 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphScout: Empowering Large Language Models with Intrinsic Exploration Ability for Agentic Graph Reasoning
Mar 02, 2026Knowledge graphs provide structured and reliable information for many real-world applications, motivating increasing interest in combining large language models (LLMs) with graph-based retrieval to improve factual grounding. Recent Graph-based Retrieval-Augmented Generation (GraphRAG) methods therefore introduce iterative interaction between LLMs and knowledge graphs to enhance reasoning capability. However, existing approaches typically depend on manually designed guidance and interact with knowledge graphs through a limited set of predefined tools, which substantially constrains graph exploration. To address these limitations, we propose GraphScout, a training-centric agentic graph reasoning framework equipped with more flexible graph exploration tools. GraphScout enables models to autonomously interact with knowledge graphs to synthesize structured training data which are then used to post-train LLMs, thereby internalizing agentic graph reasoning ability without laborious manual annotation or task curation. Extensive experiments across five knowledge-graph domains show that a small model (e.g., Qwen3-4B) augmented with GraphScout outperforms baseline methods built on leading LLMs (e.g., Qwen-Max) by an average of 16.7\% while requiring significantly fewer inference tokens. Moreover, GraphScout exhibits robust cross-domain transfer performance. Our code will be made publicly available~\footnote{https://github.com/Ying-Yuchen/_GraphScout_}.
R1-SyntheticVL: Is Synthetic Data from Generative Models Ready for Multimodal Large Language Model?
Feb 03, 2026In this work, we aim to develop effective data synthesis techniques that autonomously synthesize multimodal training data for enhancing MLLMs in solving complex real-world tasks. To this end, we propose Collective Adversarial Data Synthesis (CADS), a novel and general approach to synthesize high-quality, diverse and challenging multimodal data for MLLMs. The core idea of CADS is to leverage collective intelligence to ensure high-quality and diverse generation, while exploring adversarial learning to synthesize challenging samples for effectively driving model improvement. Specifically, CADS operates with two cyclic phases, i.e., Collective Adversarial Data Generation (CAD-Generate) and Collective Adversarial Data Judgment (CAD-Judge). CAD-Generate leverages collective knowledge to jointly generate new and diverse multimodal data, while CAD-Judge collaboratively assesses the quality of synthesized data. In addition, CADS introduces an Adversarial Context Optimization mechanism to optimize the generation context to encourage challenging and high-value data generation. With CADS, we construct MMSynthetic-20K and train our model R1-SyntheticVL, which demonstrates superior performance on various benchmarks.
Physics-informed Diffusion Generation for Geomagnetic Map Interpolation
Jan 31, 2026Geomagnetic map interpolation aims to infer unobserved geomagnetic data at spatial points, yielding critical applications in navigation and resource exploration. However, existing methods for scattered data interpolation are not specifically designed for geomagnetic maps, which inevitably leads to suboptimal performance due to detection noise and the laws of physics. Therefore, we propose a Physics-informed Diffusion Generation framework~(PDG) to interpolate incomplete geomagnetic maps. First, we design a physics-informed mask strategy to guide the diffusion generation process based on a local receptive field, effectively eliminating noise interference. Second, we impose a physics-informed constraint on the diffusion generation results following the kriging principle of geomagnetic maps, ensuring strict adherence to the laws of physics. Extensive experiments and in-depth analyses on four real-world datasets demonstrate the superiority and effectiveness of each component of PDG.
VTC-R1: Vision-Text Compression for Efficient Long-Context Reasoning
Jan 29, 2026Long-context reasoning has significantly empowered large language models (LLMs) to tackle complex tasks, yet it introduces severe efficiency bottlenecks due to the computational complexity. Existing efficient approaches often rely on complex additional training or external models for compression, which limits scalability and discards critical fine-grained information. In this paper, we propose VTC-R1, a new efficient reasoning paradigm that integrates vision-text compression into the reasoning process. Instead of processing lengthy textual traces, VTC-R1 renders intermediate reasoning segments into compact images, which are iteratively fed back into vision-language models as "optical memory." We construct a training dataset based on OpenR1-Math-220K achieving 3.4x token compression and fine-tune representative VLMs-Glyph and Qwen3-VL. Extensive experiments on benchmarks such as MATH500, AIME25, AMC23 and GPQA-D demonstrate that VTC-R1 consistently outperforms standard long-context reasoning. Furthermore, our approach significantly improves inference efficiency, achieving 2.7x speedup in end-to-end latency, highlighting its potential as a scalable solution for reasoning-intensive applications. Our code is available at https://github.com/w-yibo/VTC-R1.
