 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning
Aug 23, 2025Recent advances in Large Language Models (LLMs) have underscored the potential of Reinforcement Learning (RL) to facilitate the emergence of reasoning capabilities. Despite the encouraging results, a fundamental dilemma persists as RL improvement relies on learning from high-quality samples, yet the exploration for such samples remains bounded by the inherent limitations of LLMs. This, in effect, creates an undesirable cycle in which what cannot be explored cannot be learned. In this work, we propose Rubric-Scaffolded Reinforcement Learning (RuscaRL), a novel instructional scaffolding framework designed to break the exploration bottleneck for general LLM reasoning. Specifically, RuscaRL introduces checklist-style rubrics as (1) explicit scaffolding for exploration during rollout generation, where different rubrics are provided as external guidance within task instructions to steer diverse high-quality responses. This guidance is gradually decayed over time, encouraging the model to internalize the underlying reasoning patterns; (2) verifiable rewards for exploitation during model training, where we can obtain robust LLM-as-a-Judge scores using rubrics as references, enabling effective RL on general reasoning tasks. Extensive experiments demonstrate the superiority of the proposed RuscaRL across various benchmarks, effectively expanding reasoning boundaries under the best-of-N evaluation. Notably, RuscaRL significantly boosts Qwen-2.5-7B-Instruct from 23.6 to 50.3 on HealthBench-500, surpassing GPT-4.1. Furthermore, our fine-tuned variant on Qwen3-30B-A3B-Instruct achieves 61.1 on HealthBench-500, outperforming leading LLMs including OpenAI-o3.
Bi-level Mean Field: Dynamic Grouping for Large-Scale MARL
May 10, 2025



Large-scale Multi-Agent Reinforcement Learning (MARL) often suffers from the curse of dimensionality, as the exponential growth in agent interactions significantly increases computational complexity and impedes learning efficiency. To mitigate this, existing efforts that rely on Mean Field (MF) simplify the interaction landscape by approximating neighboring agents as a single mean agent, thus reducing overall complexity to pairwise interactions. However, these MF methods inevitably fail to account for individual differences, leading to aggregation noise caused by inaccurate iterative updates during MF learning. In this paper, we propose a Bi-level Mean Field (BMF) method to capture agent diversity with dynamic grouping in large-scale MARL, which can alleviate aggregation noise via bi-level interaction. Specifically, BMF introduces a dynamic group assignment module, which employs a Variational AutoEncoder (VAE) to learn the representations of agents, facilitating their dynamic grouping over time. Furthermore, we propose a bi-level interaction module to model both inter- and intra-group interactions for effective neighboring aggregation. Experiments across various tasks demonstrate that the proposed BMF yields results superior to the state-of-the-art methods. Our code will be made publicly available.
From GNNs to Trees: Multi-Granular Interpretability for Graph Neural Networks
May 01, 2025



Interpretable Graph Neural Networks (GNNs) aim to reveal the underlying reasoning behind model predictions, attributing their decisions to specific subgraphs that are informative. However, existing subgraph-based interpretable methods suffer from an overemphasis on local structure, potentially overlooking long-range dependencies within the entire graphs. Although recent efforts that rely on graph coarsening have proven beneficial for global interpretability, they inevitably reduce the graphs to a fixed granularity. Such an inflexible way can only capture graph connectivity at a specific level, whereas real-world graph tasks often exhibit relationships at varying granularities (e.g., relevant interactions in proteins span from functional groups, to amino acids, and up to protein domains). In this paper, we introduce a novel Tree-like Interpretable Framework (TIF) for graph classification, where plain GNNs are transformed into hierarchical trees, with each level featuring coarsened graphs of different granularity as tree nodes. Specifically, TIF iteratively adopts a graph coarsening module to compress original graphs (i.e., root nodes of trees) into increasingly coarser ones (i.e., child nodes of trees), while preserving diversity among tree nodes within different branches through a dedicated graph perturbation module. Finally, we propose an adaptive routing module to identify the most informative root-to-leaf paths, providing not only the final prediction but also the multi-granular interpretability for the decision-making process. Extensive experiments on the graph classification benchmarks with both synthetic and real-world datasets demonstrate the superiority of TIF in interpretability, while also delivering a competitive prediction performance akin to the state-of-the-art counterparts.
A Survey on Backdoor Threats in Large Language Models (LLMs): Attacks, Defenses, and Evaluations
Feb 06, 2025



