 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$D^3$-RSMDE: 40$\times$ Faster and High-Fidelity Remote Sensing Monocular Depth Estimation
Mar 17, 2026Real-time, high-fidelity monocular depth estimation from remote sensing imagery is crucial for numerous applications, yet existing methods face a stark trade-off between accuracy and efficiency. Although using Vision Transformer (ViT) backbones for dense prediction is fast, they often exhibit poor perceptual quality. Conversely, diffusion models offer high fidelity but at a prohibitive computational cost. To overcome these limitations, we propose Depth Detail Diffusion for Remote Sensing Monocular Depth Estimation ($D^3$-RSMDE), an efficient framework designed to achieve an optimal balance between speed and quality. Our framework first leverages a ViT-based module to rapidly generate a high-quality preliminary depth map construction, which serves as a structural prior, effectively replacing the time-consuming initial structure generation stage of diffusion models. Based on this prior, we propose a Progressive Linear Blending Refinement (PLBR) strategy, which uses a lightweight U-Net to refine the details in only a few iterations. The entire refinement step operates efficiently in a compact latent space supported by a Variational Autoencoder (VAE). Extensive experiments demonstrate that $D^3$-RSMDE achieves a notable 11.85% reduction in the Learned Perceptual Image Patch Similarity (LPIPS) perceptual metric over leading models like Marigold, while also achieving over a 40x speedup in inference and maintaining VRAM usage comparable to lightweight ViT models.
SpatCode: Rotary-based Unified Encoding Framework for Efficient Spatiotemporal Vector Retrieval
Jan 14, 2026Spatiotemporal vector retrieval has emerged as a critical paradigm in modern information retrieval, enabling efficient access to massive, heterogeneous data that evolve over both time and space. However, existing spatiotemporal retrieval methods are often extensions of conventional vector search systems that rely on external filters or specialized indices to incorporate temporal and spatial constraints, leading to inefficiency, architectural complexity, and limited flexibility in handling heterogeneous modalities. To overcome these challenges, we present a unified spatiotemporal vector retrieval framework that integrates temporal, spatial, and semantic cues within a coherent similarity space while maintaining scalability and adaptability to continuous data streams. Specifically, we propose (1) a Rotary-based Unified Encoding Method that embeds time and location into rotational position vectors for consistent spatiotemporal representation; (2) a Circular Incremental Update Mechanism that supports efficient sliding-window updates without global re-encoding or index reconstruction; and (3) a Weighted Interest-based Retrieval Algorithm that adaptively balances modality weights for context-aware and personalized retrieval. Extensive experiments across multiple real-world datasets demonstrate that our framework substantially outperforms state-of-the-art baselines in both retrieval accuracy and efficiency, while maintaining robustness under dynamic data evolution. These results highlight the effectiveness and practicality of the proposed approach for scalable spatiotemporal information retrieval in intelligent systems.
