 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPO: Disentangled Perplexity Policy Optimization for Fine-grained Exploration-Exploitation Trade-Off
Apr 15, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed significant advances in the reasoning capabilities of Large Language Models (LLMs). However, effectively managing the exploration and exploitation trade-off remains a critical challenge. In this paper, we fully analyze the exploration and exploitation dilemma of extremely hard and easy samples during the training and propose a new fine-grained trade-off mechanism. Concretely, we introduce a perplexity space disentangling strategy that divides the sample space into distinct exploration (high perplexity) and exploitation (low perplexity) subspaces, thereby mining fine-grained samples requiring exploration-exploitation trade-off. Subsequently, we propose a bidirectional reward allocation mechanism with a minimum impact on verification rewards to implement perplexity-guided exploration and exploitation, enabling more stable policy optimization. Finally, we have evaluated our method on two mainstream tasks: mathematical reasoning and function calling, and experimental results demonstrate the superiority of the proposed method, confirming its effectiveness in enhancing LLM performance by fine-grained exploration-exploitation trade-off.
Direct Segmentation without Logits Optimization for Training-Free Open-Vocabulary Semantic Segmentation
Apr 09, 2026Open-vocabulary semantic segmentation (OVSS) aims to segment arbitrary category regions in images using open-vocabulary prompts, necessitating that existing methods possess pixel-level vision-language alignment capability. Typically, this capability involves computing the cosine similarity, \ie, logits, between visual and linguistic features, and minimizing the distribution discrepancy between the logits and the ground truth (GT) to generate optimal logits that are subsequently used to construct segmentation maps, yet it depends on time-consuming iterative training or model-specific attention modulation. In this work, we propose a more direct approach that eschews the logits-optimization process by directly deriving an analytic solution for the segmentation map. We posit a key hypothesis: the distribution discrepancy encodes semantic information; specifically, this discrepancy exhibits consistency across patches belonging to the same category but inconsistency across different categories. Based on this hypothesis, we directly utilize the analytic solution of this distribution discrepancy as the semantic maps. In other words, we reformulate the optimization of the distribution discrepancy as deriving its analytic solution, thereby eliminating time-consuming iterative training, freeing us from model-specific attention modulation, and achieving state-of-the-art performance on eight benchmark datasets.
Beyond Semantics: Uncovering the Physics of Fakes via Universal Physical Descriptors for Cross-Modal Synthetic Detection
Apr 06, 2026The rapid advancement of AI generated content (AIGC) has blurred the boundaries between real and synthetic images, exposing the limitations of existing deepfake detectors that often overfit to specific generative models. This adaptability crisis calls for a fundamental reexamination of the intrinsic physical characteristics that distinguish natural from AI-generated images. In this paper, we address two critical research questions: (1) What physical features can stably and robustly discriminate AI generated images across diverse datasets and generative architectures? (2) Can these objective pixel-level features be integrated into multimodal models like CLIP to enhance detection performance while mitigating the unreliability of language-based information? To answer these questions, we conduct a comprehensive exploration of 15 physical features across more than 20 datasets generated by various GANs and diffusion models. We propose a novel feature selection algorithm that identifies five core physical features including Laplacian variance, Sobel statistics, and residual noise variance that exhibit consistent discriminative power across all tested datasets. These features are then converted into text encoded values and integrated with semantic captions to guide image text representation learning in CLIP. Extensive experiments demonstrate that our method achieves state-of-the-art performance on multiple Genimage benchmarks, with near-perfect accuracy (99.8%) on datasets such as Wukong and SDv1.4. By bridging pixel level authenticity with semantic understanding, this work pioneers the use of physically grounded features for trustworthy vision language modeling and opens new directions for mitigating hallucinations and textual inaccuracies in large multimodal models.
PC-CrossDiff: Point-Cluster Dual-Level Cross-Modal Differential Attention for Unified 3D Referring and Segmentation
Mar 18, 20263D Visual Grounding (3DVG) aims to localize the referent of natural language referring expressions through two core tasks: Referring Expression Comprehension (3DREC) and Segmentation (3DRES). While existing methods achieve high accuracy in simple, single-object scenes, they suffer from severe performance degradation in complex, multi-object scenes that are common in real-world settings, hindering practical deployment. Existing methods face two key challenges in complex, multi-object scenes: inadequate parsing of implicit localization cues critical for disambiguating visually similar objects, and ineffective suppression of dynamic spatial interference from co-occurring objects, resulting in degraded grounding accuracy. To address these challenges, we propose PC-CrossDiff, a unified dual-task framework with a dual-level cross-modal differential attention architecture for 3DREC and 3DRES. Specifically, the framework introduces: (i) Point-Level Differential Attention (PLDA) modules that apply bidirectional differential attention between text and point clouds, adaptively extracting implicit localization cues via learnable weights to improve discriminative representation; (ii) Cluster-Level Differential Attention (CLDA) modules that establish a hierarchical attention mechanism to adaptively enhance localization-relevant spatial relationships while suppressing ambiguous or irrelevant spatial relations through a localization-aware differential attention block. Our method achieves state-of-the-art performance on the ScanRefer, NR3D, and SR3D benchmarks. Notably, on the Implicit subsets of ScanRefer, it improves the Overall@0.50 score by +10.16% for the 3DREC task, highlighting its strong ability to parse implicit spatial cues.
SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
Aug 28, 2025
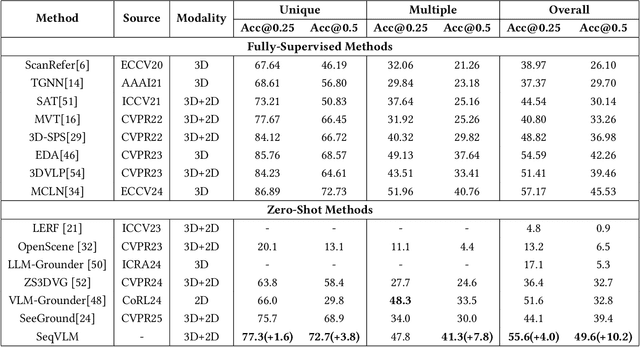

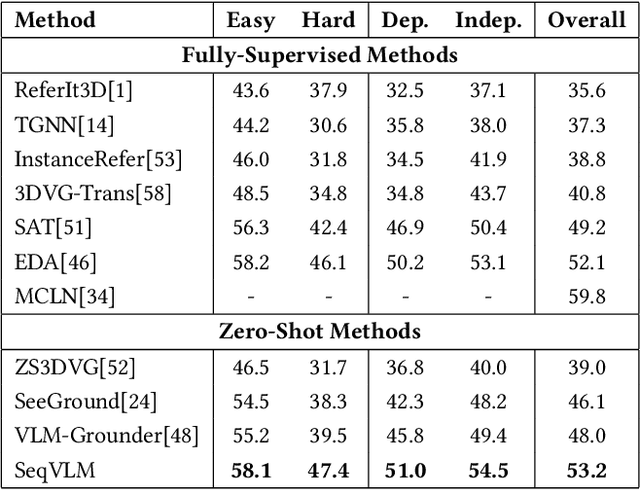
3D Visual Grounding (3DVG) aims to localize objects in 3D scenes using natural language descriptions. Although supervised methods achieve higher accuracy in constrained settings, zero-shot 3DVG holds greater promise for real-world applications since eliminating scene-specific training requirements. However, existing zero-shot methods face challenges of spatial-limited reasoning due to reliance on single-view localization, and contextual omissions or detail degradation. To address these issues, we propose SeqVLM, a novel zero-shot 3DVG framework that leverages multi-view real-world scene images with spatial information for target object reasoning. Specifically, SeqVLM first generates 3D instance proposals via a 3D semantic segmentation network and refines them through semantic filtering, retaining only semantic-relevant candidates. A proposal-guided multi-view projection strategy then projects these candidate proposals onto real scene image sequences, preserving spatial relationships and contextual details in the conversion process of 3D point cloud to images. Furthermore, to mitigate VLM computational overload, we implement a dynamic scheduling mechanism that iteratively processes sequances-query prompts, leveraging VLM's cross-modal reasoning capabilities to identify textually specified objects. Experiments on the ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, achieving Acc@0.25 scores of 55.6% and 53.2%, surpassing previous zero-shot methods by 4.0% and 5.2%, respectively, which advance 3DVG toward greater generalization and real-world applicability. The code is available at https://github.com/JiawLin/SeqVLM.
UniLDiff: Unlocking the Power of Diffusion Priors for All-in-One Image Restoration
Jul 31, 2025



All-in-One Image Restoration (AiOIR) has emerged as a promising yet challenging research direction. To address its core challenges, we propose a novel unified image restoration framework based on latent diffusion models (LDMs). Our approach structurally integrates low-quality visual priors into the diffusion process, unlocking the powerful generative capacity of diffusion models for diverse degradations. Specifically, we design a Degradation-Aware Feature Fusion (DAFF) module to enable adaptive handling of diverse degradation types. Furthermore, to mitigate detail loss caused by the high compression and iterative sampling of LDMs, we design a Detail-Aware Expert Module (DAEM) in the decoder to enhance texture and fine-structure recovery. Extensive experiments across multi-task and mixed degradation settings demonstrate that our method consistently achieves state-of-the-art performance, highlighting the practical potential of diffusion priors for unified image restoration. Our code will be released.
