 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pairwise Preferences: Listwise Reward-Aware Alignment for Diffusion Models
May 26, 2026Preference optimization has emerged as an efficient alternative to online reinforcement learning from human feedback (RLHF) for aligning text-to-image diffusion models. However, existing methods largely reduce supervision to binary pairwise comparisons. This pairwise reduction is limiting when training data naturally contains multiple candidate images for the same prompt, and when continuous reward scores can provide richer information than a single winner-loser label. To address these limitations, we propose Diffusion LAIR, a reward-aware listwise preference optimization method for diffusion models. For each prompt, LAIR converts reward scores across a group of candidate images into centered advantage weights, then optimizes an advantage-weighted regression objective on the implicit reward, defined as the denoising-loss improvement of the current model over a fixed reference model, with a quadratic penalty that regularizes the magnitude of the implicit reward. The resulting objective uses all candidates simultaneously rather than selecting pairs, and remains conservative by explicitly controlling the magnitude of the implicit reward. The LAIR objective admits a bounded closed-form optimum in implicit-reward space, clarifying how the regularization strength controls the magnitude of the preference update. Experiments show that Diffusion LAIR outperforms strong preference optimization baselines on SD1.5 and SDXL across text-to-image generation, compositional generation, and image editing benchmarks.
One-Step Generative Modeling via Wasserstein Gradient Flows
May 12, 2026Diffusion models and flow-based methods have shown impressive generative capability, especially for images, but their sampling is expensive because it requires many iterative updates. We introduce W-Flow, a framework for training a generator that transforms samples from a simple reference distribution into samples from a target data distribution in a single step. This is achieved in two steps: we first define an evolution from the reference distribution to the target distribution through a Wasserstein gradient flow that minimizes an energy functional; second, we train a static neural generator to compress this evolution into one-step generation. We instantiate the energy functional with the Sinkhorn divergence, which yields an efficient optimal-transport-based update rule that captures global distributional discrepancy and improves coverage of the target distribution. We further prove that the finite-sample training dynamics converge to the continuous-time distributional dynamics under suitable assumptions. Empirically, W-Flow sets a new state of the art for one-step ImageNet 256$\times$256 generation, achieving 1.29 FID, with improved mode coverage and domain transfer. Compared to multi-step diffusion models with similar FID scores, our method yields approximately 100$\times$ faster sampling. These results show that Wasserstein gradient flows provide a principled and effective foundation for fast and high-fidelity generative modeling.
Align Your Structures: Generating Trajectories with Structure Pretraining for Molecular Dynamics
Apr 05, 2026Generating molecular dynamics (MD) trajectories using deep generative models has attracted increasing attention, yet remains inherently challenging due to the limited availability of MD data and the complexities involved in modeling high-dimensional MD distributions. To overcome these challenges, we propose a novel framework that leverages structure pretraining for MD trajectory generation. Specifically, we first train a diffusion-based structure generation model on a large-scale conformer dataset, on top of which we introduce an interpolator module trained on MD trajectory data, designed to enforce temporal consistency among generated structures. Our approach effectively harnesses abundant structural data to mitigate the scarcity of MD trajectory data and effectively decomposes the intricate MD modeling task into two manageable subproblems: structural generation and temporal alignment. We comprehensively evaluate our method on the QM9 and DRUGS small-molecule datasets across unconditional generation, forward simulation, and interpolation tasks, and further extend our framework and analysis to tetrapeptide and protein monomer systems. Experimental results confirm that our approach excels in generating chemically realistic MD trajectories, as evidenced by remarkable improvements of accuracy in geometric, dynamical, and energetic measurements.
Adaptive Spectral Feature Forecasting for Diffusion Sampling Acceleration
Mar 02, 2026Diffusion models have become the dominant tool for high-fidelity image and video generation, yet are critically bottlenecked by their inference speed due to the numerous iterative passes of Diffusion Transformers. To reduce the exhaustive compute, recent works resort to the feature caching and reusing scheme that skips network evaluations at selected diffusion steps by using cached features in previous steps. However, their preliminary design solely relies on local approximation, causing errors to grow rapidly with large skips and leading to degraded sample quality at high speedups. In this work, we propose spectral diffusion feature forecaster (Spectrum), a training-free approach that enables global, long-range feature reuse with tightly controlled error. In particular, we view the latent features of the denoiser as functions over time and approximate them with Chebyshev polynomials. Specifically, we fit the coefficient for each basis via ridge regression, which is then leveraged to forecast features at multiple future diffusion steps. We theoretically reveal that our approach admits more favorable long-horizon behavior and yields an error bound that does not compound with the step size. Extensive experiments on various state-of-the-art image and video diffusion models consistently verify the superiority of our approach. Notably, we achieve up to 4.79$\times$ speedup on FLUX.1 and 4.67$\times$ speedup on Wan2.1-14B, while maintaining much higher sample quality compared with the baselines.