Reinforced Model Merging
Mar 27, 2025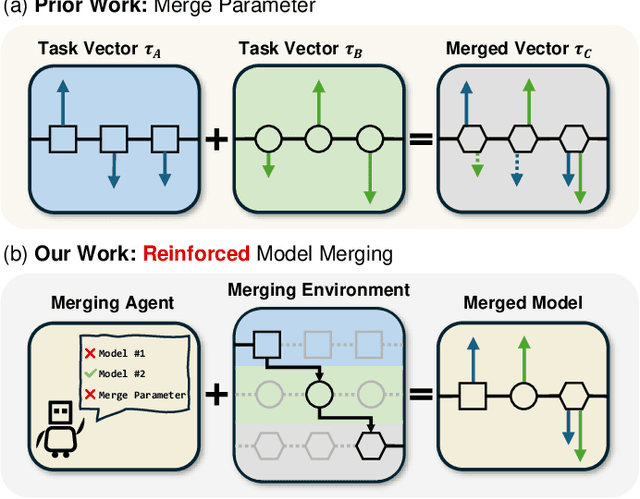
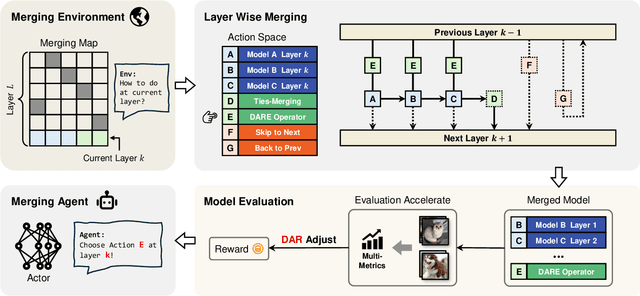
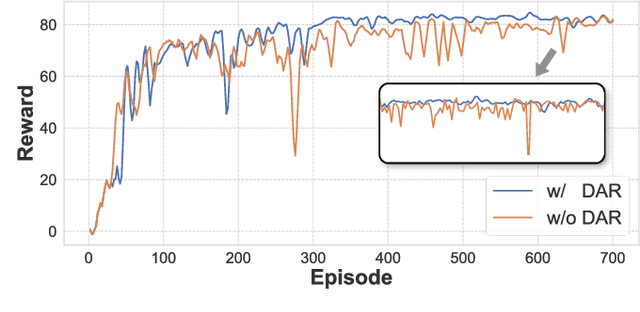
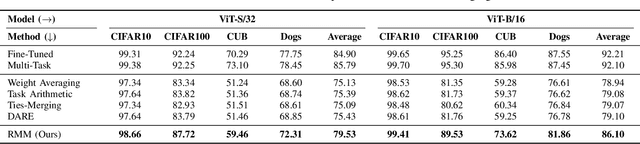
The success of large language models has garnered widespread attention for model merging techniques, especially training-free methods which combine model capabilities within the parameter space. However, two challenges remain: (1) uniform treatment of all parameters leads to performance degradation; (2) search-based algorithms are often inefficient. In this paper, we present an innovative framework termed Reinforced Model Merging (RMM), which encompasses an environment and agent tailored for merging tasks. These components interact to execute layer-wise merging actions, aiming to search the optimal merging architecture. Notably, RMM operates without any gradient computations on the original models, rendering it feasible for edge devices. Furthermore, by utilizing data subsets during the evaluation process, we addressed the bottleneck in the reward feedback phase, thereby accelerating RMM by up to 100 times. Extensive experiments demonstrate that RMM achieves state-of-the-art performance across various vision and NLP datasets and effectively overcomes the limitations of the existing baseline methods. Our code is available at https://github.com/WuDiHJQ/Reinforced-Model-Merging.
SHAPE : Self-Improved Visual Preference Alignment by Iteratively Generating Holistic Winner
Mar 06, 2025



Large Visual Language Models (LVLMs) increasingly rely on preference alignment to ensure reliability, which steers the model behavior via preference fine-tuning on preference data structured as ``image - winner text - loser text'' triplets. However, existing approaches often suffer from limited diversity and high costs associated with human-annotated preference data, hindering LVLMs from fully achieving their intended alignment capabilities. We present \projectname, a self-supervised framework capable of transforming the already abundant supervised text-image pairs into holistic preference triplets for more effective and cheaper LVLM alignment, eliminating the need for human preference annotations. Our approach facilitates LVLMs in progressively enhancing alignment capabilities through iterative self-improvement. The key design rationale is to devise preference triplets where the winner text consistently improves in holisticness and outperforms the loser response in quality, thereby pushing the model to ``strive to the utmost'' of alignment performance through preference fine-tuning. For each given text-image pair, SHAPE introduces multiple visual augmentations and pairs them with a summarized text to serve as the winner response, while designating the original text as the loser response. Experiments across \textbf{12} benchmarks on various model architectures and sizes, including LLaVA and DeepSeek-VL, show that SHAPE achieves significant gains, for example, achieving +11.3\% on MMVet (comprehensive evaluation), +1.4\% on MMBench (general VQA), and +8.0\% on POPE (hallucination robustness) over baselines in 7B models. Notably, qualitative analyses confirm enhanced attention to visual details and better alignment with human preferences for holistic descriptions.
