 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDICE: Data Influence Cascade in Decentralized Learning
Jul 09, 2025Decentralized learning offers a promising approach to crowdsource data consumptions and computational workloads across geographically distributed compute interconnected through peer-to-peer networks, accommodating the exponentially increasing demands. However, proper incentives are still in absence, considerably discouraging participation. Our vision is that a fair incentive mechanism relies on fair attribution of contributions to participating nodes, which faces non-trivial challenges arising from the localized connections making influence ``cascade'' in a decentralized network. To overcome this, we design the first method to estimate \textbf{D}ata \textbf{I}nfluence \textbf{C}ascad\textbf{E} (DICE) in a decentralized environment. Theoretically, the framework derives tractable approximations of influence cascade over arbitrary neighbor hops, suggesting the influence cascade is determined by an interplay of data, communication topology, and the curvature of loss landscape. DICE also lays the foundations for applications including selecting suitable collaborators and identifying malicious behaviors. Project page is available at https://raiden-zhu.github.io/blog/2025/DICE/.
A Single Merging Suffices: Recovering Server-based Learning Performance in Decentralized Learning
Jul 09, 2025Decentralized learning provides a scalable alternative to traditional parameter-server-based training, yet its performance is often hindered by limited peer-to-peer communication. In this paper, we study how communication should be scheduled over time, including determining when and how frequently devices synchronize. Our empirical results show that concentrating communication budgets in the later stages of decentralized training markedly improves global generalization. Surprisingly, we uncover that fully connected communication at the final step, implemented by a single global merging, is sufficient to match the performance of server-based training. We further show that low communication in decentralized learning preserves the \textit{mergeability} of local models throughout training. Our theoretical contributions, which explains these phenomena, are first to establish that the globally merged model of decentralized SGD can converge faster than centralized mini-batch SGD. Technically, we novelly reinterpret part of the discrepancy among local models, which were previously considered as detrimental noise, as constructive components that accelerate convergence. This work challenges the common belief that decentralized learning generalizes poorly under data heterogeneity and limited communication, while offering new insights into model merging and neural network loss landscapes.
Adversarial Erasing with Pruned Elements: Towards Better Graph Lottery Ticket
Aug 10, 2023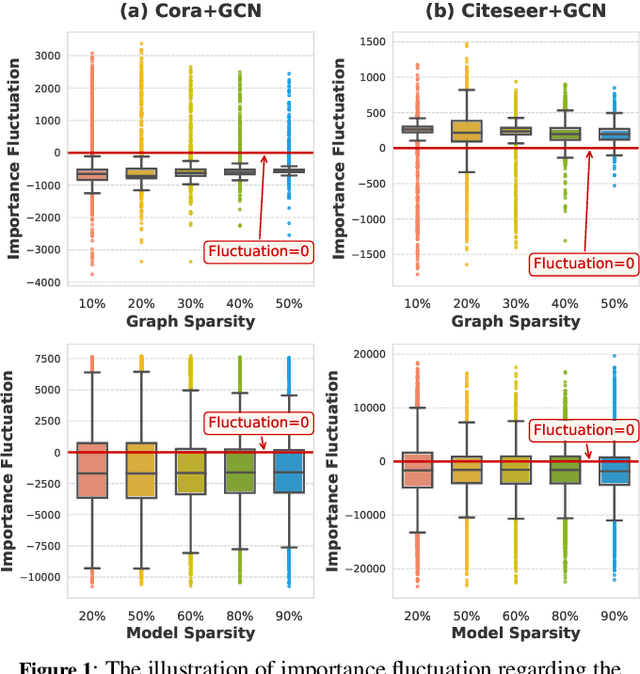

