 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUEL: Exact Likelihood for Masked Diffusion via Deterministic Unmasking
Mar 02, 2026Masked diffusion models (MDMs) generate text by iteratively selecting positions to unmask and then predicting tokens at those positions. Yet MDMs lack proper perplexity evaluation: the ELBO is a loose bound on likelihood under the training distribution, not the test-time distribution, while generative perplexity requires a biased external model and ignores diversity. To address this, we introduce the \textsc{DUEL} framework, which formalizes \emph{deterministic} position selection, unifying leading MDM sampling strategies. We prove \textbf{\textsc{DUEL} admits \emph{exact} likelihood computation} via a simple algorithm, evaluated under the same position selection used at test time. This \textbf{gives MDMs proper perplexity for the first time} -- the natural analogue of autoregressive perplexity. With proper perplexity in hand, we revisit key questions about MDMs. \textbf{MDMs are substantially better than previously thought}: the MDM-autoregressive perplexity gap shrinks by up to 32\% on in-domain data and 82\% on zero-shot benchmarks. \textsc{DUEL} enables the first principled comparison of fast, parallel samplers across compute budgets -- an analysis impossible with the ELBO and unreliable with generative perplexity -- identifying probability margin \citep{kim2025train} as a strong default. Finally, oracle search over position orderings reveals MDMs can far surpass autoregressive models -- achieving 36.47 vs.\ 52.11 perplexity on AG News -- demonstrating the ceiling of MDM performance has not yet been reached.
Learn from Your Mistakes: Self-Correcting Masked Diffusion Models
Feb 12, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models, enabling parallel token generation while achieving competitive performance. Despite these advantages, MDMs face a fundamental limitation: once tokens are unmasked, they remain fixed, leading to error accumulation and ultimately degrading sample quality. We address this by proposing a framework that trains a model to perform both unmasking and correction. By reusing outputs from the MDM denoising network as inputs for corrector training, we train a model to recover from potential mistakes. During generation we apply additional corrective refinement steps between unmasking ones in order to change decoded tokens and improve outputs. We name our training and sampling method Progressive Self-Correction (ProSeCo) for its unique ability to iteratively refine an entire sequence, including already generated tokens. We conduct extensive experimental validation across multiple conditional and unconditional tasks, demonstrating that ProSeCo yields better quality-efficiency trade-offs (up to ~2-3x faster sampling) and enables inference-time compute scaling to further increase sample quality beyond standard MDMs (up to ~1.3x improvement on benchmarks).
Encoder-Decoder Diffusion Language Models for Efficient Training and Inference
Oct 26, 2025Discrete diffusion models enable parallel token sampling for faster inference than autoregressive approaches. However, prior diffusion models use a decoder-only architecture, which requires sampling algorithms that invoke the full network at every denoising step and incur high computational cost. Our key insight is that discrete diffusion models perform two types of computation: 1) representing clean tokens and 2) denoising corrupted tokens, which enables us to use separate modules for each task. We propose an encoder-decoder architecture to accelerate discrete diffusion inference, which relies on an encoder to represent clean tokens and a lightweight decoder to iteratively refine a noised sequence. We also show that this architecture enables faster training of block diffusion models, which partition sequences into blocks for better quality and are commonly used in diffusion language model inference. We introduce a framework for Efficient Encoder-Decoder Diffusion (E2D2), consisting of an architecture with specialized training and sampling algorithms, and we show that E2D2 achieves superior trade-offs between generation quality and inference throughput on summarization, translation, and mathematical reasoning tasks. We provide the code, model weights, and blog post on the project page: https://m-arriola.com/e2d2
Probabilistic Graphical Models: A Concise Tutorial
Jul 23, 2025Probabilistic graphical modeling is a branch of machine learning that uses probability distributions to describe the world, make predictions, and support decision-making under uncertainty. Underlying this modeling framework is an elegant body of theory that bridges two mathematical traditions: probability and graph theory. This framework provides compact yet expressive representations of joint probability distributions, yielding powerful generative models for probabilistic reasoning. This tutorial provides a concise introduction to the formalisms, methods, and applications of this modeling framework. After a review of basic probability and graph theory, we explore three dominant themes: (1) the representation of multivariate distributions in the intuitive visual language of graphs, (2) algorithms for learning model parameters and graphical structures from data, and (3) algorithms for inference, both exact and approximate.
The Diffusion Duality
Jun 12, 2025Uniform-state discrete diffusion models hold the promise of fast text generation due to their inherent ability to self-correct. However, they are typically outperformed by autoregressive models and masked diffusion models. In this work, we narrow this performance gap by leveraging a key insight: Uniform-state diffusion processes naturally emerge from an underlying Gaussian diffusion. Our method, Duo, transfers powerful techniques from Gaussian diffusion to improve both training and sampling. First, we introduce a curriculum learning strategy guided by the Gaussian process, doubling training speed by reducing variance. Models trained with curriculum learning surpass autoregressive models in zero-shot perplexity on 3 of 7 benchmarks. Second, we present Discrete Consistency Distillation, which adapts consistency distillation from the continuous to the discrete setting. This algorithm unlocks few-step generation in diffusion language models by accelerating sampling by two orders of magnitude. We provide the code and model checkpoints on the project page: http://s-sahoo.github.io/duo
RanDeS: Randomized Delta Superposition for Multi-Model Compression
May 16, 2025From a multi-model compression perspective, model merging enables memory-efficient serving of multiple models fine-tuned from the same base, but suffers from degraded performance due to interference among their task-specific parameter adjustments (i.e., deltas). In this paper, we reformulate model merging as a compress-and-retrieve scheme, revealing that the task interference arises from the summation of irrelevant deltas during model retrieval. To address this issue, we use random orthogonal transformations to decorrelate these vectors into self-cancellation. We show that this approach drastically reduces interference, improving performance across both vision and language tasks. Since these transformations are fully defined by random seeds, adding new models requires no extra memory. Further, their data- and model-agnostic nature enables easy addition or removal of models with minimal compute overhead, supporting efficient and flexible multi-model serving.