SecPE: Secure Prompt Ensembling for Private and Robust Large Language Models
Feb 02, 2025



With the growing popularity of LLMs among the general public users, privacy-preserving and adversarial robustness have become two pressing demands for LLM-based services, which have largely been pursued separately but rarely jointly. In this paper, to the best of our knowledge, we are among the first attempts towards robust and private LLM inference by tightly integrating two disconnected fields: private inference and prompt ensembling. The former protects users' privacy by encrypting inference data transmitted and processed by LLMs, while the latter enhances adversarial robustness by yielding an aggregated output from multiple prompted LLM responses. Although widely recognized as effective individually, private inference for prompt ensembling together entails new challenges that render the naive combination of existing techniques inefficient. To overcome the hurdles, we propose SecPE, which designs efficient fully homomorphic encryption (FHE) counterparts for the core algorithmic building blocks of prompt ensembling. We conduct extensive experiments on 8 tasks to evaluate the accuracy, robustness, and efficiency of SecPE. The results show that SecPE maintains high clean accuracy and offers better robustness at the expense of merely $2.5\%$ efficiency overhead compared to baseline private inference methods, indicating a satisfactory ``accuracy-robustness-efficiency'' tradeoff. For the efficiency of the encrypted Argmax operation that incurs major slowdown for prompt ensembling, SecPE is 35.4x faster than the state-of-the-art peers, which can be of independent interest beyond this work.
Activation Approximations Can Incur Safety Vulnerabilities Even in Aligned LLMs: Comprehensive Analysis and Defense
Feb 02, 2025



Large Language Models (LLMs) have showcased remarkable capabilities across various domains. Accompanying the evolving capabilities and expanding deployment scenarios of LLMs, their deployment challenges escalate due to their sheer scale and the advanced yet complex activation designs prevalent in notable model series, such as Llama, Gemma, and Mistral. These challenges have become particularly pronounced in resource-constrained deployment scenarios, where mitigating inference efficiency bottlenecks is imperative. Among various recent efforts, activation approximation has emerged as a promising avenue for pursuing inference efficiency, sometimes considered indispensable in applications such as private inference. Despite achieving substantial speedups with minimal impact on utility, even appearing sound and practical for real-world deployment, the safety implications of activation approximations remain unclear. In this work, we fill this critical gap in LLM safety by conducting the first systematic safety evaluation of activation approximations. Our safety vetting spans seven sota techniques across three popular categories, revealing consistent safety degradation across ten safety-aligned LLMs.
SEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
Dec 14, 2024



Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
Efficient and Comprehensive Feature Extraction in Large Vision-Language Model for Clinical Pathology Analysis
Dec 12, 2024Pathological diagnosis is vital for determining disease characteristics, guiding treatment, and assessing prognosis, relying heavily on detailed, multi-scale analysis of high-resolution whole slide images (WSI). However, traditional pure vision models face challenges of redundant feature extraction, whereas existing large vision-language models (LVLMs) are limited by input resolution constraints, hindering their efficiency and accuracy. To overcome these issues, we propose two innovative strategies: the mixed task-guided feature enhancement, which directs feature extraction toward lesion-related details across scales, and the prompt-guided detail feature completion, which integrates coarse- and fine-grained features from WSI based on specific prompts without compromising inference speed. Leveraging a comprehensive dataset of 490,000 samples from diverse pathology tasks-including cancer detection, grading, vascular and neural invasion identification, and so on-we trained the pathology-specialized LVLM, OmniPath. Extensive experiments demonstrate that this model significantly outperforms existing methods in diagnostic accuracy and efficiency, offering an interactive, clinically aligned approach for auxiliary diagnosis in a wide range of pathology applications.