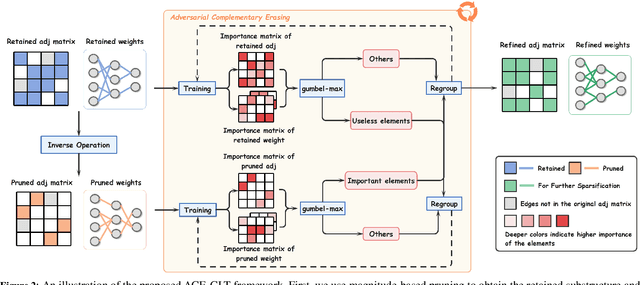

Graph Lottery Ticket (GLT), a combination of core subgraph and sparse subnetwork, has been proposed to mitigate the computational cost of deep Graph Neural Networks (GNNs) on large input graphs while preserving original performance. However, the winning GLTs in exisiting studies are obtained by applying iterative magnitude-based pruning (IMP) without re-evaluating and re-considering the pruned information, which disregards the dynamic changes in the significance of edges/weights during graph/model structure pruning, and thus limits the appeal of the winning tickets. In this paper, we formulate a conjecture, i.e., existing overlooked valuable information in the pruned graph connections and model parameters which can be re-grouped into GLT to enhance the final performance. Specifically, we propose an adversarial complementary erasing (ACE) framework to explore the valuable information from the pruned components, thereby developing a more powerful GLT, referred to as the ACE-GLT. The main idea is to mine valuable information from pruned edges/weights after each round of IMP, and employ the ACE technique to refine the GLT processing. Finally, experimental results demonstrate that our ACE-GLT outperforms existing methods for searching GLT in diverse tasks. Our code will be made publicly available.
Lookaround Optimizer: $k$ steps around, 1 step average
Jun 13, 2023Weight Average (WA) is an active research topic due to its simplicity in ensembling deep networks and the effectiveness in promoting generalization. Existing weight average approaches, however, are often carried out along only one training trajectory in a post-hoc manner (i.e., the weights are averaged after the entire training process is finished), which significantly degrades the diversity between networks and thus impairs the effectiveness in ensembling. In this paper, inspired by weight average, we propose Lookaround, a straightforward yet effective SGD-based optimizer leading to flatter minima with better generalization. Specifically, Lookaround iterates two steps during the whole training period: the around step and the average step. In each iteration, 1) the around step starts from a common point and trains multiple networks simultaneously, each on transformed data by a different data augmentation, and 2) the average step averages these trained networks to get the averaged network, which serves as the starting point for the next iteration. The around step improves the functionality diversity while the average step guarantees the weight locality of these networks during the whole training, which is essential for WA to work. We theoretically explain the superiority of Lookaround by convergence analysis, and make extensive experiments to evaluate Lookaround on popular benchmarks including CIFAR and ImageNet with both CNNs and ViTs, demonstrating clear superiority over state-of-the-arts. Our code is available at https://github.com/Ardcy/Lookaround.
Decentralized SGD and Average-direction SAM are Asymptotically Equivalent
Jun 12, 2023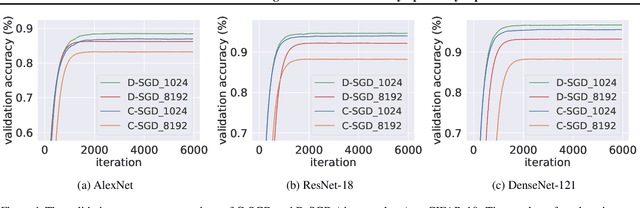
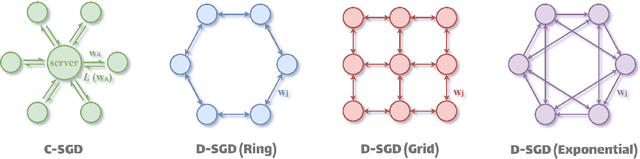
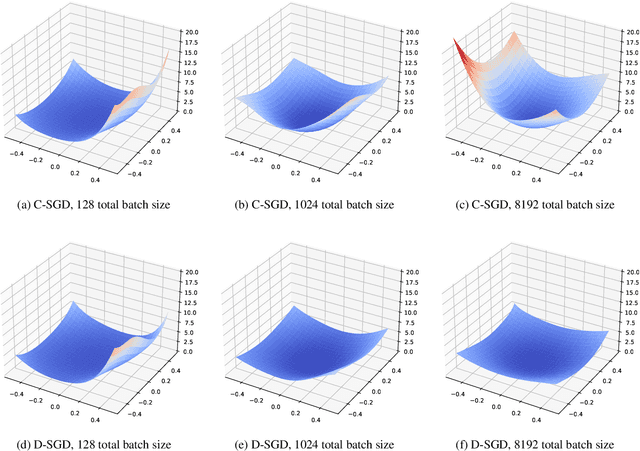
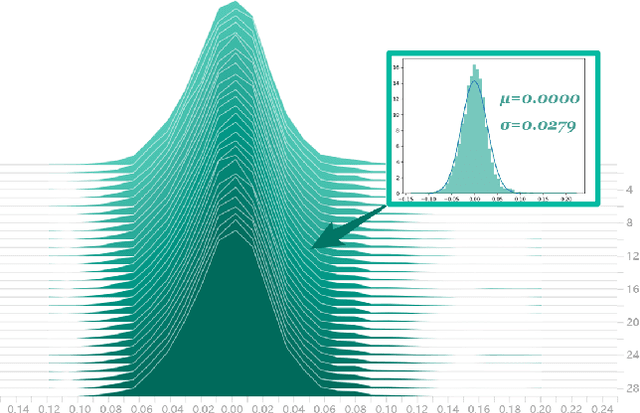
Decentralized stochastic gradient descent (D-SGD) allows collaborative learning on massive devices simultaneously without the control of a central server. However, existing theories claim that decentralization invariably undermines generalization. In this paper, we challenge the conventional belief and present a completely new perspective for understanding decentralized learning. We prove that D-SGD implicitly minimizes the loss function of an average-direction Sharpness-aware minimization (SAM) algorithm under general non-convex non-$\beta$-smooth settings. This surprising asymptotic equivalence reveals an intrinsic regularization-optimization trade-off and three advantages of decentralization: (1) there exists a free uncertainty evaluation mechanism in D-SGD to improve posterior estimation; (2) D-SGD exhibits a gradient smoothing effect; and (3) the sharpness regularization effect of D-SGD does not decrease as total batch size increases, which justifies the potential generalization benefit of D-SGD over centralized SGD (C-SGD) in large-batch scenarios.
Improving Expressivity of GNNs with Subgraph-specific Factor Embedded Normalization
Jun 11, 2023



