 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Similarity: Trustworthy Memory Search for Personal AI Agents
Jun 04, 2026Personal AI agents increasingly rely on long-term memory to provide persistent personalization across sessions. However, existing memory pipelines are largely driven by semantic similarity: memory data close to the current query is retrieved and injected into the model context. This creates a critical trustworthiness gap, since a semantically related memory may still be contextually inappropriate, leading to threats such as cross-domain leakage, sycophancy, tool-call drift, or memory-induced jailbreaks. In this paper, we study memory search as a trust boundary in personal AI agents. We evaluate representative agentic memory frameworks, including A-Mem, Mem0, and MemOS, together with OpenClaw, a real-world personal-agent environment with persistent state and tool-use capability. Our results show that long-term memory is not merely a utility layer, but a durable control channel that can reshape how agents interpret tasks and execute actions, leaving them highly susceptible to the aforementioned threats. To mitigate these vulnerabilities, we propose MemGate, a lightweight and deployable memory plug-in for trustworthy memory search, with only 9M parameters and a 35.1MB footprint. MemGate is inserted between the vector memory store and the backbone LLM, requiring no LLM modification, memory-database rewriting, or inference-time LLM judge. It applies a query-conditioned neural gate to candidate memory representations, turning raw similarity search into task-conditioned memory admission. Across multiple mainstream memory frameworks, real-world agent settings, and diverse LLM backbones, MemGate reduces memory-induced threats while preserving long-term memory utility.
Understanding and Preserving Safety in Fine-Tuned LLMs
Jan 15, 2026Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.
Safety at One Shot: Patching Fine-Tuned LLMs with A Single Instance
Jan 06, 2026Fine-tuning safety-aligned large language models (LLMs) can substantially compromise their safety. Previous approaches require many safety samples or calibration sets, which not only incur significant computational overhead during realignment but also lead to noticeable degradation in model utility. Contrary to this belief, we show that safety alignment can be fully recovered with only a single safety example, without sacrificing utility and at minimal cost. Remarkably, this recovery is effective regardless of the number of harmful examples used in fine-tuning or the size of the underlying model, and convergence is achieved within just a few epochs. Furthermore, we uncover the low-rank structure of the safety gradient, which explains why such efficient correction is possible. We validate our findings across five safety-aligned LLMs and multiple datasets, demonstrating the generality of our approach.
Learning to Align Human Code Preferences
Jul 27, 2025Large Language Models (LLMs) have demonstrated remarkable potential in automating software development tasks. While recent advances leverage Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to align models with human preferences, the optimal training strategy remains unclear across diverse code preference scenarios. This paper systematically investigates the roles of SFT and DPO in aligning LLMs with different code preferences. Through both theoretical analysis and empirical observation, we hypothesize that SFT excels in scenarios with objectively verifiable optimal solutions, while applying SFT followed by DPO (S&D) enables models to explore superior solutions in scenarios without objectively verifiable optimal solutions. Based on the analysis and experimental evidence, we propose Adaptive Preference Optimization (APO), a dynamic integration approach that adaptively amplifies preferred responses, suppresses dispreferred ones, and encourages exploration of potentially superior solutions during training. Extensive experiments across six representative code preference tasks validate our theoretical hypotheses and demonstrate that APO consistently matches or surpasses the performance of existing SFT and S&D strategies. Our work provides both theoretical foundations and practical guidance for selecting appropriate training strategies in different code preference alignment scenarios.
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025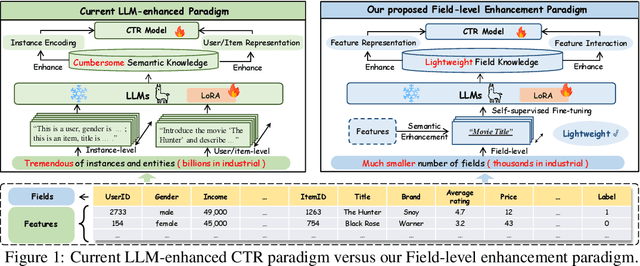
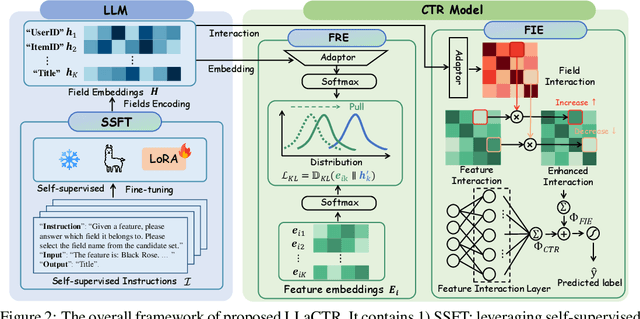
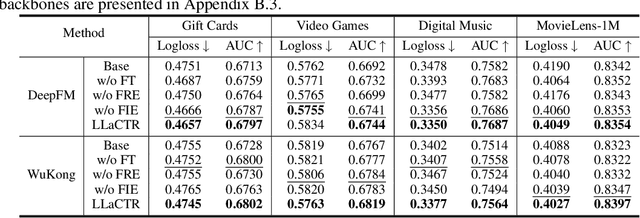

Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
Zero-Shot Cross-Domain Code Search without Fine-Tuning
Apr 10, 2025



