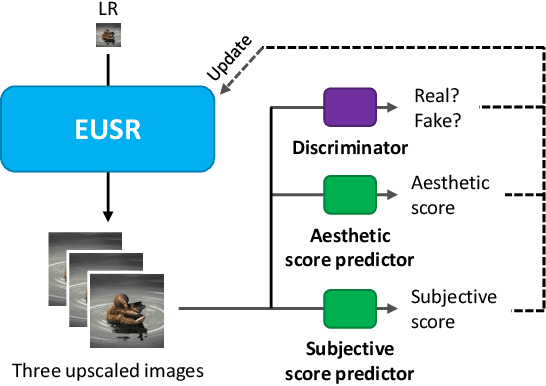
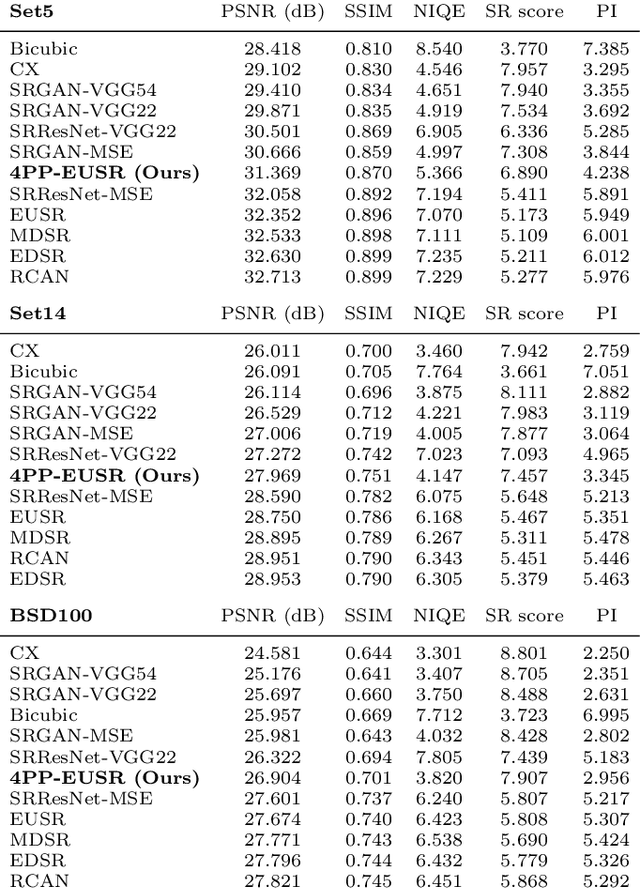
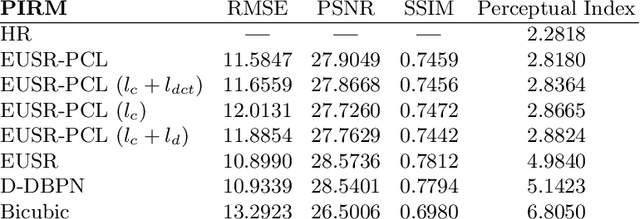
Recently, it has been shown that in super-resolution, there exists a tradeoff relationship between the quantitative and perceptual quality of super-resolved images, which correspond to the similarity to the ground-truth images and the naturalness, respectively. In this paper, we propose a novel super-resolution method that can improve the perceptual quality of the upscaled images while preserving the conventional quantitative performance. The proposed method employs a deep network for multi-pass upscaling in company with a discriminator network and two quantitative score predictor networks. Experimental results demonstrate that the proposed method achieves a good balance of the quantitative and perceptual quality, showing more satisfactory results than existing methods.