One-for-More: Continual Diffusion Model for Anomaly Detection
Feb 27, 2025With the rise of generative models, there is a growing interest in unifying all tasks within a generative framework. Anomaly detection methods also fall into this scope and utilize diffusion models to generate or reconstruct normal samples when given arbitrary anomaly images. However, our study found that the diffusion model suffers from severe ``faithfulness hallucination'' and ``catastrophic forgetting'', which can't meet the unpredictable pattern increments. To mitigate the above problems, we propose a continual diffusion model that uses gradient projection to achieve stable continual learning. Gradient projection deploys a regularization on the model updating by modifying the gradient towards the direction protecting the learned knowledge. But as a double-edged sword, it also requires huge memory costs brought by the Markov process. Hence, we propose an iterative singular value decomposition method based on the transitive property of linear representation, which consumes tiny memory and incurs almost no performance loss. Finally, considering the risk of ``over-fitting'' to normal images of the diffusion model, we propose an anomaly-masked network to enhance the condition mechanism of the diffusion model. For continual anomaly detection, ours achieves first place in 17/18 settings on MVTec and VisA. Code is available at https://github.com/FuNz-0/One-for-More
CLIP-FSAC++: Few-Shot Anomaly Classification with Anomaly Descriptor Based on CLIP
Dec 05, 2024



Industrial anomaly classification (AC) is an indispensable task in industrial manufacturing, which guarantees quality and safety of various product. To address the scarcity of data in industrial scenarios, lots of few-shot anomaly detection methods emerge recently. In this paper, we propose an effective few-shot anomaly classification (FSAC) framework with one-stage training, dubbed CLIP-FSAC++. Specifically, we introduce a cross-modality interaction module named Anomaly Descriptor following image and text encoders, which enhances the correlation of visual and text embeddings and adapts the representations of CLIP from pre-trained data to target data. In anomaly descriptor, image-to-text cross-attention module is used to obtain image-specific text embeddings and text-to-image cross-attention module is used to obtain text-specific visual embeddings. Then these modality-specific embeddings are used to enhance original representations of CLIP for better matching ability. Comprehensive experiment results are provided for evaluating our method in few-normal shot anomaly classification on VisA and MVTEC-AD for 1, 2, 4 and 8-shot settings. The source codes are at https://github.com/Jay-zzcoder/clip-fsac-pp
Fusion-then-Distillation: Toward Cross-modal Positive Distillation for Domain Adaptive 3D Semantic Segmentation
Oct 25, 2024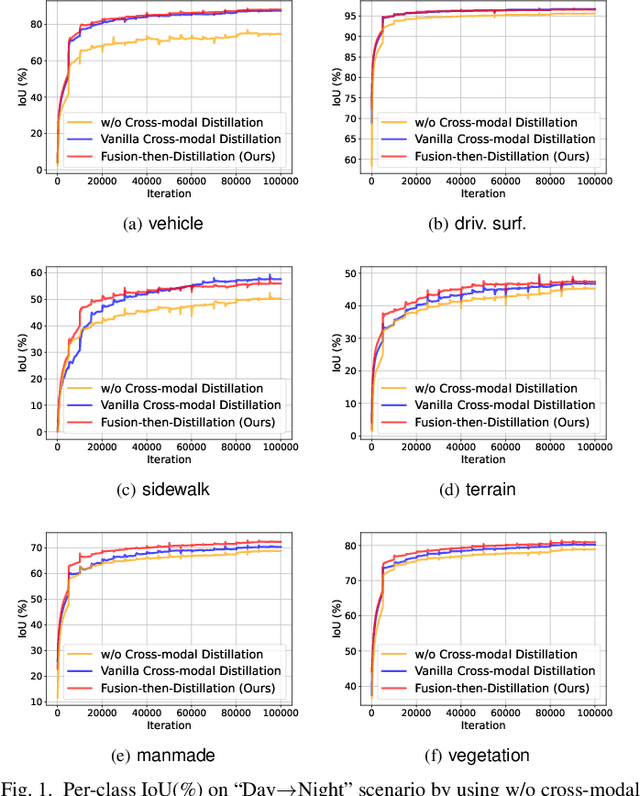
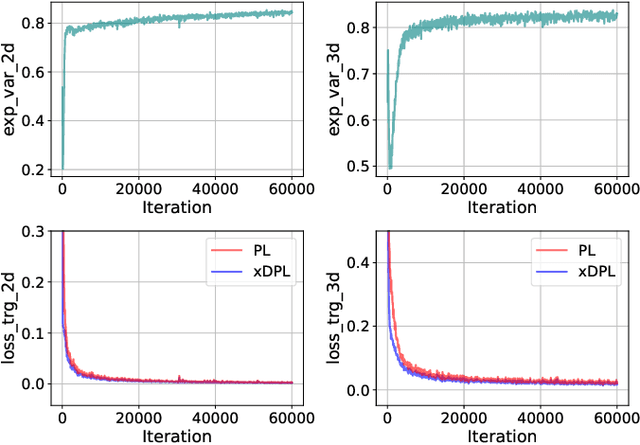
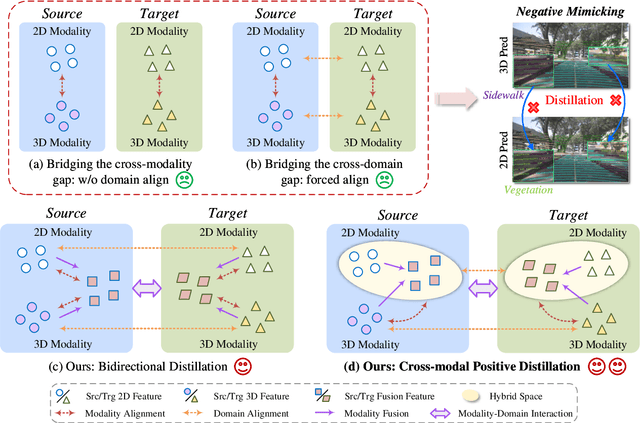
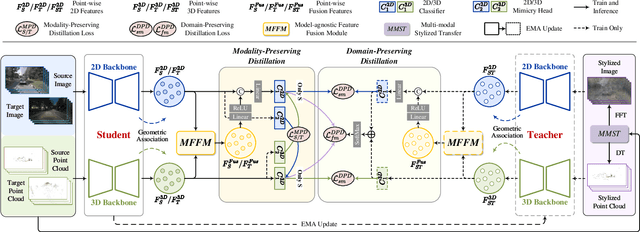