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Mar 12, 2025Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/bd3lms/
The GAN is dead; long live the GAN! A Modern GAN Baseline
Jan 09, 2025
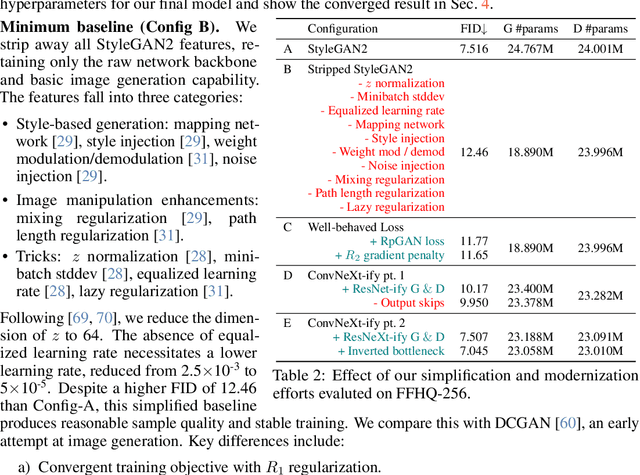


There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, our new loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline -- R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.
Simple Guidance Mechanisms for Discrete Diffusion Models
Dec 13, 2024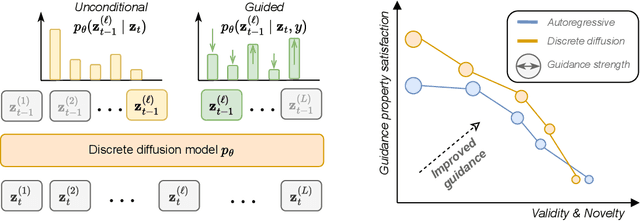
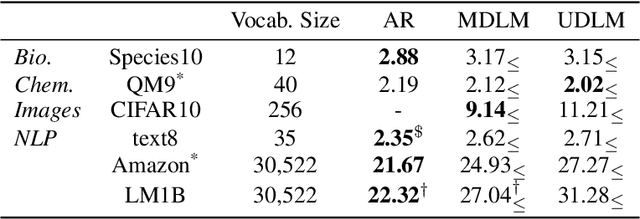
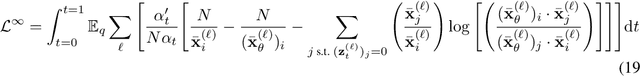
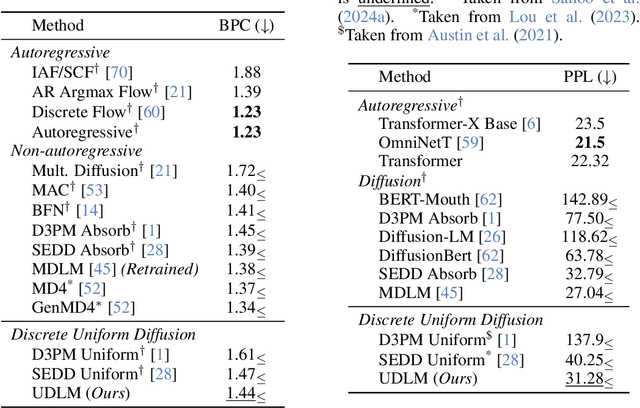
Diffusion models for continuous data gained widespread adoption owing to their high quality generation and control mechanisms. However, controllable diffusion on discrete data faces challenges given that continuous guidance methods do not directly apply to discrete diffusion. Here, we provide a straightforward derivation of classifier-free and classifier-based guidance for discrete diffusion, as well as a new class of diffusion models that leverage uniform noise and that are more guidable because they can continuously edit their outputs. We improve the quality of these models with a novel continuous-time variational lower bound that yields state-of-the-art performance, especially in settings involving guidance or fast generation. Empirically, we demonstrate that our guidance mechanisms combined with uniform noise diffusion improve controllable generation relative to autoregressive and diffusion baselines on several discrete data domains, including genomic sequences, small molecule design, and discretized image generation.
Calibrated Probabilistic Forecasts for Arbitrary Sequences
Sep 27, 2024

Real-world data streams can change unpredictably due to distribution shifts, feedback loops and adversarial actors, which challenges the validity of forecasts. We present a forecasting framework ensuring valid uncertainty estimates regardless of how data evolves. Leveraging the concept of Blackwell approachability from game theory, we introduce a forecasting framework that guarantees calibrated uncertainties for outcomes in any compact space (e.g., classification or bounded regression). We extend this framework to recalibrate existing forecasters, guaranteeing accurate uncertainties without sacrificing predictive performance. We implement both general-purpose gradient-based algorithms and algorithms optimized for popular special cases of our framework. Empirically, our algorithms improve calibration and downstream decision-making for energy systems.