Graph Neural Networks (GNNs) have emerged as a powerful category of learning architecture for handling graph-structured data. However, existing GNNs typically ignore crucial structural characteristics in node-induced subgraphs, which thus limits their expressiveness for various downstream tasks. In this paper, we strive to strengthen the representative capabilities of GNNs by devising a dedicated plug-and-play normalization scheme, termed as SUbgraph-sPEcific FactoR Embedded Normalization (SuperNorm), that explicitly considers the intra-connection information within each node-induced subgraph. To this end, we embed the subgraph-specific factor at the beginning and the end of the standard BatchNorm, as well as incorporate graph instance-specific statistics for improved distinguishable capabilities. In the meantime, we provide theoretical analysis to support that, with the elaborated SuperNorm, an arbitrary GNN is at least as powerful as the 1-WL test in distinguishing non-isomorphism graphs. Furthermore, the proposed SuperNorm scheme is also demonstrated to alleviate the over-smoothing phenomenon. Experimental results related to predictions of graph, node, and link properties on the eight popular datasets demonstrate the effectiveness of the proposed method. The code is available at https://github.com/chenchkx/SuperNorm.
Contrastive Identity-Aware Learning for Multi-Agent Value Decomposition
Nov 23, 2022



Value Decomposition (VD) aims to deduce the contributions of agents for decentralized policies in the presence of only global rewards, and has recently emerged as a powerful credit assignment paradigm for tackling cooperative Multi-Agent Reinforcement Learning (MARL) problems. One of the main challenges in VD is to promote diverse behaviors among agents, while existing methods directly encourage the diversity of learned agent networks with various strategies. However, we argue that these dedicated designs for agent networks are still limited by the indistinguishable VD network, leading to homogeneous agent behaviors and thus downgrading the cooperation capability. In this paper, we propose a novel Contrastive Identity-Aware learning (CIA) method, explicitly boosting the credit-level distinguishability of the VD network to break the bottleneck of multi-agent diversity. Specifically, our approach leverages contrastive learning to maximize the mutual information between the temporal credits and identity representations of different agents, encouraging the full expressiveness of credit assignment and further the emergence of individualities. The algorithm implementation of the proposed CIA module is simple yet effective that can be readily incorporated into various VD architectures. Experiments on the SMAC benchmarks and across different VD backbones demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code is available at https://github.com/liushunyu/CIA.
Topology-aware Generalization of Decentralized SGD
Jun 28, 2022

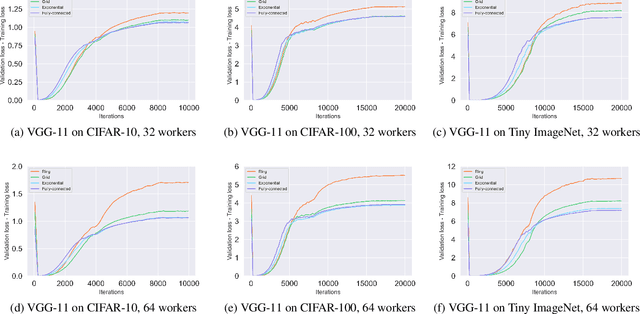
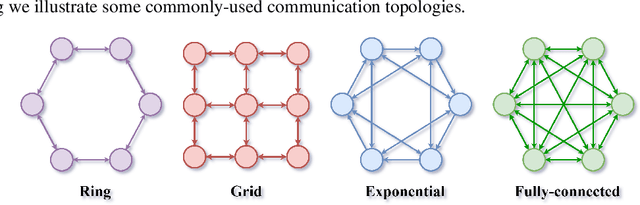
This paper studies the algorithmic stability and generalizability of decentralized stochastic gradient descent (D-SGD). We prove that the consensus model learned by D-SGD is $\mathcal{O}{(m/N+1/m+\lambda^2)}$-stable in expectation in the non-convex non-smooth setting, where $N$ is the total sample size of the whole system, $m$ is the worker number, and $1-\lambda$ is the spectral gap that measures the connectivity of the communication topology. These results then deliver an $\mathcal{O}{(1/N+{({(m^{-1}\lambda^2)}^{\frac{\alpha}{2}}+ m^{-\alpha})}/{N^{1-\frac{\alpha}{2}}})}$ in-average generalization bound, which is non-vacuous even when $\lambda$ is closed to $1$, in contrast to vacuous as suggested by existing literature on the projected version of D-SGD. Our theory indicates that the generalizability of D-SGD has a positive correlation with the spectral gap, and can explain why consensus control in initial training phase can ensure better generalization. Experiments of VGG-11 and ResNet-18 on CIFAR-10, CIFAR-100 and Tiny-ImageNet justify our theory. To our best knowledge, this is the first work on the topology-aware generalization of vanilla D-SGD. Code is available at https://github.com/Raiden-Zhu/Generalization-of-DSGD.