Large Language Models (LLMs) have achieved significantly advanced capabilities in understanding and generating human language text, which have gained increasing popularity over recent years. Apart from their state-of-the-art natural language processing (NLP) performance, considering their widespread usage in many industries, including medicine, finance, education, etc., security concerns over their usage grow simultaneously. In recent years, the evolution of backdoor attacks has progressed with the advancement of defense mechanisms against them and more well-developed features in the LLMs. In this paper, we adapt the general taxonomy for classifying machine learning attacks on one of the subdivisions - training-time white-box backdoor attacks. Besides systematically classifying attack methods, we also consider the corresponding defense methods against backdoor attacks. By providing an extensive summary of existing works, we hope this survey can serve as a guideline for inspiring future research that further extends the attack scenarios and creates a stronger defense against them for more robust LLMs.
Temporal Prototype-Aware Learning for Active Voltage Control on Power Distribution Networks
Jun 25, 2024


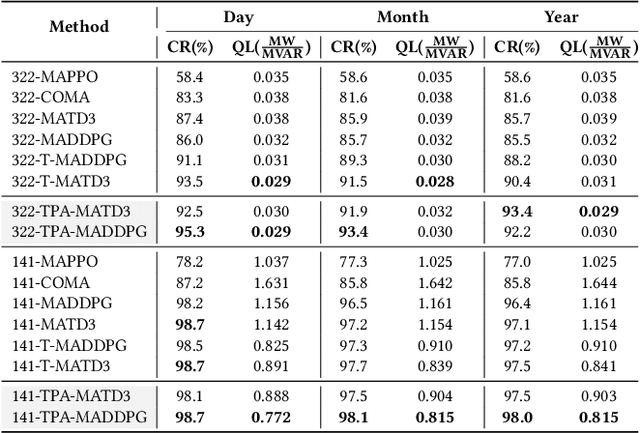
Active Voltage Control (AVC) on the Power Distribution Networks (PDNs) aims to stabilize the voltage levels to ensure efficient and reliable operation of power systems. With the increasing integration of distributed energy resources, recent efforts have explored employing multi-agent reinforcement learning (MARL) techniques to realize effective AVC. Existing methods mainly focus on the acquisition of short-term AVC strategies, i.e., only learning AVC within the short-term training trajectories of a singular diurnal cycle. However, due to the dynamic nature of load demands and renewable energy, the operation states of real-world PDNs may exhibit significant distribution shifts across varying timescales (e.g., daily and seasonal changes). This can render those short-term strategies suboptimal or even obsolete when performing continuous AVC over extended periods. In this paper, we propose a novel temporal prototype-aware learning method, abbreviated as TPA, to learn time-adaptive AVC under short-term training trajectories. At the heart of TPA are two complementary components, namely multi-scale dynamic encoder and temporal prototype-aware policy, that can be readily incorporated into various MARL methods. The former component integrates a stacked transformer network to learn underlying temporal dependencies at different timescales of the PDNs, while the latter implements a learnable prototype matching mechanism to construct a dedicated AVC policy that can dynamically adapt to the evolving operation states. Experimental results on the AVC benchmark with different PDN sizes demonstrate that the proposed TPA surpasses the state-of-the-art counterparts not only in terms of control performance but also by offering model transferability. Our code is available at https://github.com/Canyizl/TPA-for-AVC.
Advantage-Aware Policy Optimization for Offline Reinforcement Learning
Mar 12, 2024Offline Reinforcement Learning (RL) endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the Out-Of-Distribution (OOD) problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent Advantage-Weighted (AW) methods prioritize samples with high advantage values for agent training while inevitably leading to overfitting on these samples. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a Conditional Variational Auto-Encoder (CVAE) to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to state-of-the-art counterparts. Our code will be made publicly available.
Powerformer: A Section-adaptive Transformer for Power Flow Adjustment
Jan 10, 2024