Improving Diffusion Language Model Decoding through Joint Search in Generation Order and Token Space
Jan 28, 2026Diffusion Language Models (DLMs) offer order-agnostic generation that can explore many possible decoding trajectories. However, current decoding methods commit to a single trajectory, limiting exploration in trajectory space. We introduce Order-Token Search to explore this space through jointly searching over generation order and token values. Its core is a likelihood estimator that scores denoising actions, enabling stable pruning and efficient exploration of diverse trajectories. Across mathematical reasoning and coding benchmarks, Order-Token Search consistently outperforms baselines on GSM8K, MATH500, Countdown, and HumanEval (3.1%, 3.8%, 7.9%, and 6.8% absolute over backbone), matching or surpassing diffu-GRPO post-trained d1-LLaDA. Our work establishes joint search as a key component for advancing decoding in DLMs.
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Dec 18, 2025Accurate and efficient discrete video tokenization is essential for long video sequences processing. Yet, the inherent complexity and variable information density of videos present a significant bottleneck for current tokenizers, which rigidly compress all content at a fixed rate, leading to redundancy or information loss. Drawing inspiration from Shannon's information theory, this paper introduces InfoTok, a principled framework for adaptive video tokenization. We rigorously prove that existing data-agnostic training methods are suboptimal in representation length, and present a novel evidence lower bound (ELBO)-based algorithm that approaches theoretical optimality. Leveraging this framework, we develop a transformer-based adaptive compressor that enables adaptive tokenization. Empirical results demonstrate state-of-the-art compression performance, saving 20% tokens without influence on performance, and achieving 2.3x compression rates while still outperforming prior heuristic adaptive approaches. By allocating tokens according to informational richness, InfoTok enables a more compressed yet accurate tokenization for video representation, offering valuable insights for future research.
GeoAda: Efficiently Finetune Geometric Diffusion Models with Equivariant Adapters
Jul 02, 2025Geometric diffusion models have shown remarkable success in molecular dynamics and structure generation. However, efficiently fine-tuning them for downstream tasks with varying geometric controls remains underexplored. In this work, we propose an SE(3)-equivariant adapter framework ( GeoAda) that enables flexible and parameter-efficient fine-tuning for controlled generative tasks without modifying the original model architecture. GeoAda introduces a structured adapter design: control signals are first encoded through coupling operators, then processed by a trainable copy of selected pretrained model layers, and finally projected back via decoupling operators followed by an equivariant zero-initialized convolution. By fine-tuning only these lightweight adapter modules, GeoAda preserves the model's geometric consistency while mitigating overfitting and catastrophic forgetting. We theoretically prove that the proposed adapters maintain SE(3)-equivariance, ensuring that the geometric inductive biases of the pretrained diffusion model remain intact during adaptation. We demonstrate the wide applicability of GeoAda across diverse geometric control types, including frame control, global control, subgraph control, and a broad range of application domains such as particle dynamics, molecular dynamics, human motion prediction, and molecule generation. Empirical results show that GeoAda achieves state-of-the-art fine-tuning performance while preserving original task accuracy, whereas other baselines experience significant performance degradation due to overfitting and catastrophic forgetting.
Fast and Distributed Equivariant Graph Neural Networks by Virtual Node Learning
Jun 24, 2025Equivariant Graph Neural Networks (GNNs) have achieved remarkable success across diverse scientific applications. However, existing approaches face critical efficiency challenges when scaling to large geometric graphs and suffer significant performance degradation when the input graphs are sparsified for computational tractability. To address these limitations, we introduce FastEGNN and DistEGNN, two novel enhancements to equivariant GNNs for large-scale geometric graphs. FastEGNN employs a key innovation: a small ordered set of virtual nodes that effectively approximates the large unordered graph of real nodes. Specifically, we implement distinct message passing and aggregation mechanisms for different virtual nodes to ensure mutual distinctiveness, and minimize Maximum Mean Discrepancy (MMD) between virtual and real coordinates to achieve global distributedness. This design enables FastEGNN to maintain high accuracy while efficiently processing large-scale sparse graphs. For extremely large-scale geometric graphs, we present DistEGNN, a distributed extension where virtual nodes act as global bridges between subgraphs in different devices, maintaining consistency while dramatically reducing memory and computational overhead. We comprehensively evaluate our models across four challenging domains: N-body systems (100 nodes), protein dynamics (800 nodes), Water-3D (8,000 nodes), and our new Fluid113K benchmark (113,000 nodes). Results demonstrate superior efficiency and performance, establishing new capabilities in large-scale equivariant graph learning. Code is available at https://github.com/GLAD-RUC/DistEGNN.