Code search aims to retrieve semantically relevant code snippets for natural language queries. While pre-trained language models (PLMs) have shown remarkable performance in this task, they struggle in cross-domain scenarios, often requiring costly fine-tuning or facing performance drops in zero-shot settings. RAPID, which generates synthetic data for model fine-tuning, is currently the only effective method for zero-shot cross-domain code search. Despite its effectiveness, RAPID demands substantial computational resources for fine-tuning and needs to maintain specialized models for each domain, underscoring the need for a zero-shot, fine-tuning-free approach for cross-domain code search. The key to tackling zero-shot cross-domain code search lies in bridging the gaps among domains. In this work, we propose to break the query-code matching process of code search into two simpler tasks: query-comment matching and code-code matching. Our empirical study reveals the strong complementarity among the three matching schemas in zero-shot cross-domain settings, i.e., query-code, query-comment, and code-code matching. Based on the findings, we propose CodeBridge, a zero-shot, fine-tuning-free approach for cross-domain code search. Specifically, CodeBridge uses Large Language Models (LLMs) to generate comments and pseudo-code, then combines query-code, query-comment, and code-code matching via PLM-based similarity scoring and sampling-based fusion. Experimental results show that our approach outperforms the state-of-the-art PLM-based code search approaches, i.e., CoCoSoDa and UniXcoder, by an average of 21.4% and 24.9% in MRR, respectively, across three datasets. Our approach also yields results that are better than or comparable to those of the zero-shot cross-domain code search approach RAPID, which requires costly fine-tuning.
SecPE: Secure Prompt Ensembling for Private and Robust Large Language Models
Feb 02, 2025



With the growing popularity of LLMs among the general public users, privacy-preserving and adversarial robustness have become two pressing demands for LLM-based services, which have largely been pursued separately but rarely jointly. In this paper, to the best of our knowledge, we are among the first attempts towards robust and private LLM inference by tightly integrating two disconnected fields: private inference and prompt ensembling. The former protects users' privacy by encrypting inference data transmitted and processed by LLMs, while the latter enhances adversarial robustness by yielding an aggregated output from multiple prompted LLM responses. Although widely recognized as effective individually, private inference for prompt ensembling together entails new challenges that render the naive combination of existing techniques inefficient. To overcome the hurdles, we propose SecPE, which designs efficient fully homomorphic encryption (FHE) counterparts for the core algorithmic building blocks of prompt ensembling. We conduct extensive experiments on 8 tasks to evaluate the accuracy, robustness, and efficiency of SecPE. The results show that SecPE maintains high clean accuracy and offers better robustness at the expense of merely $2.5\%$ efficiency overhead compared to baseline private inference methods, indicating a satisfactory ``accuracy-robustness-efficiency'' tradeoff. For the efficiency of the encrypted Argmax operation that incurs major slowdown for prompt ensembling, SecPE is 35.4x faster than the state-of-the-art peers, which can be of independent interest beyond this work.
Activation Approximations Can Incur Safety Vulnerabilities Even in Aligned LLMs: Comprehensive Analysis and Defense
Feb 02, 2025



Large Language Models (LLMs) have showcased remarkable capabilities across various domains. Accompanying the evolving capabilities and expanding deployment scenarios of LLMs, their deployment challenges escalate due to their sheer scale and the advanced yet complex activation designs prevalent in notable model series, such as Llama, Gemma, and Mistral. These challenges have become particularly pronounced in resource-constrained deployment scenarios, where mitigating inference efficiency bottlenecks is imperative. Among various recent efforts, activation approximation has emerged as a promising avenue for pursuing inference efficiency, sometimes considered indispensable in applications such as private inference. Despite achieving substantial speedups with minimal impact on utility, even appearing sound and practical for real-world deployment, the safety implications of activation approximations remain unclear. In this work, we fill this critical gap in LLM safety by conducting the first systematic safety evaluation of activation approximations. Our safety vetting spans seven sota techniques across three popular categories, revealing consistent safety degradation across ten safety-aligned LLMs.
Rectifier: Code Translation with Corrector via LLMs
Jul 10, 2024Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
Enhancing Repository-Level Code Generation with Integrated Contextual Information
Jun 05, 2024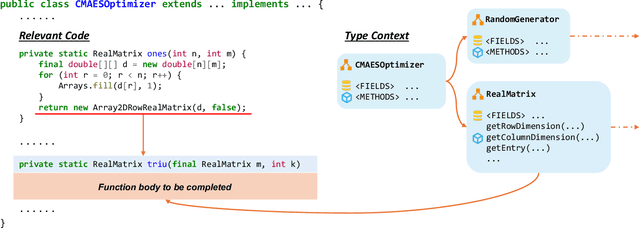

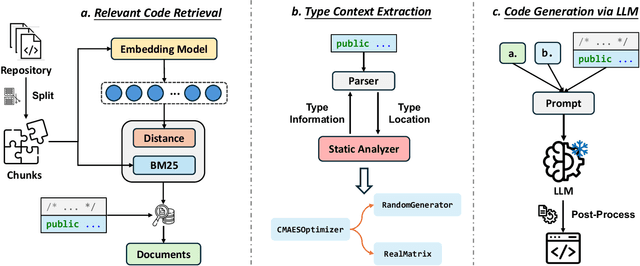

Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, repository-level code generation presents unique challenges, particularly due to the need to utilize information spread across multiple files within a repository. Existing retrieval-based approaches sometimes fall short as they are limited in obtaining a broader and deeper repository context. In this paper, we present CatCoder, a novel code generation framework designed for statically typed programming languages. CatCoder enhances repository-level code generation by integrating relevant code and type context. Specifically, it leverages static analyzers to extract type dependencies and merges this information with retrieved code to create comprehensive prompts for LLMs. To evaluate the effectiveness of CatCoder, we adapt and construct benchmarks that include 199 Java tasks and 90 Rust tasks. The results show that CatCoder outperforms the RepoCoder baseline by up to 17.35%, in terms of pass@k score. Furthermore, the generalizability of CatCoder is assessed using various LLMs, including both code-specialized models and general-purpose models. Our findings indicate consistent performance improvements across all models, which underlines the practicality of CatCoder.