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has driven substantial progress in reasoning-intensive domains like mathematics. However, optimizing open-ended generation remains challenging due to the lack of ground truth. While rubric-based evaluation offers a structured proxy for verification, existing methods suffer from scalability bottlenecks and coarse criteria, resulting in a supervision ceiling effect. To address this, we propose an automated Coarse-to-Fine Rubric Generation framework. By synergizing principle-guided synthesis, multi-model aggregation, and difficulty evolution, our approach produces comprehensive and highly discriminative criteria capable of capturing the subtle nuances. Based on this framework, we introduce RubricHub, a large-scale ($\sim$110k) and multi-domain dataset. We validate its utility through a two-stage post-training pipeline comprising Rubric-based Rejection Sampling Fine-Tuning (RuFT) and Reinforcement Learning (RuRL). Experimental results demonstrate that RubricHub unlocks significant performance gains: our post-trained Qwen3-14B achieves state-of-the-art (SOTA) results on HealthBench (69.3), surpassing proprietary frontier models such as GPT-5. The code and data will be released soon.
Replay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following
Dec 29, 2025Reinforcement Learning (RL) has shown promise for aligning Large Language Models (LLMs) to follow instructions with various constraints. Despite the encouraging results, RL improvement inevitably relies on sampling successful, high-quality responses; however, the initial model often struggles to generate responses that satisfy all constraints due to its limited capabilities, yielding sparse or indistinguishable rewards that impede learning. In this work, we propose Hindsight instruction Replay (HiR), a novel sample-efficient RL framework for complex instruction following tasks, which employs a select-then-rewrite strategy to replay failed attempts as successes based on the constraints that have been satisfied in hindsight. We perform RL on these replayed samples as well as the original ones, theoretically framing the objective as dual-preference learning at both the instruction- and response-level to enable efficient optimization using only a binary reward signal. Extensive experiments demonstrate that the proposed HiR yields promising results across different instruction following tasks, while requiring less computational budget. Our code and dataset is available at https://github.com/sastpg/HIR.
Tree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
Dual-branch Spatial-Temporal Self-supervised Representation for Enhanced Road Network Learning
Nov 10, 2025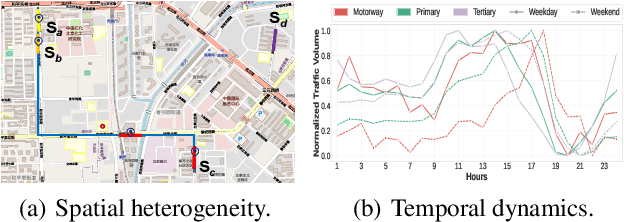



Road network representation learning (RNRL) has attracted increasing attention from both researchers and practitioners as various spatiotemporal tasks are emerging. Recent advanced methods leverage Graph Neural Networks (GNNs) and contrastive learning to characterize the spatial structure of road segments in a self-supervised paradigm. However, spatial heterogeneity and temporal dynamics of road networks raise severe challenges to the neighborhood smoothing mechanism of self-supervised GNNs. To address these issues, we propose a $\textbf{D}$ual-branch $\textbf{S}$patial-$\textbf{T}$emporal self-supervised representation framework for enhanced road representations, termed as DST. On one hand, DST designs a mix-hop transition matrix for graph convolution to incorporate dynamic relations of roads from trajectories. Besides, DST contrasts road representations of the vanilla road network against that of the hypergraph in a spatial self-supervised way. The hypergraph is newly built based on three types of hyperedges to capture long-range relations. On the other hand, DST performs next token prediction as the temporal self-supervised task on the sequences of traffic dynamics based on a causal Transformer, which is further regularized by differentiating traffic modes of weekdays from those of weekends. Extensive experiments against state-of-the-art methods verify the superiority of our proposed framework. Moreover, the comprehensive spatiotemporal modeling facilitates DST to excel in zero-shot learning scenarios.
CoVeR: Conformal Calibration for Versatile and Reliable Autoregressive Next-Token Prediction
Sep 05, 2025
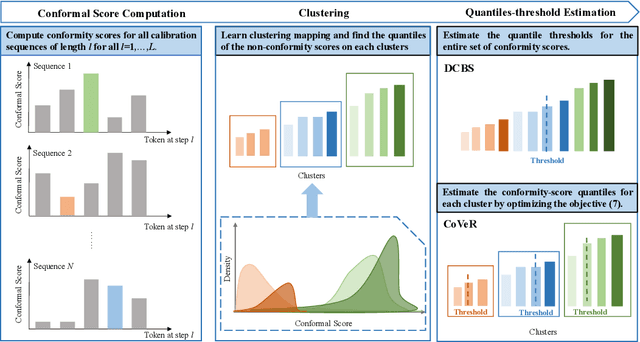
Autoregressive pre-trained models combined with decoding methods have achieved impressive performance on complex reasoning tasks. While mainstream decoding strategies such as beam search can generate plausible candidate sets, they often lack provable coverage guarantees, and struggle to effectively balance search efficiency with the need for versatile trajectories, particularly those involving long-tail sequences that are essential in certain real-world applications. To address these limitations, we propose \textsc{CoVeR}, a novel model-free decoding strategy wihtin the conformal prediction framework that simultaneously maintains a compact search space and ensures high coverage probability over desirable trajectories. Theoretically, we establish a PAC-style generalization bound, guaranteeing that \textsc{CoVeR} asymptotically achieves a coverage rate of at least $1 - \alpha$ for any target level $\alpha \in (0,1)$.
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.