Reinforced Model Merging
Mar 27, 2025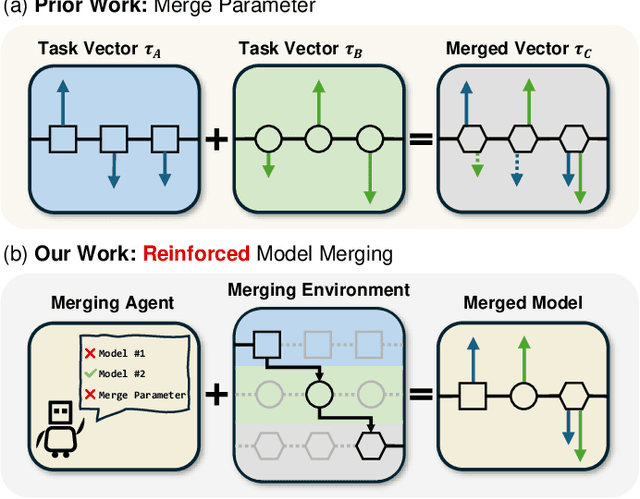
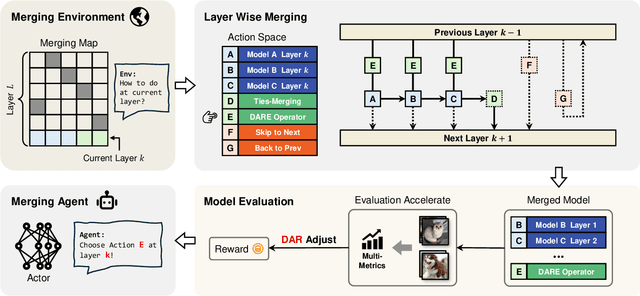
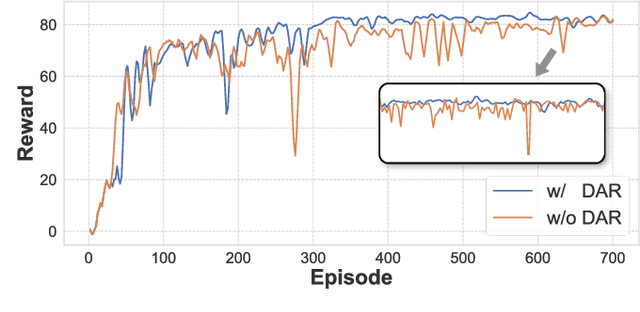
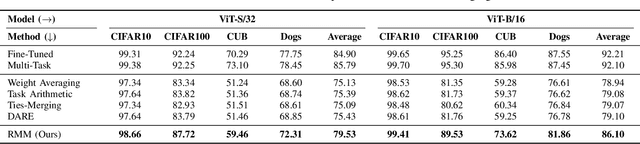
The success of large language models has garnered widespread attention for model merging techniques, especially training-free methods which combine model capabilities within the parameter space. However, two challenges remain: (1) uniform treatment of all parameters leads to performance degradation; (2) search-based algorithms are often inefficient. In this paper, we present an innovative framework termed Reinforced Model Merging (RMM), which encompasses an environment and agent tailored for merging tasks. These components interact to execute layer-wise merging actions, aiming to search the optimal merging architecture. Notably, RMM operates without any gradient computations on the original models, rendering it feasible for edge devices. Furthermore, by utilizing data subsets during the evaluation process, we addressed the bottleneck in the reward feedback phase, thereby accelerating RMM by up to 100 times. Extensive experiments demonstrate that RMM achieves state-of-the-art performance across various vision and NLP datasets and effectively overcomes the limitations of the existing baseline methods. Our code is available at https://github.com/WuDiHJQ/Reinforced-Model-Merging.
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Mar 12, 2025Diffusion language models offer unique benefits over autoregressive models due to their potential for parallelized generation and controllability, yet they lag in likelihood modeling and are limited to fixed-length generation. In this work, we introduce a class of block diffusion language models that interpolate between discrete denoising diffusion and autoregressive models. Block diffusion overcomes key limitations of both approaches by supporting flexible-length generation and improving inference efficiency with KV caching and parallel token sampling. We propose a recipe for building effective block diffusion models that includes an efficient training algorithm, estimators of gradient variance, and data-driven noise schedules to minimize the variance. Block diffusion sets a new state-of-the-art performance among diffusion models on language modeling benchmarks and enables generation of arbitrary-length sequences. We provide the code, along with the model weights and blog post on the project page: https://m-arriola.com/bd3lms/