In this paper, we present a novel transformer architecture tailored for learning robust power system state representations, which strives to optimize power dispatch for the power flow adjustment across different transmission sections. Specifically, our proposed approach, named Powerformer, develops a dedicated section-adaptive attention mechanism, separating itself from the self-attention used in conventional transformers. This mechanism effectively integrates power system states with transmission section information, which facilitates the development of robust state representations. Furthermore, by considering the graph topology of power system and the electrical attributes of bus nodes, we introduce two customized strategies to further enhance the expressiveness: graph neural network propagation and multi-factor attention mechanism. Extensive evaluations are conducted on three power system scenarios, including the IEEE 118-bus system, a realistic 300-bus system in China, and a large-scale European system with 9241 buses, where Powerformer demonstrates its superior performance over several baseline methods.
Is Centralized Training with Decentralized Execution Framework Centralized Enough for MARL?
May 27, 2023


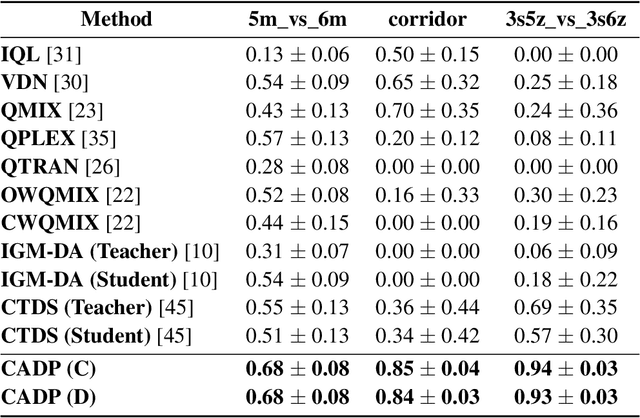
Centralized Training with Decentralized Execution (CTDE) has recently emerged as a popular framework for cooperative Multi-Agent Reinforcement Learning (MARL), where agents can use additional global state information to guide training in a centralized way and make their own decisions only based on decentralized local policies. Despite the encouraging results achieved, CTDE makes an independence assumption on agent policies, which limits agents to adopt global cooperative information from each other during centralized training. Therefore, we argue that existing CTDE methods cannot fully utilize global information for training, leading to an inefficient joint-policy exploration and even suboptimal results. In this paper, we introduce a novel Centralized Advising and Decentralized Pruning (CADP) framework for multi-agent reinforcement learning, that not only enables an efficacious message exchange among agents during training but also guarantees the independent policies for execution. Firstly, CADP endows agents the explicit communication channel to seek and take advices from different agents for more centralized training. To further ensure the decentralized execution, we propose a smooth model pruning mechanism to progressively constraint the agent communication into a closed one without degradation in agent cooperation capability. Empirical evaluations on StarCraft II micromanagement and Google Research Football benchmarks demonstrate that the proposed framework achieves superior performance compared with the state-of-the-art counterparts. Our code will be made publicly available.
Contrastive Identity-Aware Learning for Multi-Agent Value Decomposition
Nov 23, 2022