Deep Feature Response Discriminative Calibration
Nov 16, 2024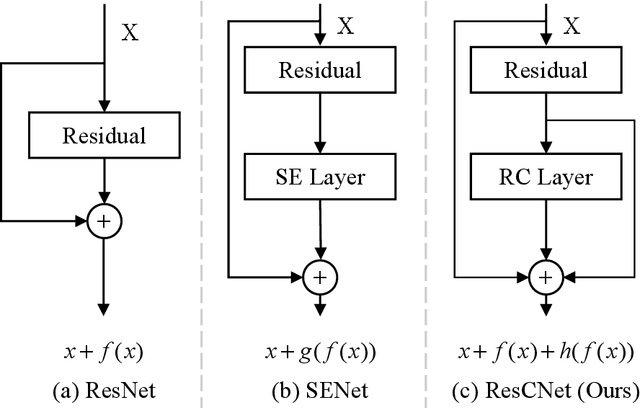
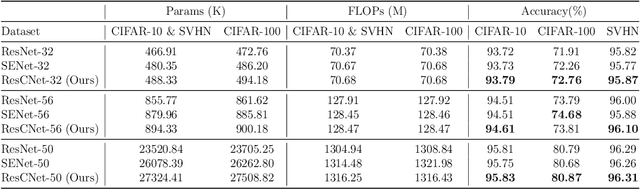
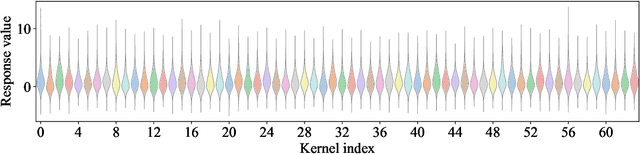
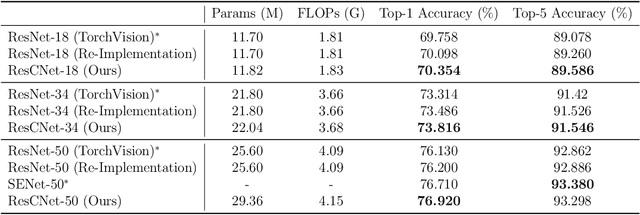
Deep neural networks (DNNs) have numerous applications across various domains. Several optimization techniques, such as ResNet and SENet, have been proposed to improve model accuracy. These techniques improve the model performance by adjusting or calibrating feature responses according to a uniform standard. However, they lack the discriminative calibration for different features, thereby introducing limitations in the model output. Therefore, we propose a method that discriminatively calibrates feature responses. The preliminary experimental results indicate that the neural feature response follows a Gaussian distribution. Consequently, we compute confidence values by employing the Gaussian probability density function, and then integrate these values with the original response values. The objective of this integration is to improve the feature discriminability of the neural feature response. Based on the calibration values, we propose a plugin-based calibration module incorporated into a modified ResNet architecture, termed Response Calibration Networks (ResCNet). Extensive experiments on datasets like CIFAR-10, CIFAR-100, SVHN, and ImageNet demonstrate the effectiveness of the proposed approach. The developed code is publicly available at https://github.com/tcmyxc/ResCNet.
Fire and Smoke Detection with Burning Intensity Representation
Oct 22, 2024



An effective Fire and Smoke Detection (FSD) and analysis system is of paramount importance due to the destructive potential of fire disasters. However, many existing FSD methods directly employ generic object detection techniques without considering the transparency of fire and smoke, which leads to imprecise localization and reduces detection performance. To address this issue, a new Attentive Fire and Smoke Detection Model (a-FSDM) is proposed. This model not only retains the robust feature extraction and fusion capabilities of conventional detection algorithms but also redesigns the detection head specifically for transparent targets in FSD, termed the Attentive Transparency Detection Head (ATDH). In addition, Burning Intensity (BI) is introduced as a pivotal feature for fire-related downstream risk assessments in traditional FSD methodologies. Extensive experiments on multiple FSD datasets showcase the effectiveness and versatility of the proposed FSD model. The project is available at \href{https://xiaoyihan6.github.io/FSD/}{https://xiaoyihan6.github.io/FSD/}.