In cross-modal unsupervised domain adaptation, a model trained on source-domain data (e.g., synthetic) is adapted to target-domain data (e.g., real-world) without access to target annotation. Previous methods seek to mutually mimic cross-modal outputs in each domain, which enforces a class probability distribution that is agreeable in different domains. However, they overlook the complementarity brought by the heterogeneous fusion in cross-modal learning. In light of this, we propose a novel fusion-then-distillation (FtD++) method to explore cross-modal positive distillation of the source and target domains for 3D semantic segmentation. FtD++ realizes distribution consistency between outputs not only for 2D images and 3D point clouds but also for source-domain and augment-domain. Specially, our method contains three key ingredients. First, we present a model-agnostic feature fusion module to generate the cross-modal fusion representation for establishing a latent space. In this space, two modalities are enforced maximum correlation and complementarity. Second, the proposed cross-modal positive distillation preserves the complete information of multi-modal input and combines the semantic content of the source domain with the style of the target domain, thereby achieving domain-modality alignment. Finally, cross-modal debiased pseudo-labeling is devised to model the uncertainty of pseudo-labels via a self-training manner. Extensive experiments report state-of-the-art results on several domain adaptive scenarios under unsupervised and semi-supervised settings. Code is available at https://github.com/Barcaaaa/FtD-PlusPlus.
LLaCA: Multimodal Large Language Continual Assistant
Oct 08, 2024Instruction tuning guides the Multimodal Large Language Models (MLLMs) in aligning different modalities by designing text instructions, which seems to be an essential technique to enhance the capabilities and controllability of foundation models. In this framework, Multimodal Continual Instruction Tuning (MCIT) is adopted to continually instruct MLLMs to follow human intent in sequential datasets. We observe existing gradient update would heavily destroy the tuning performance on previous datasets and the zero-shot ability during continual instruction tuning. Exponential Moving Average (EMA) update policy owns the ability to trace previous parameters, which can aid in decreasing forgetting. However, its stable balance weight cannot deal with the ever-changing datasets, leading to the out-of-balance between plasticity and stability of MLLMs. In this paper, we propose a method called Multimodal Large Language Continual Assistant (LLaCA) to address the challenge. Starting from the trade-off prerequisite and EMA update, we propose the plasticity and stability ideal condition. Based on Taylor expansion in the loss function, we find the optimal balance weight is basically according to the gradient information and previous parameters. We automatically determine the balance weight and significantly improve the performance. Through comprehensive experiments on LLaVA-1.5 in a continual visual-question-answering benchmark, compared with baseline, our approach not only highly improves anti-forgetting ability (with reducing forgetting from 22.67 to 2.68), but also significantly promotes continual tuning performance (with increasing average accuracy from 41.31 to 61.89). Our code will be published soon.