Value Decomposition (VD) aims to deduce the contributions of agents for decentralized policies in the presence of only global rewards, and has recently emerged as a powerful credit assignment paradigm for tackling cooperative Multi-Agent Reinforcement Learning (MARL) problems. One of the main challenges in VD is to promote diverse behaviors among agents, while existing methods directly encourage the diversity of learned agent networks with various strategies. However, we argue that these dedicated designs for agent networks are still limited by the indistinguishable VD network, leading to homogeneous agent behaviors and thus downgrading the cooperation capability. In this paper, we propose a novel Contrastive Identity-Aware learning (CIA) method, explicitly boosting the credit-level distinguishability of the VD network to break the bottleneck of multi-agent diversity. Specifically, our approach leverages contrastive learning to maximize the mutual information between the temporal credits and identity representations of different agents, encouraging the full expressiveness of credit assignment and further the emergence of individualities. The algorithm implementation of the proposed CIA module is simple yet effective that can be readily incorporated into various VD architectures. Experiments on the SMAC benchmarks and across different VD backbones demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code is available at https://github.com/liushunyu/CIA.
Interaction Pattern Disentangling for Multi-Agent Reinforcement Learning
Jul 08, 2022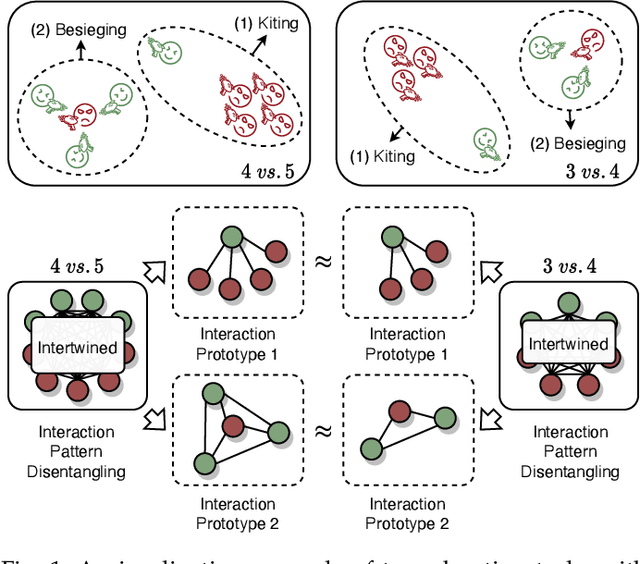

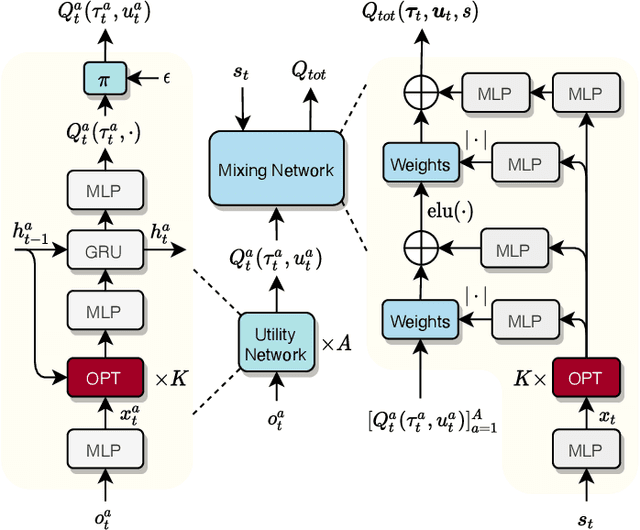
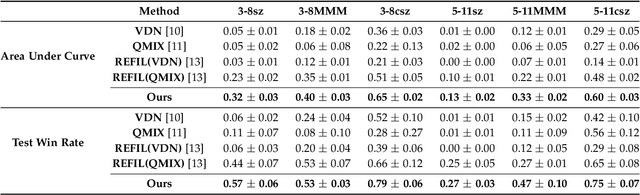
Deep cooperative multi-agent reinforcement learning has demonstrated its remarkable success over a wide spectrum of complex control tasks. However, recent advances in multi-agent learning mainly focus on value decomposition while leaving entity interactions still intertwined, which easily leads to over-fitting on noisy interactions between entities. In this work, we introduce a novel interactiOn Pattern disenTangling (OPT) method, to disentangle not only the joint value function into agent-wise value functions for decentralized execution, but also the entity interactions into interaction prototypes, each of which represents an underlying interaction pattern within a sub-group of the entities. OPT facilitates filtering the noisy interactions between irrelevant entities and thus significantly improves generalizability as well as interpretability. Specifically, OPT introduces a sparse disagreement mechanism to encourage sparsity and diversity among discovered interaction prototypes. Then the model selectively restructures these prototypes into a compact interaction pattern by an aggregator with learnable weights. To alleviate the training instability issue caused by partial observability, we propose to maximize the mutual information between the aggregation weights and the history behaviors of each agent. Experiments on both single-task and multi-task benchmarks demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code will be made publicly available.