 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperDefect-YOLO: Enhance YOLO with HyperGraph Computation for Industrial Defect Detection
Dec 05, 2024In the manufacturing industry, defect detection is an essential but challenging task aiming to detect defects generated in the process of production. Though traditional YOLO models presents a good performance in defect detection, they still have limitations in capturing high-order feature interrelationships, which hurdles defect detection in the complex scenarios and across the scales. To this end, we introduce hypergraph computation into YOLO framework, dubbed HyperDefect-YOLO (HD-YOLO), to improve representative ability and semantic exploitation. HD-YOLO consists of Defect Aware Module (DAM) and Mixed Graph Network (MGNet) in the backbone, which specialize for perception and extraction of defect features. To effectively aggregate multi-scale features, we propose HyperGraph Aggregation Network (HGANet) which combines hypergraph and attention mechanism to aggregate multi-scale features. Cross-Scale Fusion (CSF) is proposed to adaptively fuse and handle features instead of simple concatenation and convolution. Finally, we propose Semantic Aware Module (SAM) in the neck to enhance semantic exploitation for accurately localizing defects with different sizes in the disturbed background. HD-YOLO undergoes rigorous evaluation on public HRIPCB and NEU-DET datasets with significant improvements compared to state-of-the-art methods. We also evaluate HD-YOLO on self-built MINILED dataset collected in real industrial scenarios to demonstrate the effectiveness of the proposed method. The source codes are at https://github.com/Jay-zzcoder/HD-YOLO.
CLIP-FSAC++: Few-Shot Anomaly Classification with Anomaly Descriptor Based on CLIP
Dec 05, 2024



Industrial anomaly classification (AC) is an indispensable task in industrial manufacturing, which guarantees quality and safety of various product. To address the scarcity of data in industrial scenarios, lots of few-shot anomaly detection methods emerge recently. In this paper, we propose an effective few-shot anomaly classification (FSAC) framework with one-stage training, dubbed CLIP-FSAC++. Specifically, we introduce a cross-modality interaction module named Anomaly Descriptor following image and text encoders, which enhances the correlation of visual and text embeddings and adapts the representations of CLIP from pre-trained data to target data. In anomaly descriptor, image-to-text cross-attention module is used to obtain image-specific text embeddings and text-to-image cross-attention module is used to obtain text-specific visual embeddings. Then these modality-specific embeddings are used to enhance original representations of CLIP for better matching ability. Comprehensive experiment results are provided for evaluating our method in few-normal shot anomaly classification on VisA and MVTEC-AD for 1, 2, 4 and 8-shot settings. The source codes are at https://github.com/Jay-zzcoder/clip-fsac-pp
CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Jun 27, 2024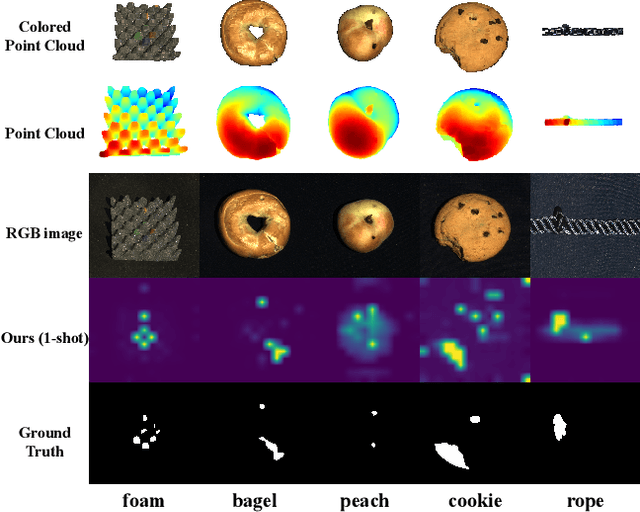
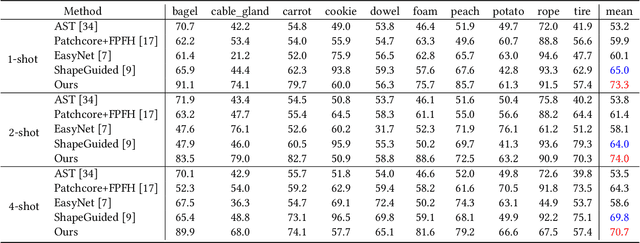
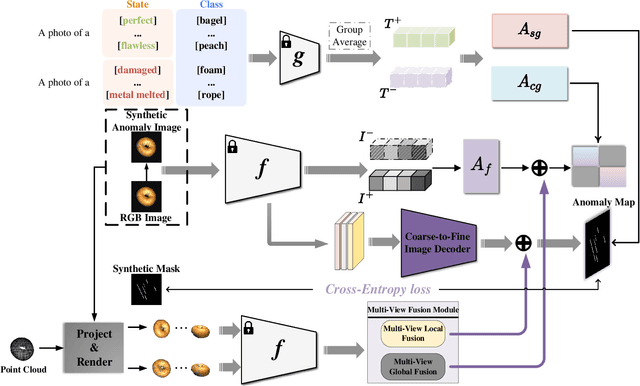
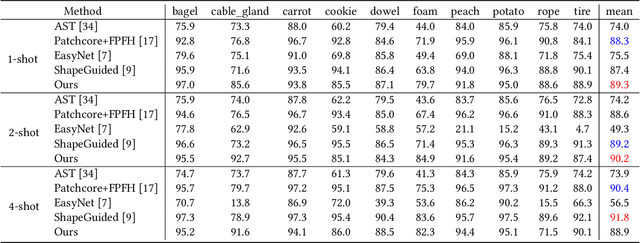
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
ModuLoRA: Finetuning 3-Bit LLMs on Consumer GPUs by Integrating with Modular Quantizers
Sep 28, 2023



We propose a memory-efficient finetuning algorithm for large language models (LLMs) that supports finetuning LLMs with 65B parameters in 3-bit or 4-bit precision on as little as one 48GB GPU. Our method, modular low-rank adaptation (ModuLoRA), integrates any user-specified weight quantizer with finetuning via low-rank adapters (LoRAs). Our approach relies on a simple quantization-agnostic backward pass that adaptively materializes low-precision LLM weights from a custom black-box quantization module. This approach enables finetuning 3-bit LLMs for the first time--leveraging state-of-the-art 3-bit OPTQ quantization often outperforms finetuning that relies on less sophisticated 4-bit and 8-bit methods. In our experiments, ModuLoRA attains competitive performance on text classification, natural language infernece, and instruction following tasks using significantly less memory than existing approaches, and we also surpass the state-of-the-art ROUGE score on a popular summarization task. We release ModuLoRA together with a series of low-precision models--including the first family of 3-bit instruction following Alpaca LLMs--as part of LLMTOOLS, a user-friendly library for quantizing, running, and finetuning LLMs on consumer GPUs.